Halo, I’m a basic user, I need a help.
What is the best practive to clean up data from web page saving into an excel format, with some information need.
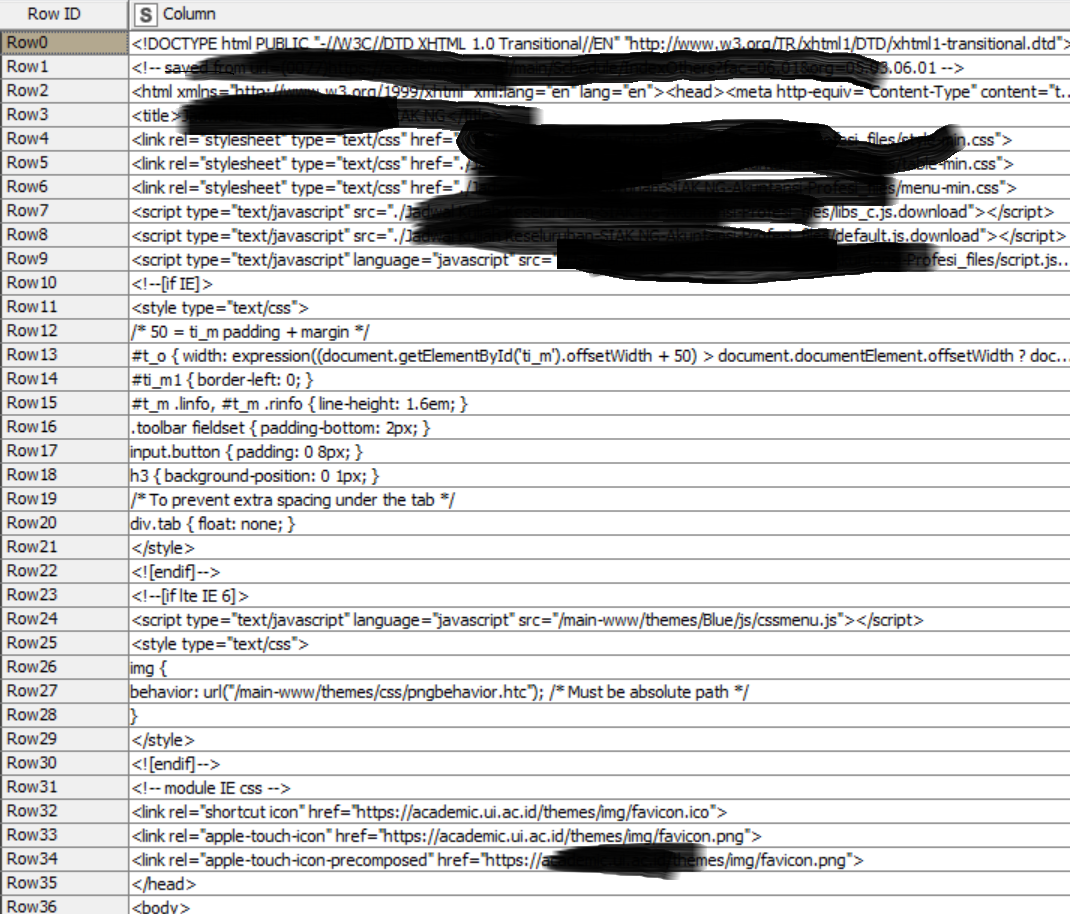
I’ve saved my files (html doc.) - list files/folders → table row to variable loop start → line reader
What is the best way to organize the data dan get the information from that unstructured data? Thank you so much.
There isn’t a real uniform answer here. It all depends on your usecase. How is the website structure, what kind of data do you want to extract from it, etc. etc.
Below is a snapshot workflow that I have in place that reads a directory of about 700 .html files which are similar in structure but have different data. Nodes like HTML Parser, Xpath and different kinds of string operations would be some go-to nodes for what you’re trying to achieve.
Thank you so much for your great answer. I use Knime 4.7.1, but I cannot find HTML Parser Node. I’ve already install Knime Extension, but still no HTML Parser node. Where I can find that node?
I’m trying to wrangle data from some file data that I save from website (web page). Put them together in one table (can be excel table), clean data, and change text/javascript.
Your description is too generic to offer any specific help unfortunately. You can find example workflow with the HMTL Parser for some inspiration on the beforementioned page as well: