Hi All,
I am trying to use spark Predictor Regression node for a simple prediction exercise. In scenario 1 I am using the same spark context for training my data and testing my data using the spark predictor node. And the prediction node runs successfully. In this case I first train the model store the trained model to S3 storage and use the trained model to do Testing/prediction exercise without resetting the spark context .
please refer to image below.
However in Scenario 2: I am resetting the spark context and trying to only perform prediction/Testing exercise this time. (Note : I am using the model I already trained in scenario 1 and stored on S3 storage) . However this time it prediction node does not run successfully for the same data set. It is coming up with "Execute failed Empty collection (Unsupported operationException)
please refer to image below.
Could some one help me the possible reasoning for why this is happening/how could I resolve this.
Note : I have checked that the training and testing data set follow the same format. (Just to rule out one possible situation for prediction to possibly not work)
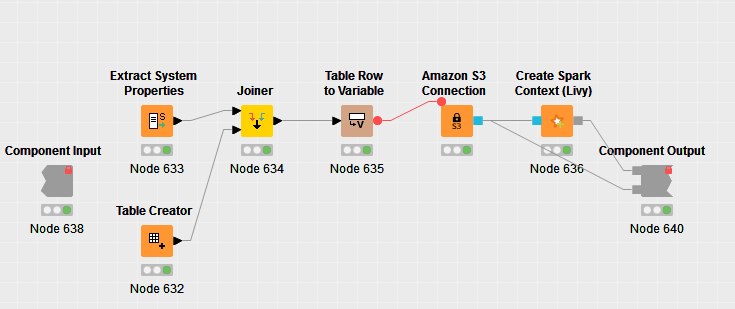
Also attaching below a screenshot of my create spark context component I have created using native knime nodes.
@oshin these are my thoughts on this. From my experience the ML Spark implementation depending on the Spark version is notoriously unreliable and will fail for any number of reasons. Especially with Spark versions older or up to 2.3. I cannot speak to later versions with any authority.
Then: Spark ML models often only ‘like’ double values (aside from a possible binary or multi-class target) despite what nodes or some ‘automatic’ stuff is telling you. That also seems to be true unfortunately for some PMML conversions string to number and other stuff in KNIME (the storage and apply can be tricky). So you might want to look your for some robust conversion methods.
Also missing values and NaA and stuff are not welcome with Spark ML models. So make sure you clean your data accordingly.
One method that I discussed in a recent talk is some self-made label encoding. Which might not be for every task but can be quite robust. Terms and conditions do apply.
Then you might want to explore the world of H2O.ai nodes and models KNIME is offering. They in general seem to be more robust. A simple example how to use them is found here: