i’ve spend the last 6 months developing a workflow for predicting patient no-shows for a clinic in Denmark with pretty good success. I’ve now encountered an explaination issue with my results to a doctor who sees everything from a diagnostics point of view.
After looking at my results and converting them into a 2x2 tabel for truepositive he is wondering what happened to 50 % of the test-data which I’m arguing is used by the algorithm on two the two scenarios, which he doesn’t understand.
Are you sure that all of the 488 records of your test dataset are passed into the predictor and scorer node?
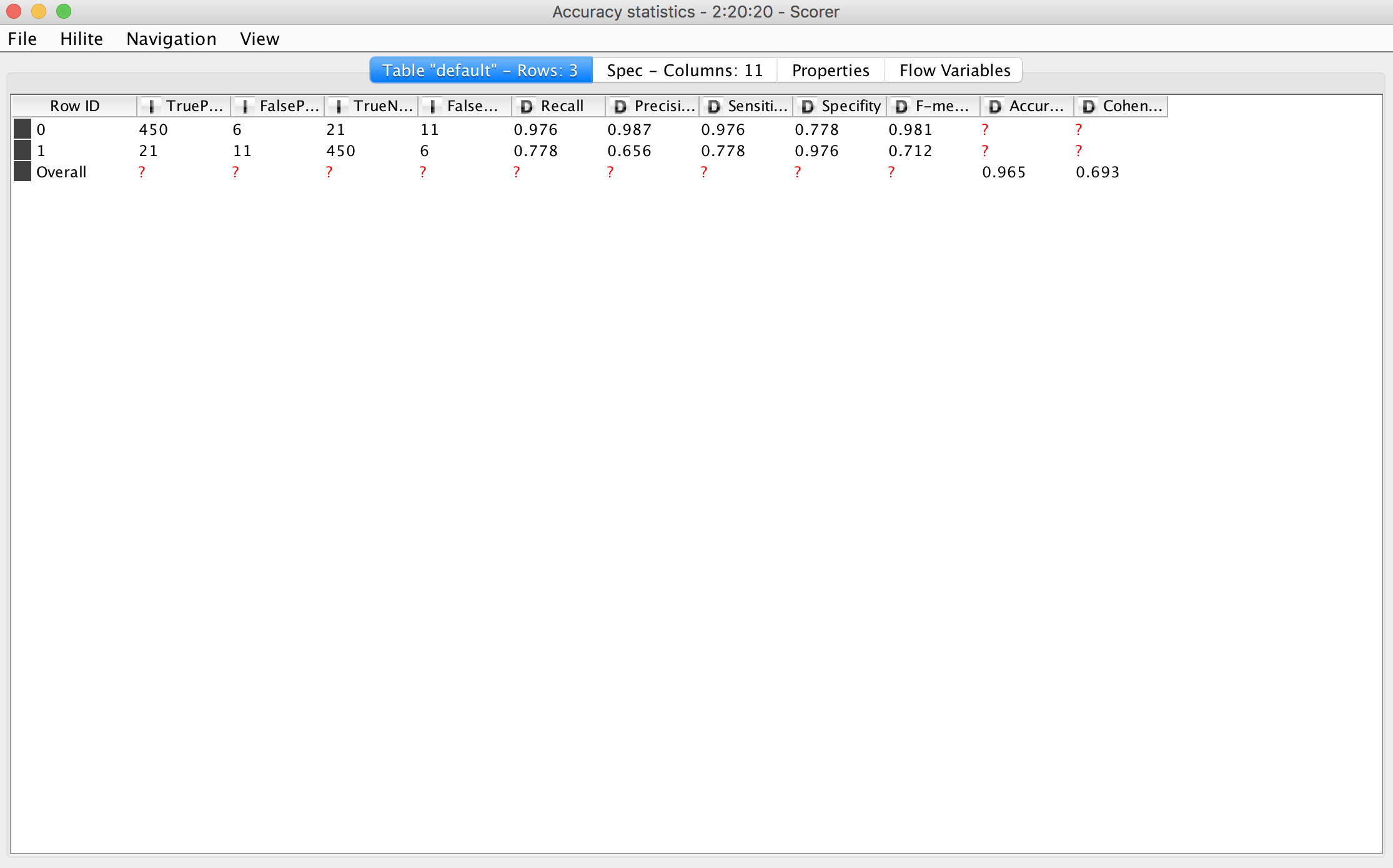
The accuracy statistics table of the scorer node gives you TP/FP/TN/FN for ALL the obvervations with respect to the class (class membership information is stored in the Row ID column). That is why I doubt that 100% of your testdata is processed in the Scorer node.
By the way, this is a super cool usecase. I would love to learn more about it.
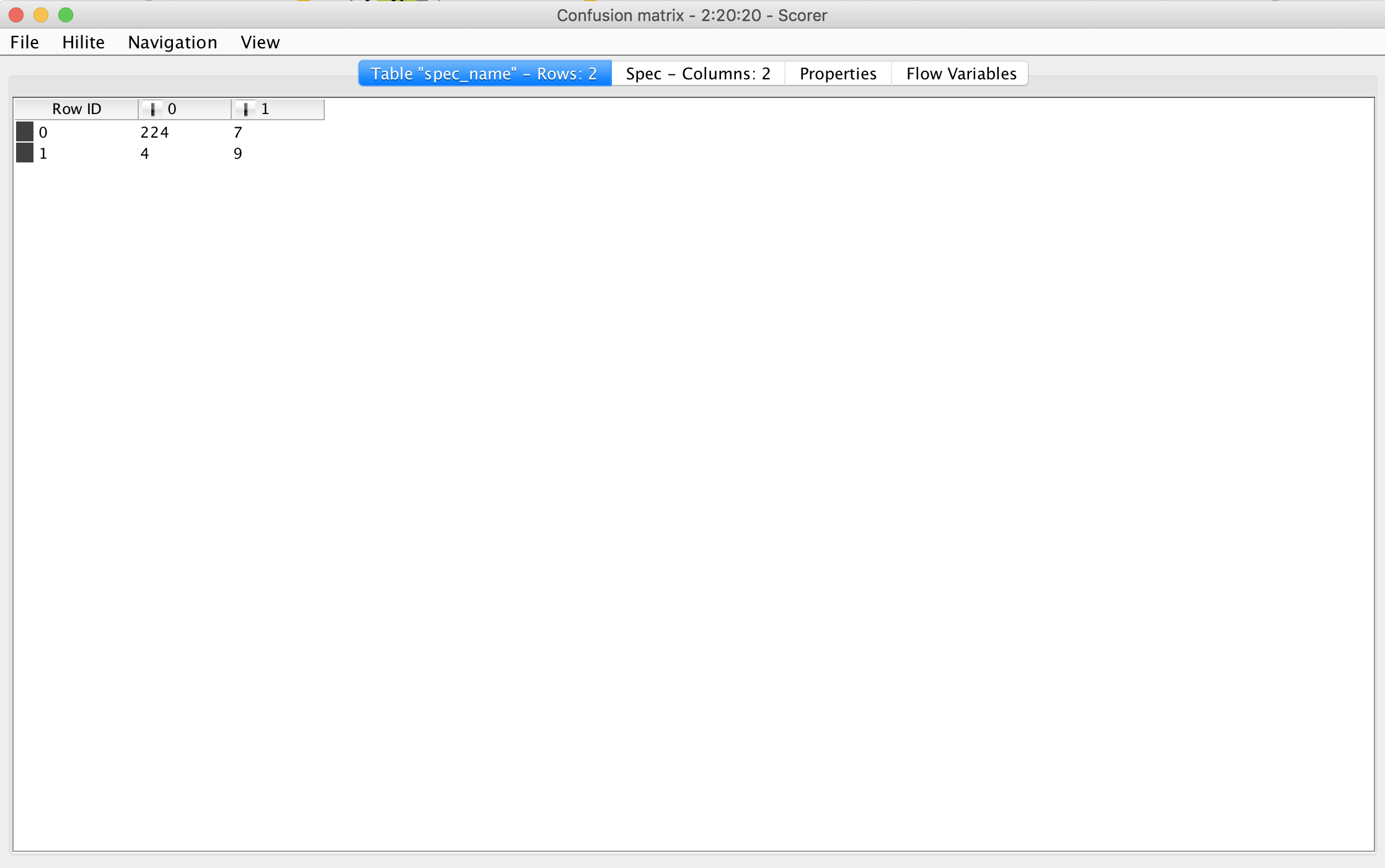
if you look at the first image (the scorer node accuracy statistics) you will see that I reduced my dependent variable to 1 and 0.
0 is for actual show-ups and 1 is for no-shows - if you look at each of these and sum up their TP/FP/TN/FN you will get 488 which would be the exact number that I used for my test-data (20 % of 2440)
the doctor’s question is why it works like this, which I can’t seem to explain (sometimes in this field you figure out that you have a missing understanding of something that is vital to what you’re doing which is very humbling)
I think somewhere in your workflow the test dataset is being reduced by 50% from 488 to 244 observations. Because as I said, the statistics in the accuracy table from the scorer node are given for all observations for every class.
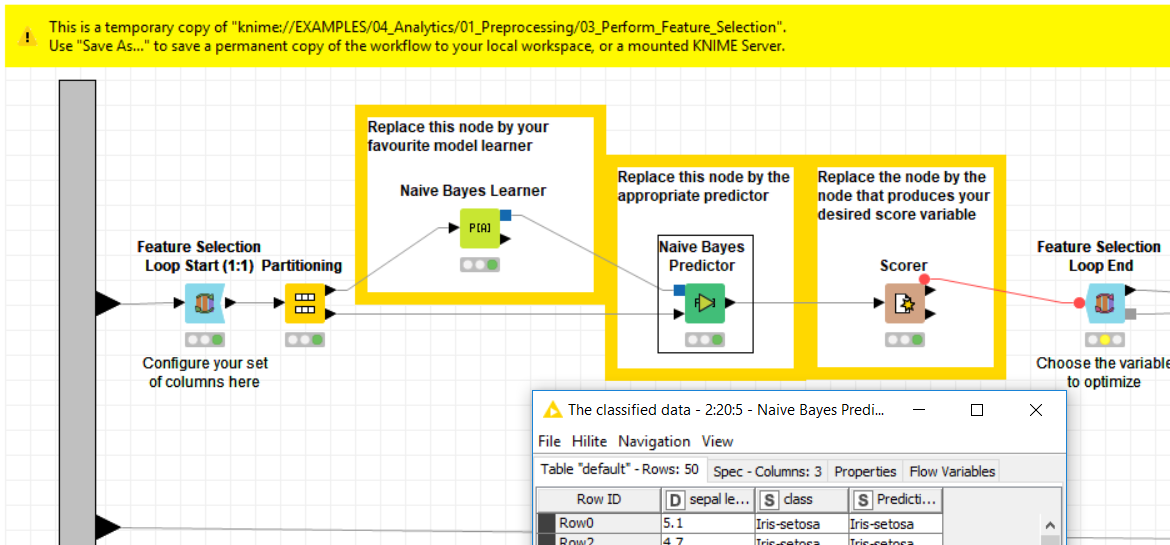
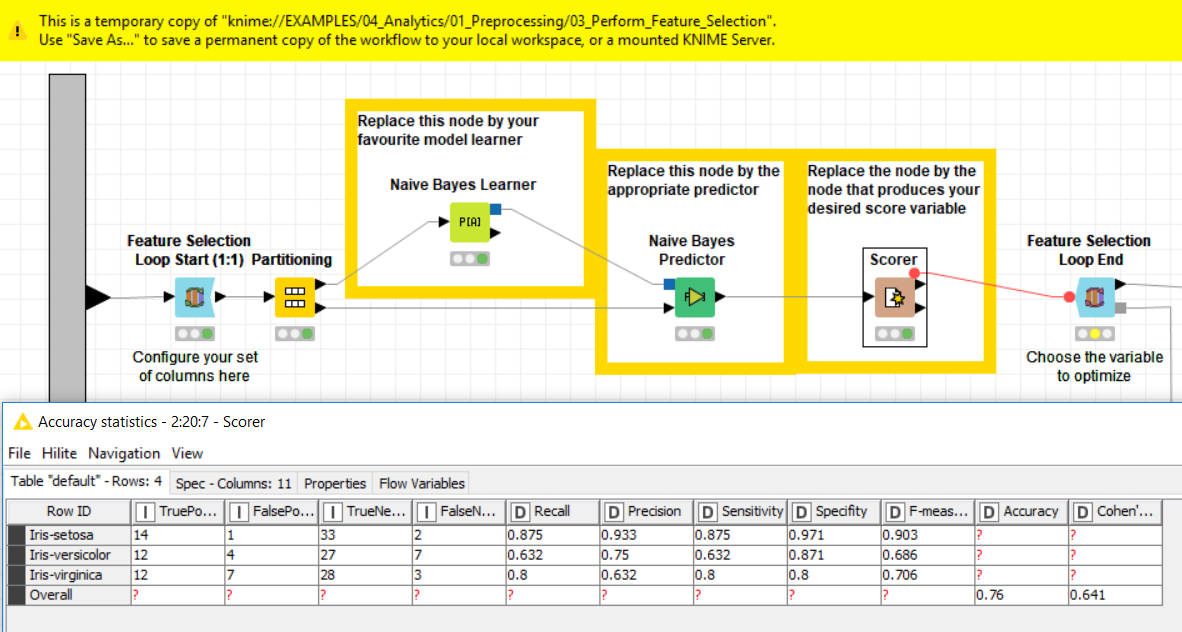
If you take this example workflow (knime://EXAMPLES/04_Analytics/01_Preprocessing/03_Perform_Feature_Selection) as example, you see that the testset has 50 observations:
Can you elaborate a little more on how your model training and evaluation is set up, maybe send a screenshot or something (I assume you can’t share your workflow as of data privacy reasons)?
First you should check how many rows go into your scorer node (right click and show table from last menue item). Judging from the results it should be 244. The Statistics give you an estimation from ‘both’ perspectives (so the numbers in the first 4 integers columns are ‘double’ the total amount of rows)
And from the ‘point of view’ of the no-shows (your = 1) the Precision is 56% because out of 16 the model predicted as no-shows 7 did show up in the end.
Also you should check if all rows got a numeric score before making the decision of predicting 0/1 - it would be very strange if exactly have would not have gotten one, but just to make sure.
What I don’t understand still is how it only takes 244 when i told it to take 488 (20 %)
This is what I’ve tried to explain the doc but what he said seems unlikely that we can divide them into equal 244 observations
**Preliminary conclusion(please correct me on this) **
The score I get is the model taking two perspectives - predicting show-ups (0)and predicting no-shows (1) it divides up an equal amount of observations 244/244
@Marten_Pfannenschmidt
Tried to look at the workflow but it’s not possible to download right now. Would you be able to shoot me an email with it to cgyldenkaerne@gmail.com ?
you were both right. It was my x-partioner that had the value 10 for ‘number of validations’ which confused me… setting it to 5 partitioned 20/80 like i wanted to which happened to improve my model (yaaay!)
@Marten_Pfannenschmidt feel free to contact me by mail or in this thread if you want to learn more about the problem, the setting, the approach and the results
A few thoughts on your results. Of course the value of such a prediction depends vey much on the underlying business question you want to answer and especially the costs/consequences that are following a miss-classification. For example if someone who was classified a no-show would have to wait 10 minutes longer it might be different than if he would not receive treatment at all that day- just to give an example.
With that in mind you should revisit your results:
99.x accuracy sounds impressive. But you have to keep in mind that show-up is the absolute default result so even if a model would ‘predict’ everyone to show up the accuracy would be 94.x overall
in the group you predict as no-shows (question is what happens to them or what are the costs) you are correct in 21 out of 32 cases
if you just reserve seats for them in the waiting area your model might be OK because you are only 5 out of 488 off the overall numbers (because some people di not show up you predicted to do so). If you predict specific assignments for doctors or something it might be different
balance your target group or overrepresent them (but be careful to test the results on a non-balanced group). The KNIME SMOTE node might help you
set the ‘borders’ for true/false decisions yourself (you could use Cohen’s Kappa to determine a good cutoff) which again might depend on your business-question
you could use models that optimise not overall model quality (Gini, AUC) but something like Top Decile Lift (so the performance in the very Top category gets optimised)
assign explicit costs for misclassifications in you model development (depending on your business question)
explore further techniques like fraud detection where you search for tiny populations where a false classifications carries a huge cost (I am not an expert here)
And in the end: always have a test and improvement circle ready to see what your model does in real life and be ready to have some circles of improvement (one major mis-conceptions about model building ist that people assume because it is high-shiny ‘artificial intelligence’ it has to be magic and perfect on the first instalment)
Your post is so relevant for my problem and your observations are highly appreciated and I will make sure to go through each one for my thesis (which is the project level for now)
Upon implementation, the clinic is very careful.
The model will be trained with new data each month and for with data from individual months to learn more about the seasonal behavior of the patients. Also, we are just testing this first on a small ambulatory where the business case is just for patients with booked operations with surgeons, nurses and cleaning personal not being able to use their time differently. Right now their intervention is calling every single patient 5 days before treatment to bring down the number (which works). It, unfortunately, costs them one nurse working full time on this. The idea is to work towards prediction that would make it worthwhile to just call patients that are
Either NOT predicted as show-ups (which makes me think about your first point )
Predicted as no-shows and live with the cost of missing a few patients.
If you have any other ideas for this, I would love to hear it
In other ambulatories, the no-shows is actually important for them to be able to not over-work, get stress and be able to meet their time schedule (Danish problem i guess)
The hope is that this can be implemented in other ambulatories(if successful) of the same hospital but fitted to their specific case and use.
The article you shared looks like something I need to learn about.
Thank you so much for your time and wonderful feedback!
This sounds like an interesting project. I would like to add these additional thoughts
try to interview people who are familiar with this no-show process and might have some gut ideas about what is driving this and see if you get these ideas into data. Often my experience with data mining and models is you would not detect something spectacular new but rather develop systematic rules and implement them on a large scale that experts know by instinct or could write down by hand. So basically you distill a lot of human knowledge and experience into a (easily reproducible) predictive model. Also you should show appreciation and some humility towards the people doing the tasks on hotlines and front desks - in the end your job as a data scientist/analyst is to make their work and life better and more efficient
seasonality might indeed play an important role. You might want to include a lot of this information about holidays or upcoming local events, concerts and the like. Be aware they might shift in time (like easter) so maybe you want to include them like days-before-procedure (Dividing and splitting rows)
when you already have a system in place to call possible no-shows up front you might use a score to only call the 10% most likely no-shows and so save on precious time of nurses. You might include the answers and the learnings from the people you did not call and who still turned out to be no-shows into a separate model
one other way to improve the efficiency of calls is to use uplift-modelling for which there even is a KNIME extension (https://www.knime.com/book/dymatrix-uplift-modeling-nodes-for-knime-trusted-extension). But it takes some effort to implement that. So you do not call the people who are already lining up in front of the Apple store to buy the latest iPhone but rather the ones your call might convince to switch there from Android (without your call they would have stayed with Google’s system)
try to get as much information about the patients as you could (and are allowed by data privacy regulations). Age, martial status, kids all might play a role - either as a ‘real’ reason or to use Auntie Jane’s wedding anniversary to chicken out of a procedure. And I would assume you have some geographical and traffic information there (ease to reach the medical facility)
As this is something used in production, you need to ensure that you actually understand what is happening here. From the way you wrote this, you don’t,
EDIT:
Also Accuracy in such a highly imbalanced data set means absolutely nothing. You should look at F1 score and Cohens kappa and also Precision and Recall. For example Precision tell me that from the ones you predict as no-shows, 65% are actually no shows. It’s entirely up to you to decide whether this is good enough or not. (It’s for sure a lot better than pure guessing).
I appreciate your feedback and taking time to address this. Can you please elaborate on this one?
You’re completely right on your other note. I’m going to put my head on the block once again (that is the only way I will learn not being a statistician but from a soft IT background)
Let’s say 7 % don’t show up. That leads to hospital to call everyone on their list for surgery to bring down these numbers - expensive and costs them an employee for each department.
If the model is very good at predicting show-ups and the current intervention is calling 100 % wouldn’t it make sense to just call everyone not characterized as predicted show-ups + people predicted as no-shows? Do you follow my idea?
I was more thinking about your workflow and what the x-aggregator does? You you understand the difference between 5 and 10?
Also do you understand the metrics of the scorer and why accuracy is meaningless mostly especially in your case?
And what is the purpose of the column list loop start? (Honest question, what is it for?) Some form of feature selection? I wouldn’t even bother. how many features are there? trees are relatively good at ignoring irrelevant features assuming most are relevant. Easier to just use Low variance and correlation filters.
I do understand why accuracy is extremely vague due to most observation being in the class ‘showing-up’ and so this being quite pointless to look at.
I’m using this to learn what features are most important in my model in order to generate new ideas for interventions
See attached graph of variable importance:
My danish is not so good so I asked Dr Google but the column on the right seems to say “number of no-shows”. If this is in your data and this is the thing you want to predict it renders the whole thing useless. Please think hard about want you are setting up and want a model might be able to do for you.
Edit: ok if this is the number of No Shows of a Patient before it might make sense
Problem with kappa is that it is hard to say if it is good or not. The more complex your domain, the lower it can be to be considered good.The easier the domain, the higher it should be.
Given the graph you showed with the features (few) and the most important one being previous no shows of this patient, I would consider to also look at logistic regression (simpler) than boosting. To help, knowing what the other features are would probably also be helpful.(Patient ID obviously is not a feature).
I would say a good feature would obviously be “Ratio of no-show”. Eg how many appointments there where vs number of times the patient did not show up. The number of no-shows itself should increase with number of appointments.
A problem I for see is if you have a large amount of recurring patients. The model will only be good for patients that have already scheduled many appointments, for all new patients it will be meaningless.
Last but not least maybe it would be enough to just use the Ratio of no-show as “chance” that this patient will be a no show. Probably no complex model needed! Here the real challenge would be to make the prediction accurately without knowing the previous number of no-shows!
I think you should do some work your data. As has been metioned. Patient ID might not be a good indicator and might not be stable.
Thinks linke postal code I would try to transform to something like distance between clinic and the home of patients especially if you want to use it in different locations.
Since number or ratio of no-shows before seems to be so important you might try to set up a separate model for new patients or include an indicator that it is a new patient.
You might try a simple decision tree for starters and see if you like the rules it produces if they make sense.
And you should check that if you have a patient more than once in your database that you only have them either in the training or the test DB.
For sure either or and it will almost certainly be better to use the ratio because then the model doesn’t need to figure out the connection between Number visits/number no-shows itself. BTW this is called feature engineering.
Also what mlauber71 said. The postal code is a rather poor feature as well. As he said distance to the clinic would make a lot more sense.
What you actually want to predict is loyalty / reliability of patients. This mostly depends on the persons character and I see this as very difficult to predict with the data you probably have available, at least for new patients. For existing ones the previous no-show ratio is probably all you need.