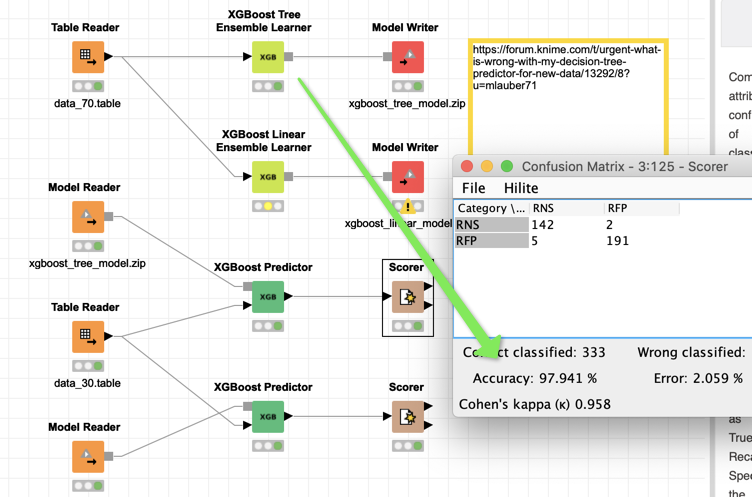
If the data preparation is any good (please check that since you seemed to ave put a lot of effort into it) using the latest star in the modelling universe XGBoost you can -well- boost your Accuracy to 97.941% - and yes at a certain point overfitting might set in.
m_010_xgboost_tree.knwf (190.4 KB)
xgboost_tree_model.zip (156.4 KB)