I attached the whole workflow in a slightly new version. Now also including the XGBoost and H2O models.
Maybe at some point you could elaborate about your Document preparation (now in the Meta Node) - that could be illustrative for other people too.
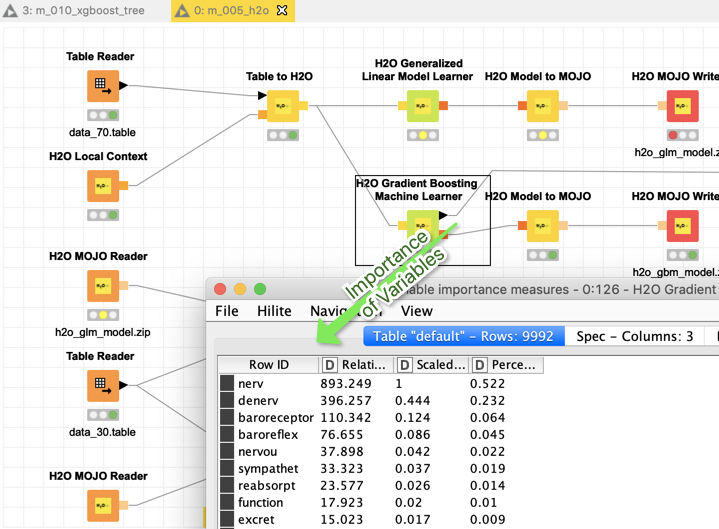
H2O gives no better Accuracy but GBM could provide you with a list of variable importance. That can be useful in checking if the whole thing makes sense. For example if a variable would show up here that might contain a ‘leak’ you might notice.
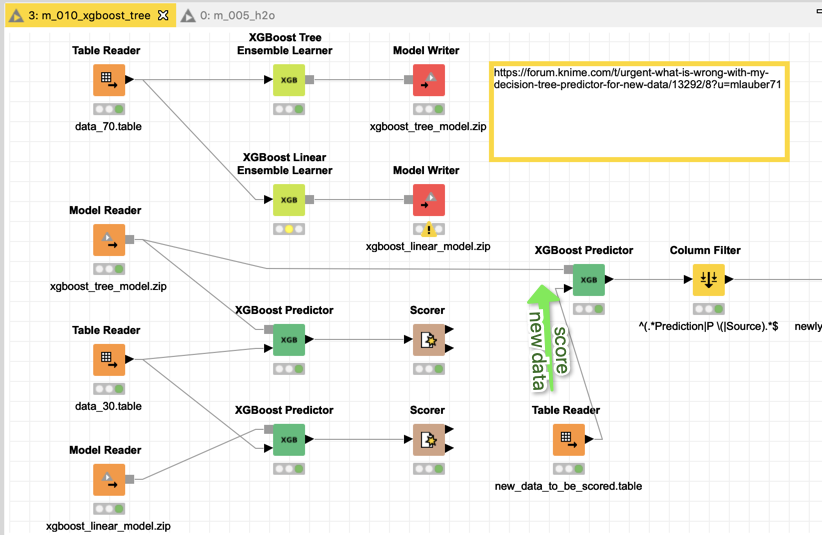
For the XGBoost I also added the scoring of new data from the m_001 workflow with the original decision tree.
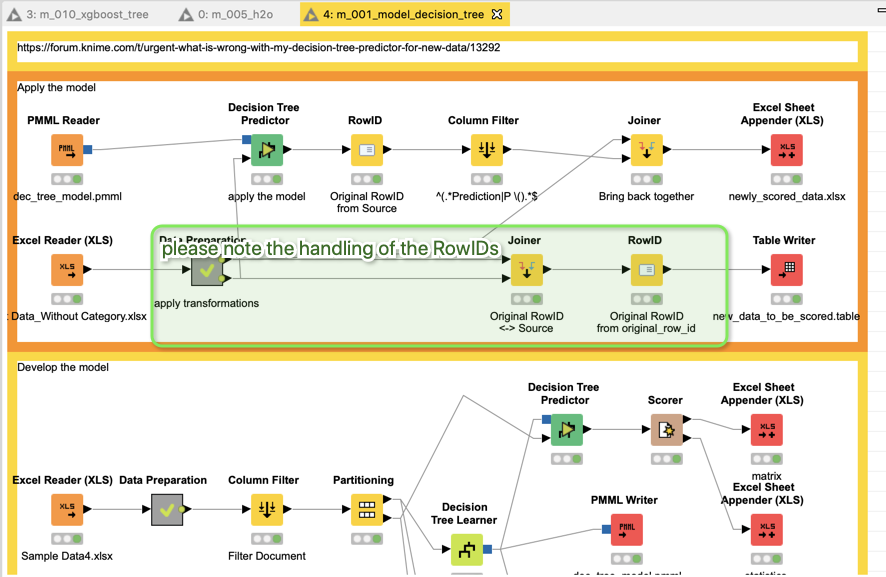
I am a little bit obsessed with the preservation of IDs because if you want to bring such a thing into production question will always be to identify the cases/customers and often you have to match that back to some external data source. So please take extra care about IDs, customer numbers etc.
kn_example_document_prediction.knar (3.8 MB)