@TSL4000 welcome to the KNIME Forum. I thought this would be a fun task for KNIME’s LLM nodes and Ollama/Llama3.2. The result after some tweaking of the input and the prompt can look like this:
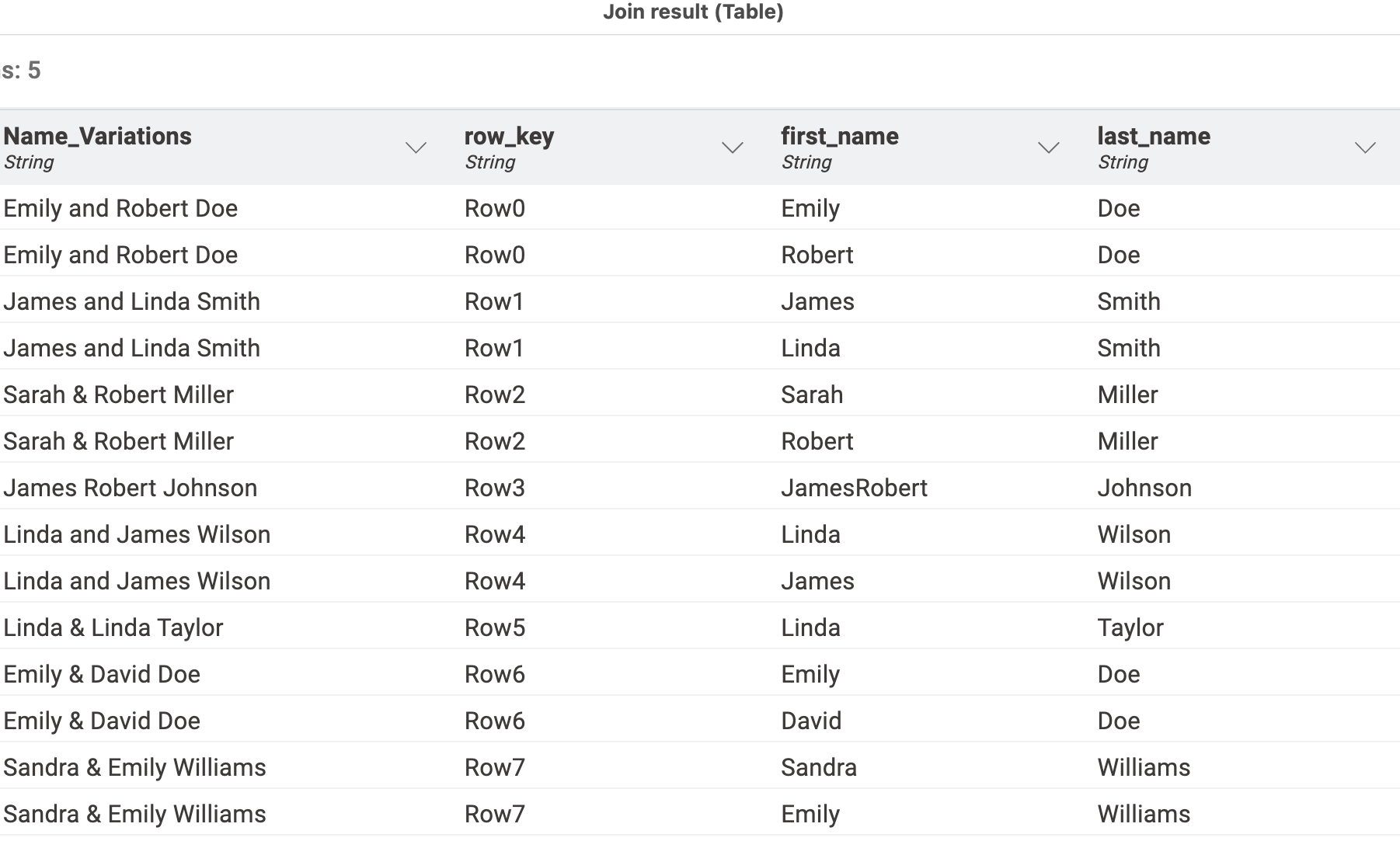
Some lines have not been fully covered … mainly where there are several names but no and or ampersand. One might have to amend the prompt to cover such cases but first:
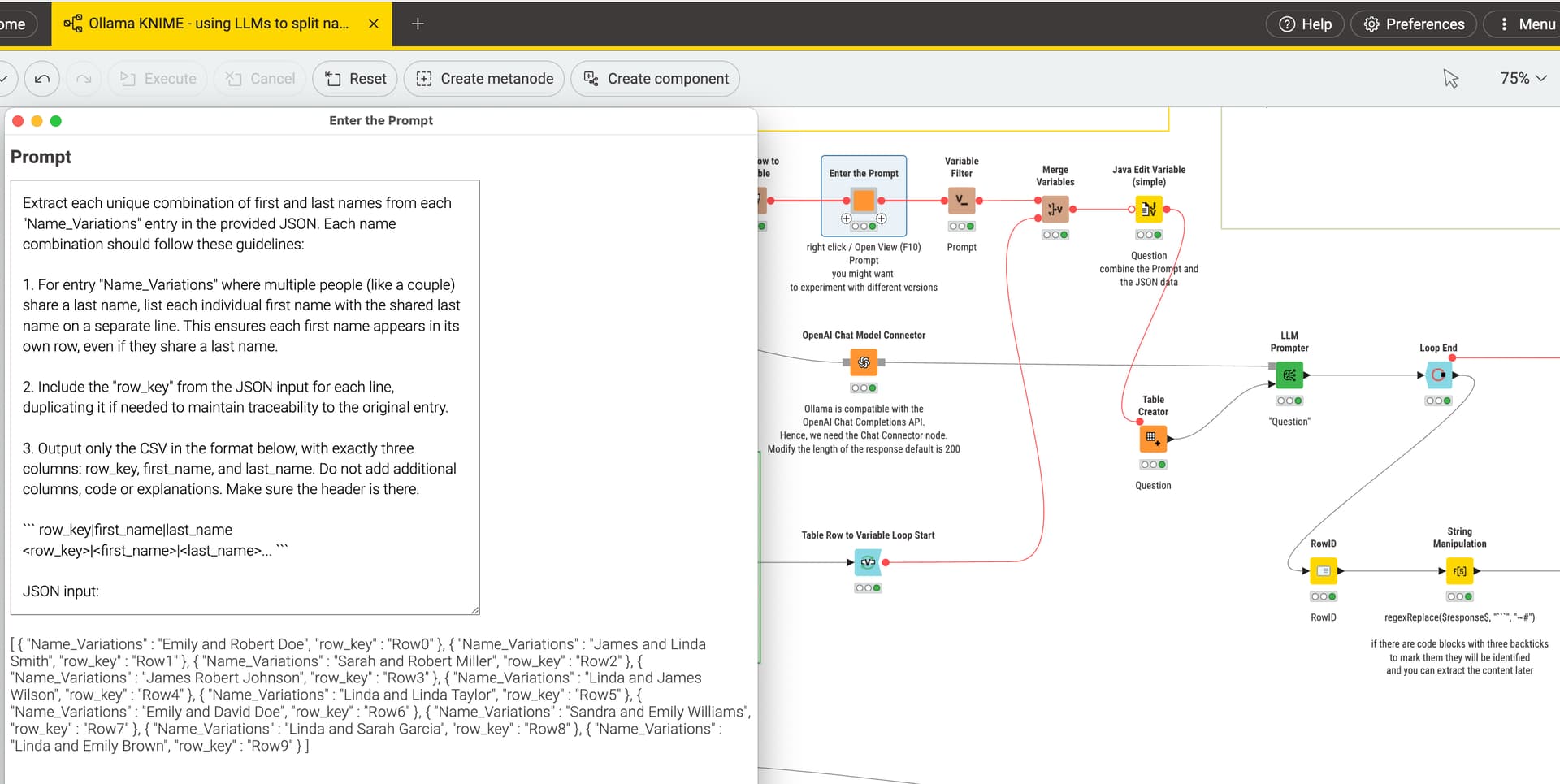
What is happening is that the original content gets converted in a JSOn structure in chunks of 10 and this JSON then gets fed into a local LLM that is Llama3.2 with the task of extracting the first and last name and putting that into a specific CSV structure.
The resulting CSV structures can then be extracted and put together with the original RowIDs so as to see how good the result was.
The benefit of using JSON while prompting is that is seemingly helps the LLM to identify the columns and then come back with a fixed structure (in this case CSV but could also be JSON).
You might says this approach is heavily over-engineered and you might not be wrong with that but I wanted to also demonstrate an approach how to systematically handle other semi-structured data where you have some sort of logic but which might not be that easy to be extracted by traditional data cleaning techniques.
The most effort was necessary to get the prompt right to tell Llama3.2 what to do with the names and to actually split them into (if necessary) several lines. You could also use ChatGPT or other LLMs for that.
Also it might be that this approach is suited for English Names and might not immediately work for other sets of names.
But I think this approach might help for other task too and is reasonably fast on an Apple Silicon machine:
- have semi-structured data or text chunks
- put them in chunks into JSON structure that keeps some meta information that can be addressed in a prompt
- create a prompt and combine it with these JSONs in loops to process it
- extract the resulting structure
Maybe you give it a try