We have tweets with text and hashtags. We want to do a network analysis with hashtags only. So we want to know which hashtags are often posted together in one tweet. How does this work ? Is there a node for this ?
Hi @mihribanstrk,
Could you give a bit more input on how your data looks like?
Depending on how your data is structured and how your result should look like it might be easy.
Maybe provide a short example on how the base data looks and what it should be transformed into ![]()
Maybe NGrams could be helpful here. You might want to have a look at these until a better solution arrives
br
1 Like
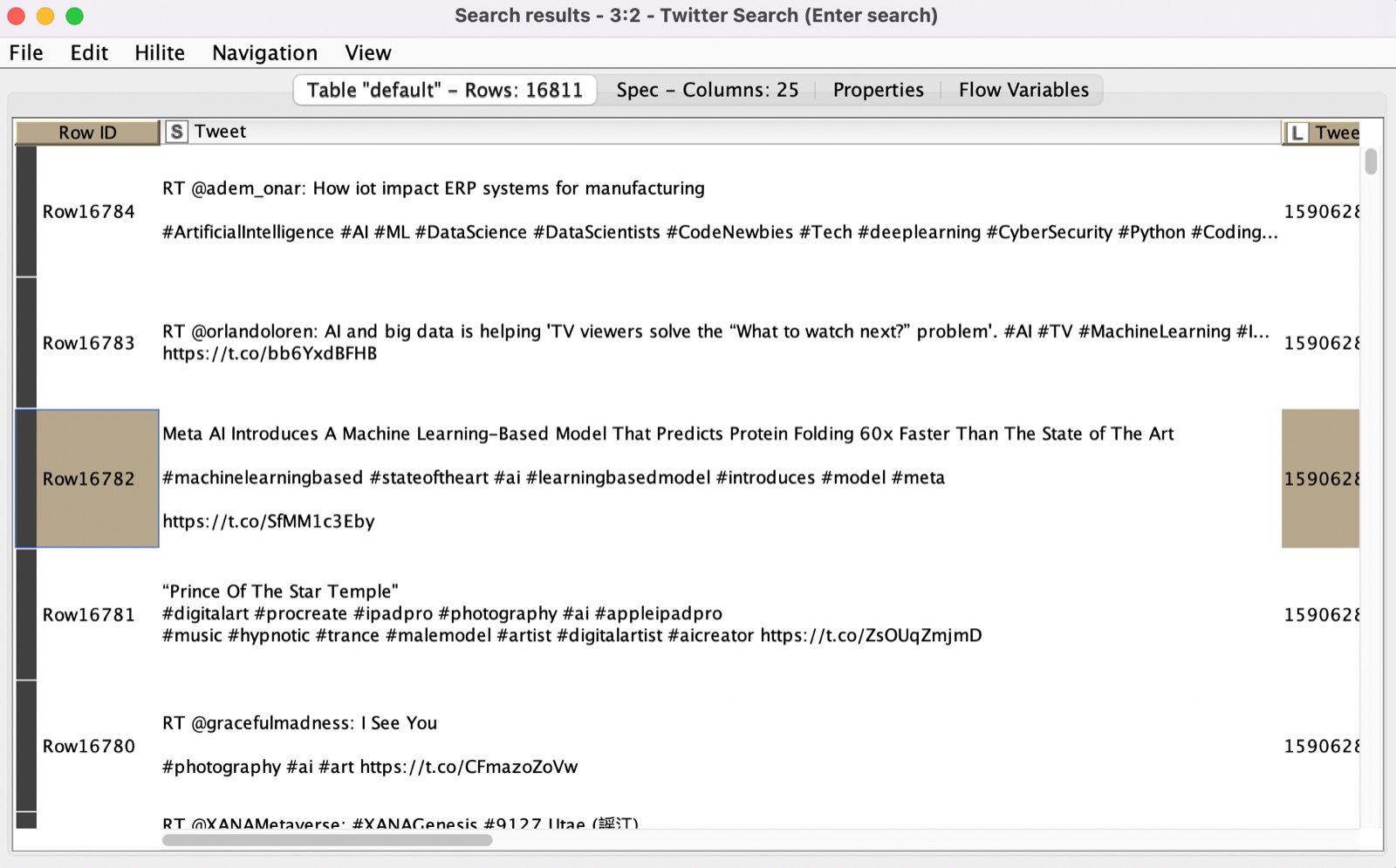
The Tweet column contains both text and hashtags. We want to separate them by separating text and hashtags and analyzing them separately. We wanted to analyze the context of the hashtags by looking at which hashtags were used together in the respective tweets.
1 Like
Hi @mihribanstrk,
maybe have a look on the text mining courses ![]()
They provide good information about various text mining tasks.
For the following example I basically just applied the example from:
to your task ![]()
(maybe not the perfect match but hope that it is close enough to what you intend to do)
Tweet Example.knwf (586.2 KB)
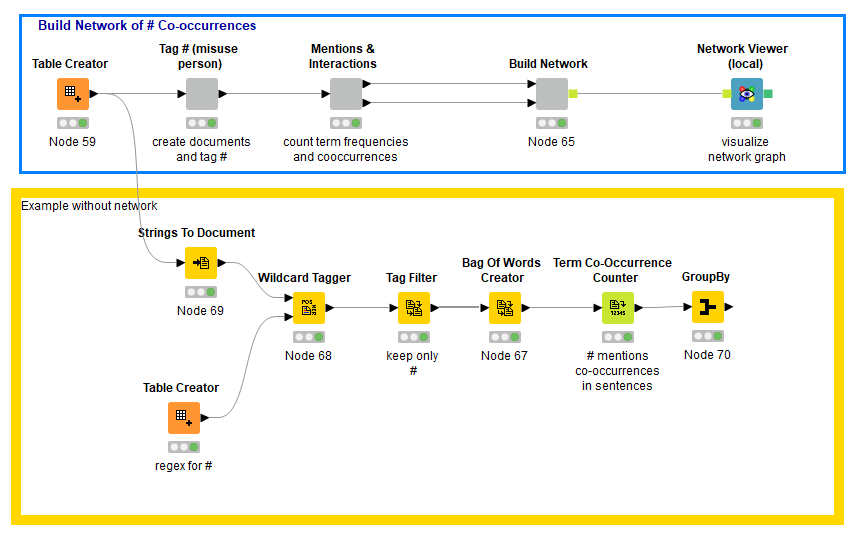
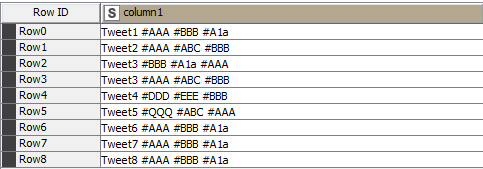
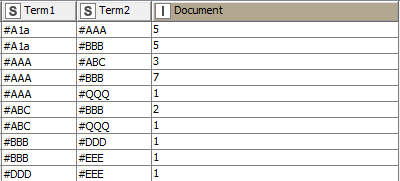
Input Example Data:
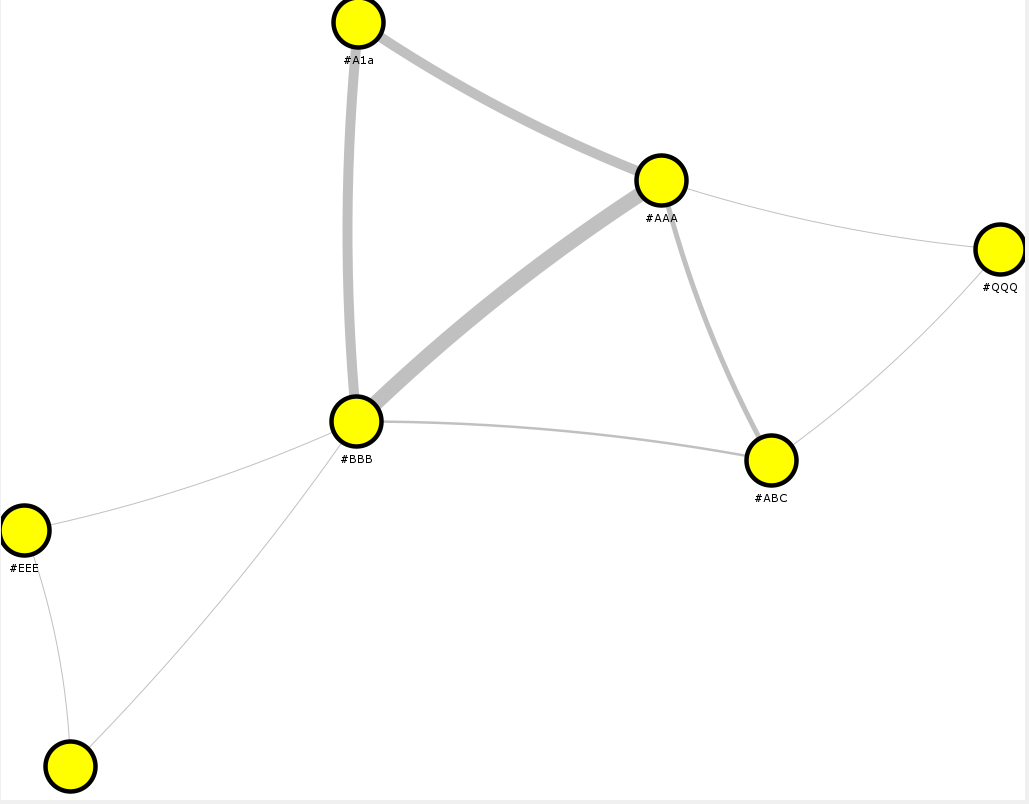
Output Network:
Output groupBy:
*maybe this years summit has a text mining course as well ![]()
Can really recommend these courses ![]()
5 Likes
Thank you for showing the alternative option using the TCoC node @AnotherFraudUser . I can adapt it to use for my future projects.
1 Like
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.