Hi @trafalgarlaw , thank you for the updated information. Yes the rule governing the difference between UNIQUE and UNMATCHED was what I was looking for.
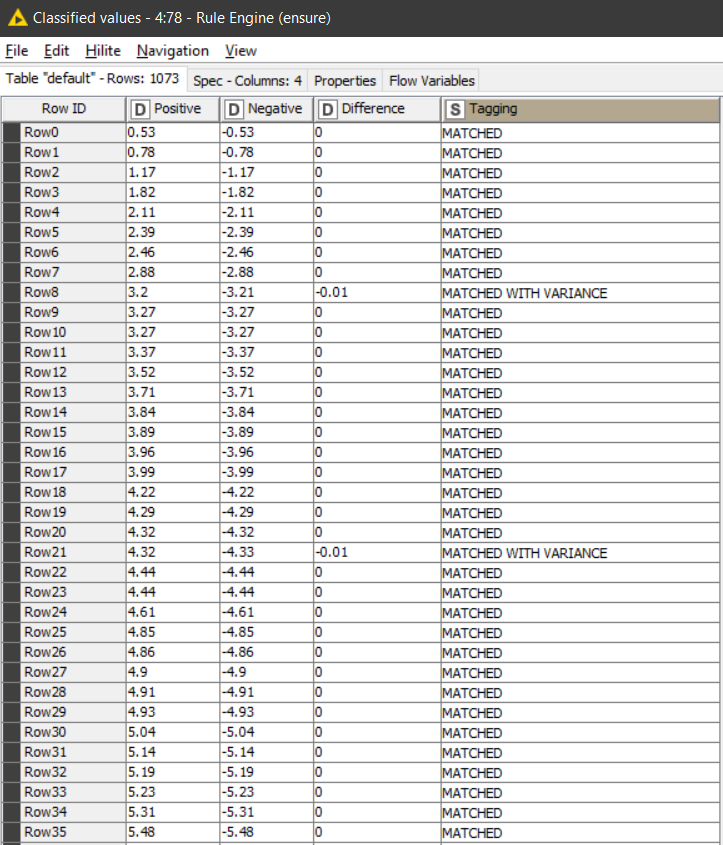
I would question the .03 difference being the cutoff because your previous examples have UNMATCHED pairs with a difference of .04 (2.0 and -2.04) and .05 (82.0 and -82.05) so with this new rule we can never achieve your previous expected results, but to my mind that is now just a threshold number that can be adjusted. The main thing is that it forms the basis for a rule.
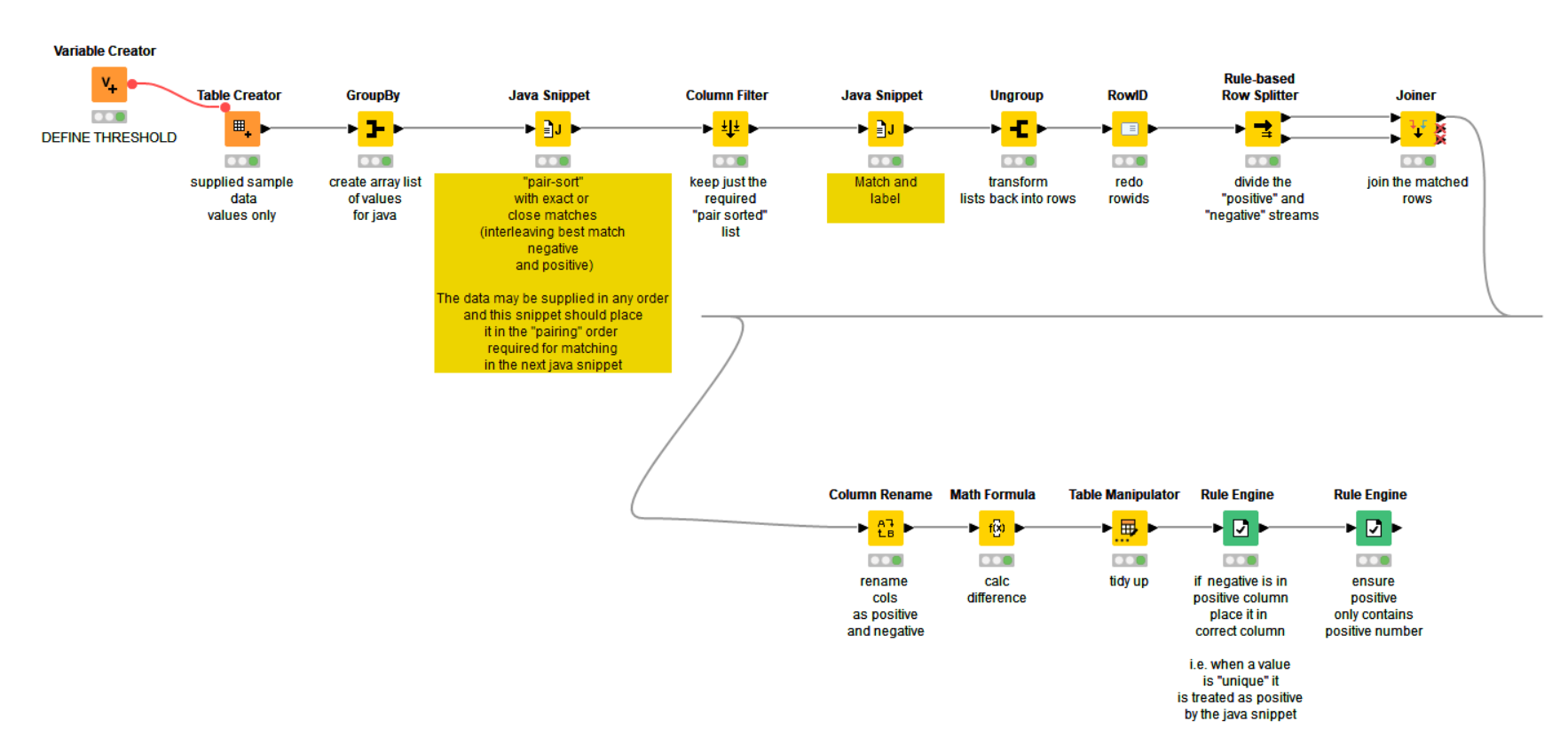
So, if I may now state what I believe to be your problem definition:
You have a list of numbers in no particular order.
Some may be positive and some may be negative.
Numbers may be repeated.
The members in this list need to be compared.
I’ll sometimes use the term “members” rather than “numbers” because it better signifies a specific instance of a given number in the list.
Where two members of the list sum to zero, the pair should be labeled “MATCHED” and take no further part in the comparisons.(edge case: it isn’t clear how to treat a pair of zeros. Are they special? I’ll assume they aren’t)
Of the remaining members if the difference between a pair of members is less than or equal to the threshold value (0.03), these will be labelled “UNMATCHED” and take no further part in the comparisons.
The members that remain are labeled “UNIQUE”.
No one member of the list of numbers may be considered matched or unmatched to more than one other member. Once it has been paired in this way it may not be paired with any other member. So the list 1, 2, -1, -1.01, -2, -2 would result in 1 and -1 being matched; thus -1.01 is unique, whilst one of the -2s would match the 2 leaving a lone unique -2.
What is potentially undefined is any order of precedence to unmatched values. Given the numbers 1.0, -1.01, -1.015 , 1.02 there could be two combinations of pairings since either positive could pair to either negative. The original post though would see these listed in ascending magnitude order 1.0, -1.01, -1.015, 1.02 and then pairings performed based on that ordering which would see the pairings 1.0 with -1.01 and then 1.02 with -1.015.
I think I can visualise how the above could be achieved, but I’m not currently at my pc. It would be good if you could confirm my understanding