Hello,
i got the following problem.
The table i am trying to split contains a list of all our products (1 in each row). The product-string varies in lenght, depending on how deep the product lies in the taxonomy.
I want to extract the product ID, which is in all cases the last number in the string.
Example of 2 rows:
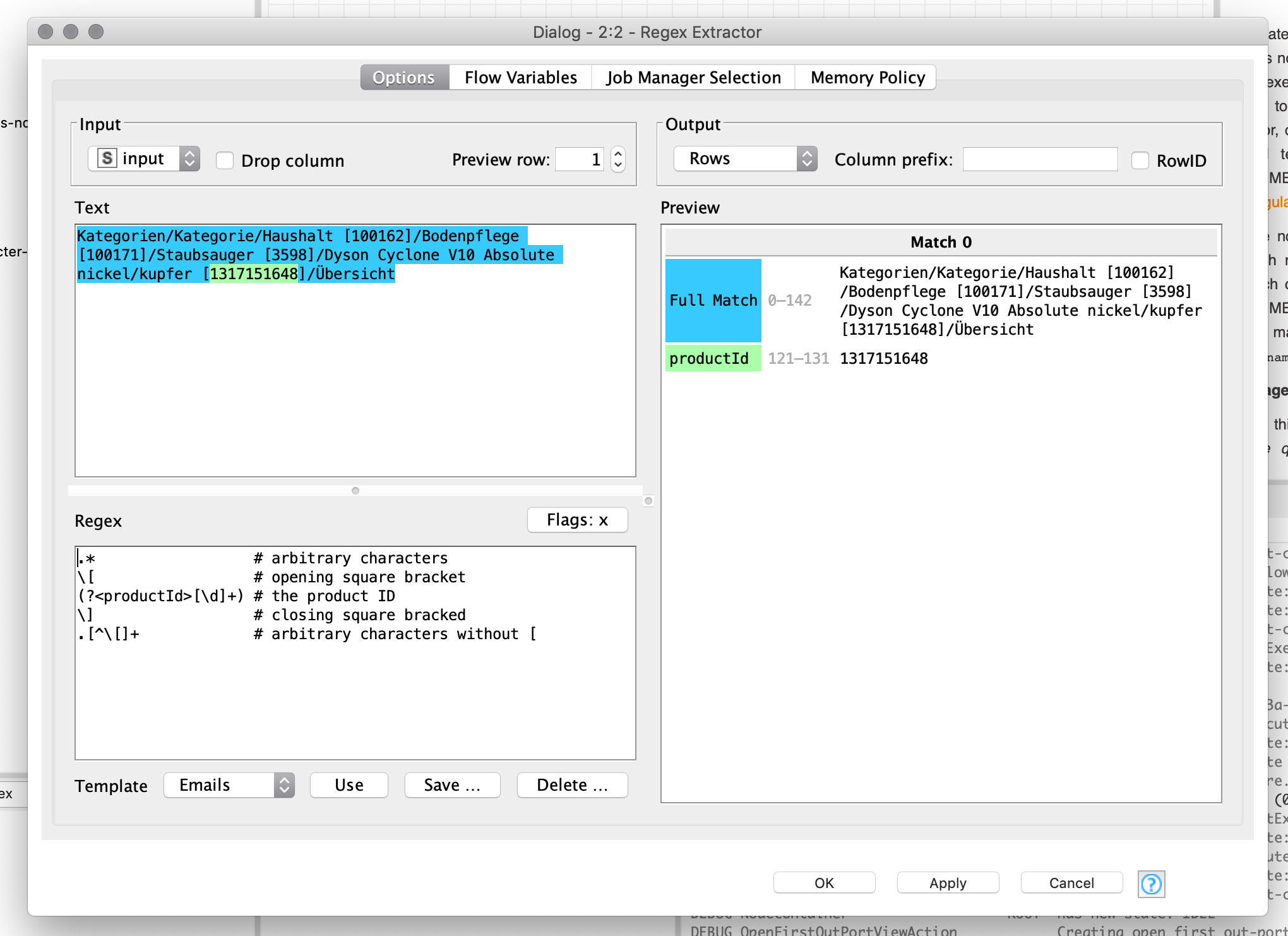
Kategorien/Kategorie/Haushalt [100162]/Bodenpflege [100171]/Staubsauger [3598]/Dyson Cyclone V10 Absolute nickel/kupfer [1317151648]/Übersicht
So i tried to split the column at “[” on the furthest right with the Node “Regex Split”. As i’m not good with regex, i didn’t even come close to a solution…
I would be greatful for any ideas how to solve this.
@solute_ok, you can use String Manipulation node with combination of functions function indexOf(, , “b”) and substr() or Column Expression node with the same functions.
In addition to the solution already provided by @izaychik63, you can use this regex in the Regex Extractor node from Palladian 2 or the regexReplace() function in the String Manipulation node:
Regex Extractor: \d+(?!.*\d+)
or to be more precise: (?<=\[)\d+(?=\])(?!.*\[\d+\])