I am extracting information from different data sources and writing in a .parquet file thanks to the “Parquet Writer”.
Each file that I generate in .parquet, belongs to a different database entity.
I have to generate an extract with the data that I currently have, and upload that data to AWS. So far everything is perfect and my flow works perfectly.
Every hour, I have to extract data that makes an append to the parquet, but the “Parquet Writer” only allows me to either overwrite the existing file or error if the file exists. What I need is that, if the file already exists in AWS, I generate a new one with the data, so as not to lose the original data, and thus upload the files to AWS Glue and with a crawler merge all the .parquet for each entity.
Can this be done this way?
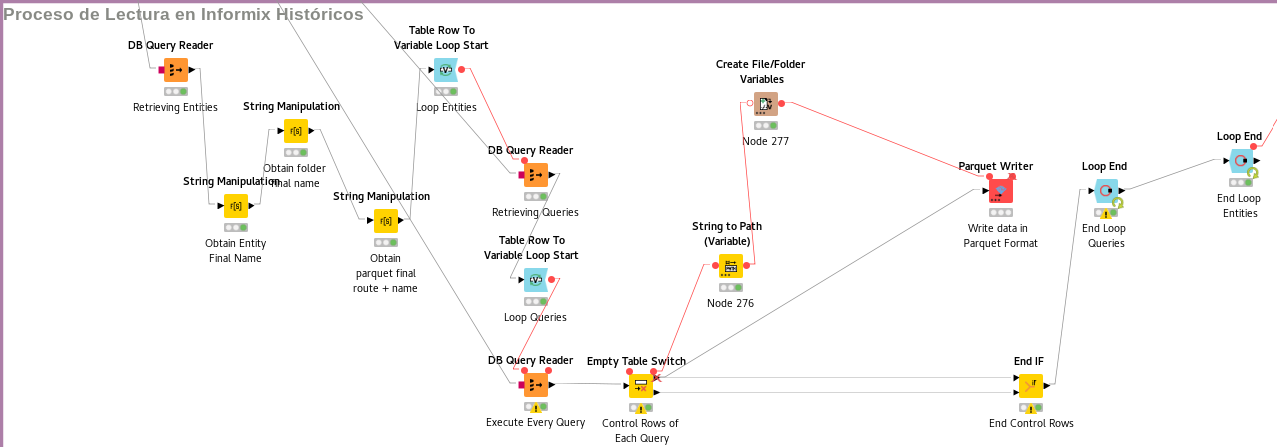
Attach pic of workflow works fine from first time:
@josalsu welcome to the KNIME forum.
First you should check the wiring of the parquet writer since it does not seem to be correct from the screenshot. The writer will have to be connected to the loop end somehow.
Then I do not fully get what you want to do. You could either try to overwrite the parquet file (you might have to delete it first) or you could give it a different name - with a time stamp or something.
If you want these files into one single file there might be something like an external table in Hive to bring them together (“Glue” might indicate that you might be able to well glue them together after all …)
Hi mlauber71
Many thanks for your answer.
01|187x500
In attached picture, what we have done is create a variable in which we collect the execution date and time (red circle) and convert it to a string to drag it in the flow (blue circle). We put that value in the name of the file when doing the write parquet.
The idea was to try to generate the partitions before uploading to AWS S3.
Nor can I find a way to run a Glue crawler from Knime, since when executing the crawler from KNIME, it could generate the partitions.
Thanks in advance.
{kind=link}
Hi @josalsu,
this problem not only occurs for the parquet writer you have that also for other writer nodes.
The simpliest way to solve it is to read the currently stored parquet file, append your new data and write it back to the parquet file.
This is probably not the best solution, but it should work.
BR
Hi @josalsu and welcome to the KNIME community,
not sure if I understand what you mean, but this might help: Add a new column containing the timestamp formatted with the date and hour, but not the minutes or seconds. This column can be used to group your data by hours and in the output parquet file name or partition. This ensures you have one file per hour and you don’t need to append to any file.
After that, you might add an S3 event handler that triggers a AWS Glue Crawler on file uploads. More infos can be found in the beginning of following blog post:
Cherrs
Sascha
This topic was automatically closed 182 days after the last reply. New replies are no longer allowed.