I’ve been working with Python and would like to switch over to Knime for more rapid development and testing. One of the key items I’d like to use it for is text analysis with data tables that have multiple input feature types. For example, there is a description, an account number, a dollar amount, etc… Any of these features may provide some insight to a classification or categorization problem I have. A good example can be found here:
I hope you are doing well. I have been dabbling in the Enterprise Miner application and was wondering if it was able to do some classification work that will likely require mixed input features such as text, dollar amounts, account codes, etc… In Python, I can do it using something similar to the following article:
Hi @UtilityHawk,
KNIME does support calcification modeling with varied data types as you describe.
For starters tree based algorithms are included, but also one-hot encoding and document vectorization are possible. The later through the KNIME text processing extension (free to download).
After that you’d be able to use your one-hot encoded and numeric data in regressions(numeric or logistic), keras / tensorflow networks etc.
In particular you may find the One to Many node interesting. If you can help me understand more specifically what you’d like to be able to do I can help point you in a more specific direction. https://kni.me/n/IbXHdKHlLVT7F-h1
One example that I would be interested in is in the link I provided. The only difference would be that I want the category to be the target value where I can use the brand, price, item description, etc… to predict an item category. This would involve building the description tfidf and then joining that to the table to bring in brand, price, etc… features as well. The theory being that based on key words in the description and maybe the brand, I can designate an item as a Men’s Top vs. Women’s Top.
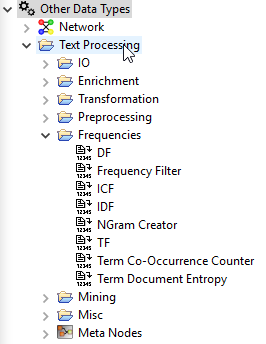
So you can handle document data, terms, frequencies etc with the text processing extension I mentioned.
You can calculate term frequencies, document frequencies, co-occurences, n-grams, etc as well as handle some preprocessing like stemming or punctuation erasure.
Term tagging is also available through a few different nodes (PoS, Stanford, or a custom dictionary for example) if you’re interested in that.
Above is a bit of a random example on how you might go about combining text, categorical, and numeric data in preparation for modeling with KNIME. Of course there’d be a bit more to it in a real case, but this should show a bit of what’s possible.
P.S. Once you have the Text processing extension you can find the nodes under Other Data Types > Text Processing.
Thank you for the example. This helps a lot. I’ll see if I can get this working on my data. I’ve worked with a different tool that does some clustering of the text terms and various N-Grams (SVD to reduce dimensionality and then cluster). That may be another option for me to try. That looks to be a little more involved with Knime and I do not see a SVD node, however, I may try to do PCA or try getting the R node to do the SVD for me and then figure out the multiple n-gram options. Thank you again.
Those all sound like good things to explore to me.
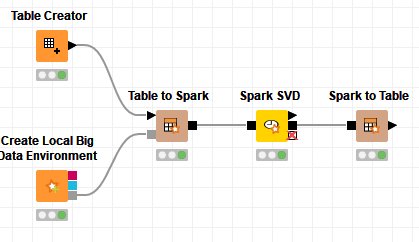
I will note that there is an SVD node, but its buried in the big data extension. It’s implemented in spark.
That just means to use it you’d have to first send your data to a spark framework and back to use it.
That could look like this: