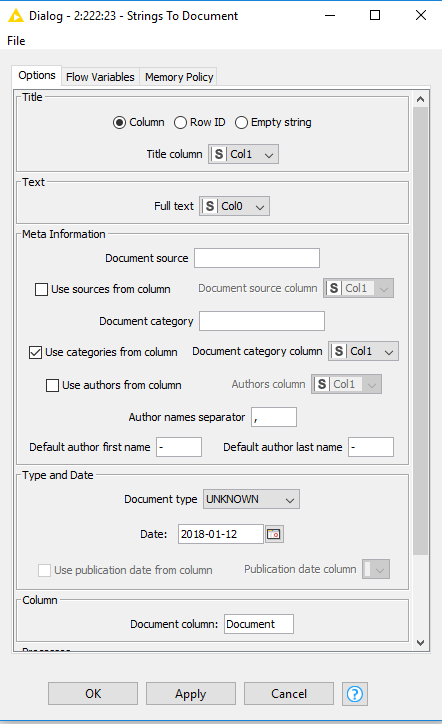
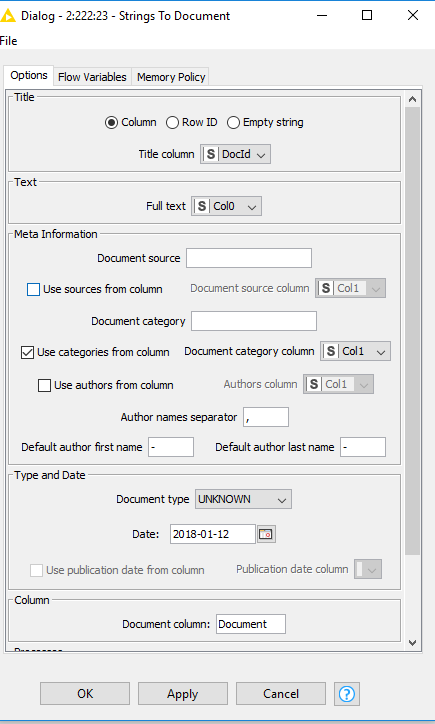
Hello,
I am having really bad experience with strings to document node. So, I have two columns(one is text and one is category). When I use the category column as the title in the settings of the node then model is giving me very good accuracy like 90%.
and If I’m using another column for title in the settings node, I’m not having good accuracy. What could be the problem?
This screenshot is giving me 90% accuracy.
I have an educated guess about what’s going on here (I downloaded your workflow to check, but the data wasn’t included). The Strings to Document node will include whatever you choose for the title as part of your corpus. So, if you have a long title and relatively short text - and it looks from your workflow like you are processing single sentences - noise from the title may be dominating your model and causing strange results.
Unless your title contains key info you want included as part of your analysis, it might be better to set the title to an empty string, or at least a very short unique ID.
The data still isn’t coming through. When you export the workflow, you can uncheck the Reset Workflow(s) before export box to make sure the state of the workflow is saved. Alternately, you could upload the data separately, or include it as part of the workflow using relative paths (as described in this blog post, under Keeping Your Data with Your Workflow).
EDIT: I see that your model was posted in another thread. I’m looking at it now.
To your question: one way to increase the accuracy might be to use a different algorithm - there are many that will likely perform better than a decision tree. You might also consider including some parameter optimization loops.
So far I have been able to increase the accuracy to just under 95% by using default XGBoost instead of the Decision Tree. I am doing some simple parameter optimization now that will hopefully improve results further - when it completes, I’ll post the updated workflow.
What is your accuracy goal for this task? Or are you using some other model quality metric?
Thank you so much @ScottF
However, you were also including the class column as a tittle that is why the accuracy was so good. but when I changed the title to the empty column in strings to documents node. The accuracy is now 53%. Could you please have a look at this workflow? https://mega.nz/#!TyJ2WQIT!lDhtM7FYiO7jMYSKFCZ98fdHV8WQlj9vx4RgF0UugXs
Thanks for uploading the workflow again. You’re right, I made a silly mistake before.
I tried playing with your new workflow a bit more and wasn’t able to improve things much. I got rid of the tag filtering, and tried keeping more terms generally, but to no avail. There are a few reasons which might explain why the model might not be performing well.
The classes are imbalanced. You have many more sentences labeled assertive, for example, than you do commissive. This leads to the model incorrectly assigning assertive a large part of the time. I tried correcting for this using stratfied sampling and SMOTE, but it didn’t have much effect.
Essentially, you are trying to classify (relatively) short sentences by analyzing frequency of their component words. This approach works for sentiment analysis because we have a dictionary that we can use to tag certain words as having positive or negative connotations. In this case, we don’t have an analog to help us determine what words make a sentence directive, or expressive. Accounting for combinations of words, or ordering of words relative to one another, might help here - perhaps by using an LSTM - but that’s a significantly more complicated workflow.
Sorry that I don’t have a better answer for you than that. But maybe it gives you something to think about.