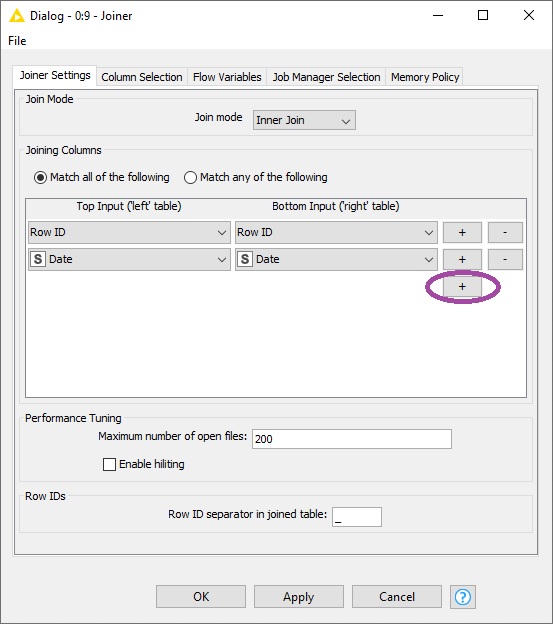
What is the difference? whether it checks the first column then the second or both at once the logic says they both should match when you have selected the first option (Match all of the following).
Ah, I guess I worry that it will match on some dates without matching on IDs. So perhaps there will be a case that data is pulled together by date only. I’m not sure I am explaining this so well.
Basically what I am looking to do, is have it so that the IDs are all matched, and then if dates match within the IDs then they would be matched also - does that make sense?
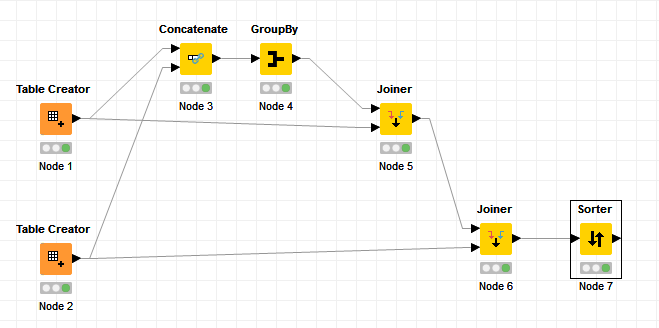
So let’s follow your logic step by step:
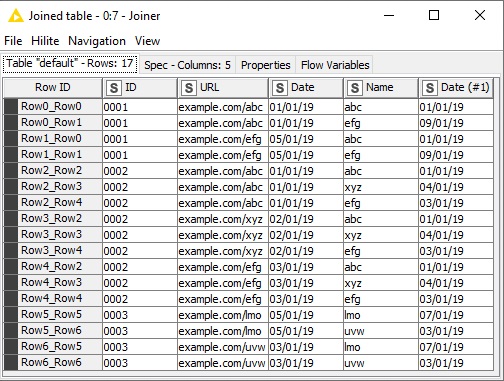
First, the tables should be joined based on the IDs, so we have different dates in a single joined row. Each instance with the same ID in the second table will create a new row per each row in the first table. For example, for the ID = 0001 in your sample datasets there will be 4 rows. The first row from the first table joins with the first 2 rows from the second table and the same for the second row from the first table so finally we have 4 rows for ID = 0001.
Then you want this:
In the joined table where I provided its image, there are 2 cases:
Dates match as well.
Dates do not match.
If you want those rows in which dates match as well, then the approach where we joined tables based on both ID and Date at once is the solution.
If you haven’t given up on this matter you can write down what is your desired output of the two data sets you from your first post and I’m sure someone will try to help you
I actually tried to write it down, but I think I am not capable of explaining it - perhaps because I don’t understand it as well as I thought It did, myself. Also, I don’t want to keep taking up too much of you guys’ time.