Hi @lsandinop
I’m not aware of a similar node to the -Term Neighborhood Extractor- node which could do the same job with the constrain you are mentioning, i. e. only extracts the neighbourhoods of specific terms.
I do not think that implementing this by hand (which it is possible in KNIME using for instance the -Lag Column- node) would be more efficient. I’m not hence suggesting here this possible solution because it will not be of much help.
However, I have tried the -Term Neighborhood Extractor- node and noticed that it doesn’t take advantage of several CPUs to achieve its task, it doesn’t work in multitask mode. Given this and if your text is made of several sentences, I would suggest to split it into sentences or at least big chunks of text, as many as cores (or threads) your computer may have and then run in parallel as many -Term Neighborhood Extractor- nodes as CPU threads you can have. For instance, if your computer can have up to 4 threads, then you could parallelize the Term Neighborhood Extraction as follows:
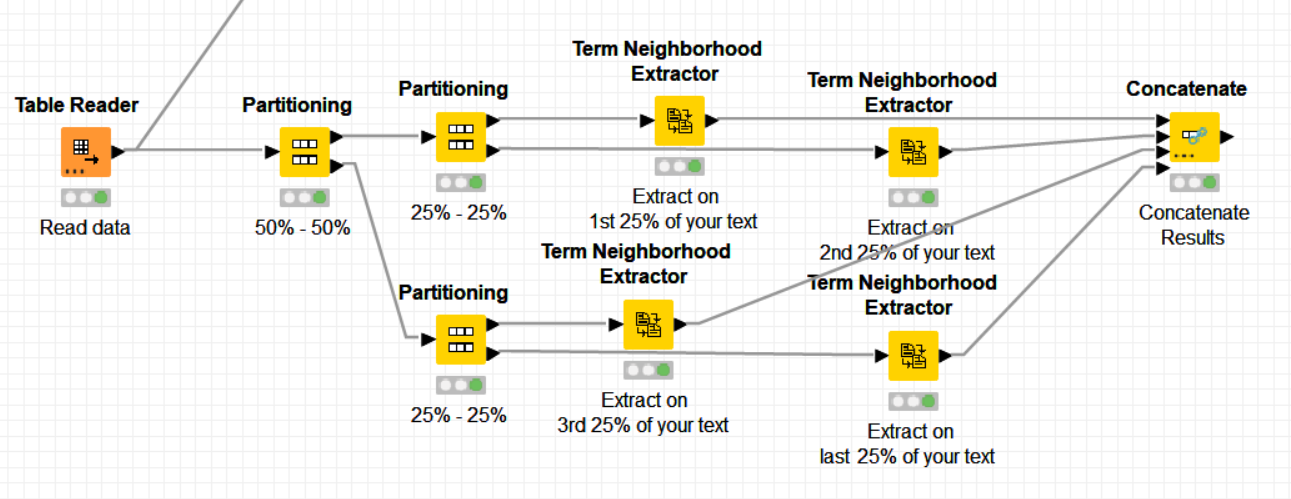
In this example, the Term Neighborhood Extraction is done in parallel by 4 extraction nodes and hence 4 times faster than doing it all only based on one -Term Neighborhood Extraction- node. You can adapt this solution to your own number of CPU threads to take the maximum advantage of them.
Hope this is clear enough and helps. Otherwise, please reach out again for extra help.
Best
Ael