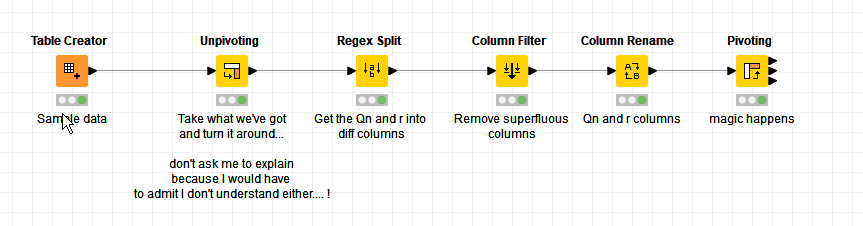
haven’t used KNIME for some time, so I may be a little bit rusty.
I checked if my problem was mentioned before, but couldn’t find anything fitting.
I have a table which looks like this:
User
Q1r1
Q1r2
Q1r3
Q2r1
Q2r2
Q3r3
A
1
0
2
2
1
0
B
0
0
1
2
0
1
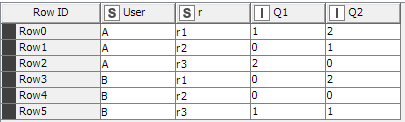
What I would like to have as an output is this
User
r
Q1
Q2
A
r1
1
2
A
r2
0
1
A
r3
2
0
B
r1
0
2
B
r2
0
0
B
r3
1
1
I tried “Cell Splitter” and “Column Splitter”, but this didn’t help.
Does anyone has any idea? I should also mention that in the original table I have quite a lot of "r"s and "Q"s.
Here’s one way you could approach the problem. If you have lots of “r” and “Q” values then you just need to add rules to the appropriate Rule Engine nodes.
I put together this alternative but I think we can safely say from our solutions, that it involves pivoting! (which as you’ll see from my comments, I have no clue about… I just keep plugging away until something usable appears! )
[Columns to Rows.knwf|attachment]
(upload://zn9xMM9q86lFntRUYgdgkUjbqR5.knwf) (13.9 KB)
I don’t blame you @ScottF, but while I’ve still plenty to learn, I’ve (finally!) got to a point where I don’t have to keep heading to regex101.com, and I definitely have other members of this forum to thank for that as there have been a few people over the past few months who I’ve got tips from with their solutions.
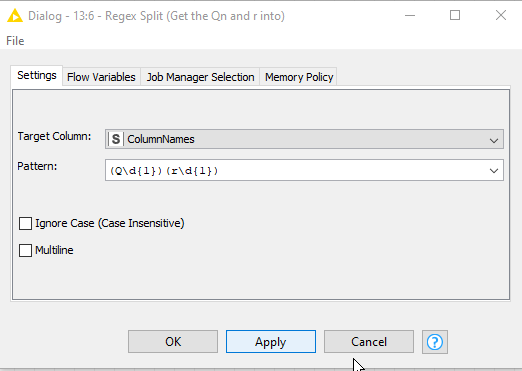
I tried Regex Split, but have no idea, what command I should put into it. I tried several combinations based on the explanation examples in KMIME about the Regex Split Node. The only one, that worked somehow was
([^\r]*)
But this just duplictes the column. Seems I’m lacking the language skills to use Regix Split. Could you help?
Hi @mkoch. I just noticed that on my previous post the link for the workflow I uploaded seems to be corrupted. I’ve added it here again. Was that the reason for your question about regex split?
It is splitting the value into two parts, as there are two “capture groups”, marked by ( )
First capture group is: (Q\d{1})
This means “match the part that contains Q followed by a single digit”
Second capture group is: (r\d{1})
This means "match the part that contains r followed by a single digit.
Each capture group is then used to create a new column
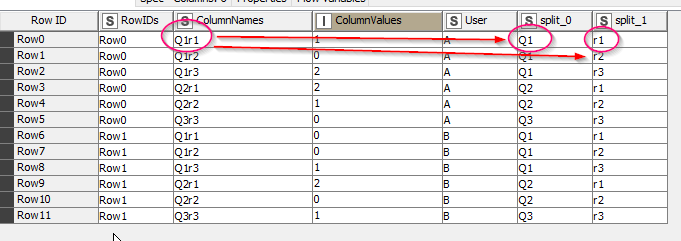
So Q1r1 will be turned into two columns Q1 and r1
regarding your regex ([^\r]*)
yes that would simply duplicate the column. The reason for this is it defines a single capture group denoted by ( ) so it will generate only one column
[^\r]
the [ ] means match characters contained in the class defined by the contents of the square brackets
the ^ in this case means “not” (in different circumstances it could mean “start of line” but inside [ ] it means “not” \r means carriage return, so in total that part means "match any character that is not a carriage return, and then the * that follows it means “apply the previous thing 0,1 or many times”
So your regex would capture everything in the column that is not a carriage return…
Wow! Thank you so much for the very helpful explanation. That helped a lot and works great. Also I learnt something very useful about Regex Split. That’s just perfect!

 (which as you’ll see from my comments, I have no clue about… I just keep plugging away until something usable appears!
(which as you’ll see from my comments, I have no clue about… I just keep plugging away until something usable appears!  )
)