The major discovery was when I dropped the column of datatype ‘Point’.
The “DB Insert” node worked after dropping it.
Then I recreated the table with it.
I used a "String Manipulation’ node with an expression: "string(‘(’+string($GeoLocation$)+‘)’), and "Replace Column’ on.
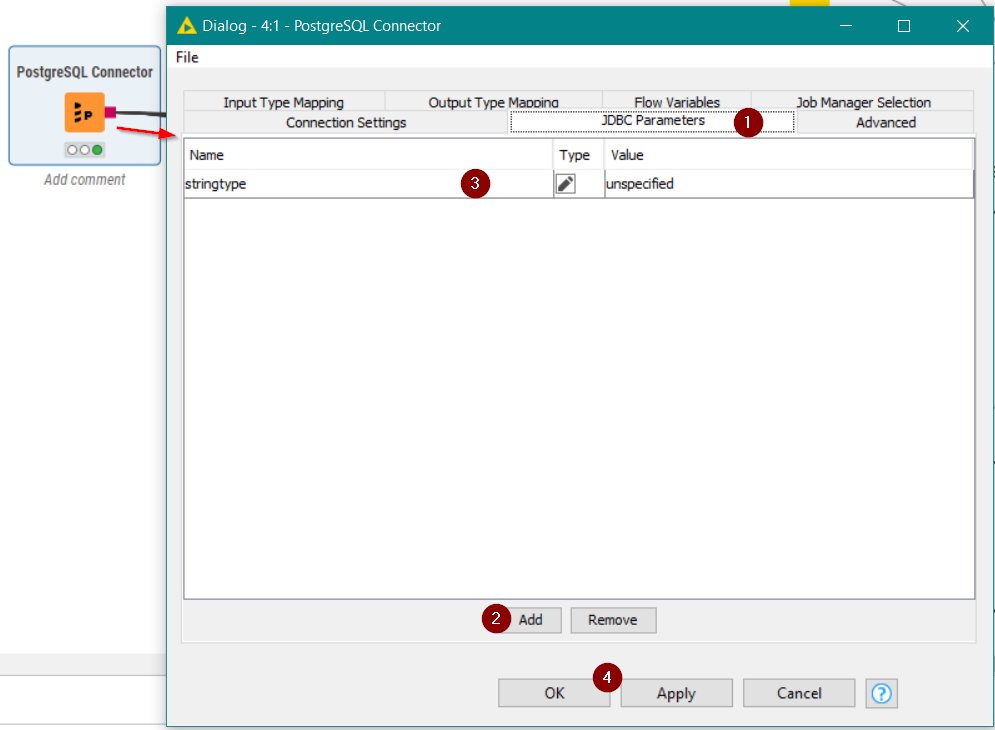
In the PostgreSQL Connector, under “JDBC Parameters”, I added "Name: stringtype’, value “unspecified”.
Under “Advanced”, I set “Delimit only identifier with spaces” checked.
Now the “DB Insert” node works with a table containing a column of type ‘Point’.
Quite a bit of wasted time for such a small detail.
Hi @RRInToronto , thanks for providing this update and glad to see you found a solution.
Now that I’ve searched using this information, I see that it has appeared on the forum before, with reference to such things as uploading GUIDs on postgres. It does feel like the postgres jdbc driver default in this regard is poorly chosen, but I’m sure there were reasons!
It is amazing how much time the “small details” waste in the world of IT! Sometimes it feels like I’ve made an entire career out of those waste-of-time “moments” (that… and watching progress bars, egg timers and blue circles of doom, lol)
For ease of reference for others, I’ve add a screenshot of the jdbc parameter from your solution:
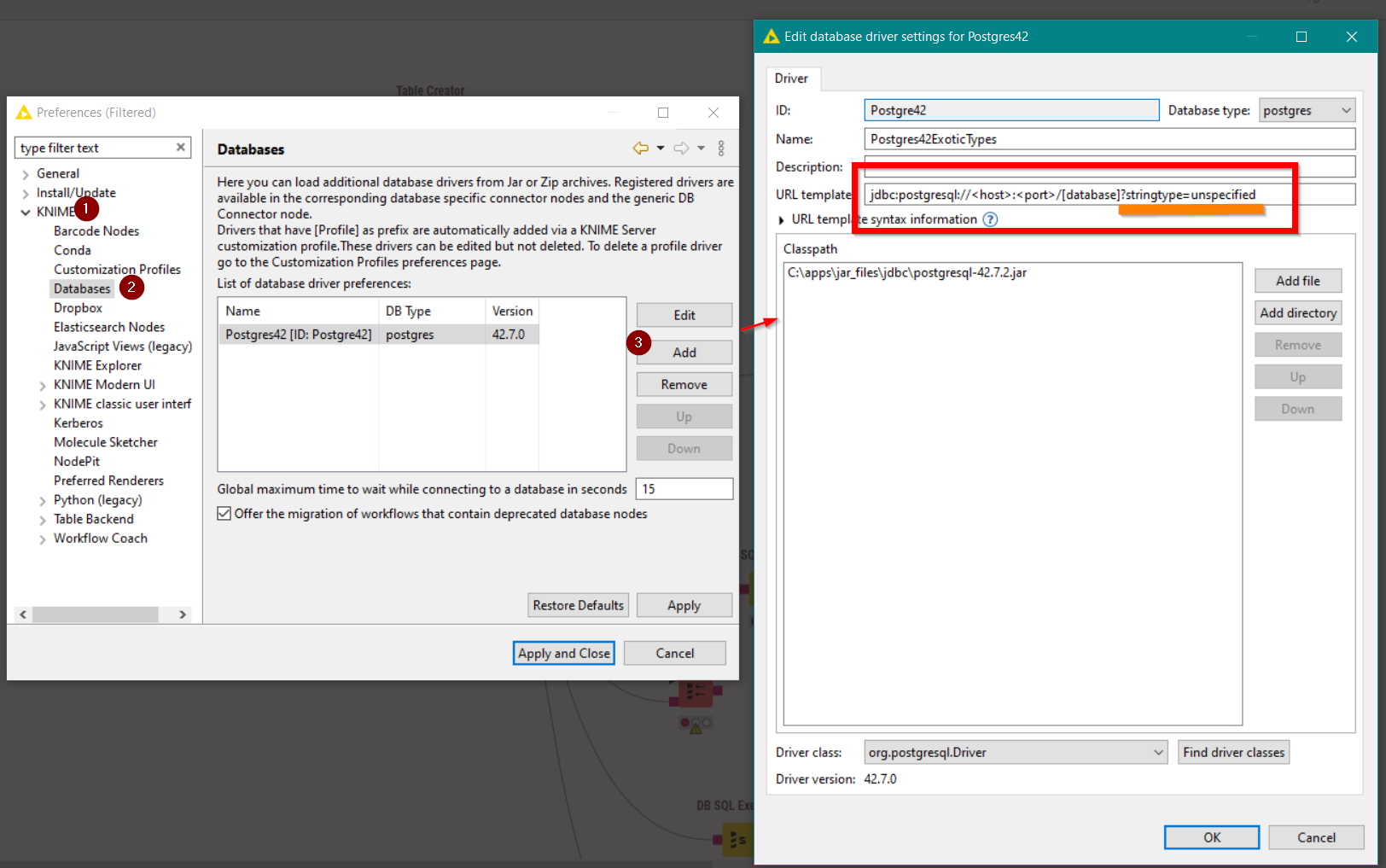
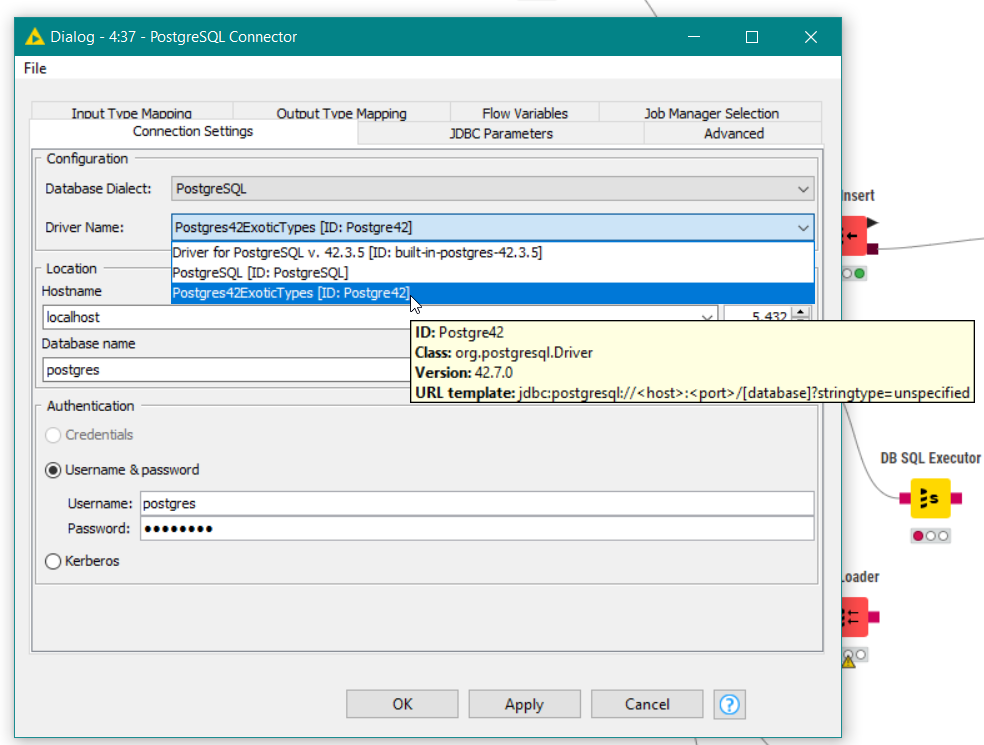
It occurred to me that if using what I would refer to as “exotic data types” is something that you would need to do often with postgres, then you are not going to want to have to add that jdbc parameter every time you add a PostgreSQL Connector node to a workflow. What you could do instead is install a new postgres jdbc driver so that you can set its default by including ?stringtype=unspecified onto the template jdbc url like this:
There is a downside to this approach though: i.e. having to install the driver on multiple machines if you share the workflow (and reinstalling updated versions, or maybe when a new version of KNIME is released). I would like to see a day when KNIME allows us to create a local repository of nodes with tweaked default values, but maybe that’s something I need to add to the feedback/ideas section!
Please mark you own solution as “the solution” to this thread, so that others with a similar question in the future can find it, and thanks again for posting this useful information.
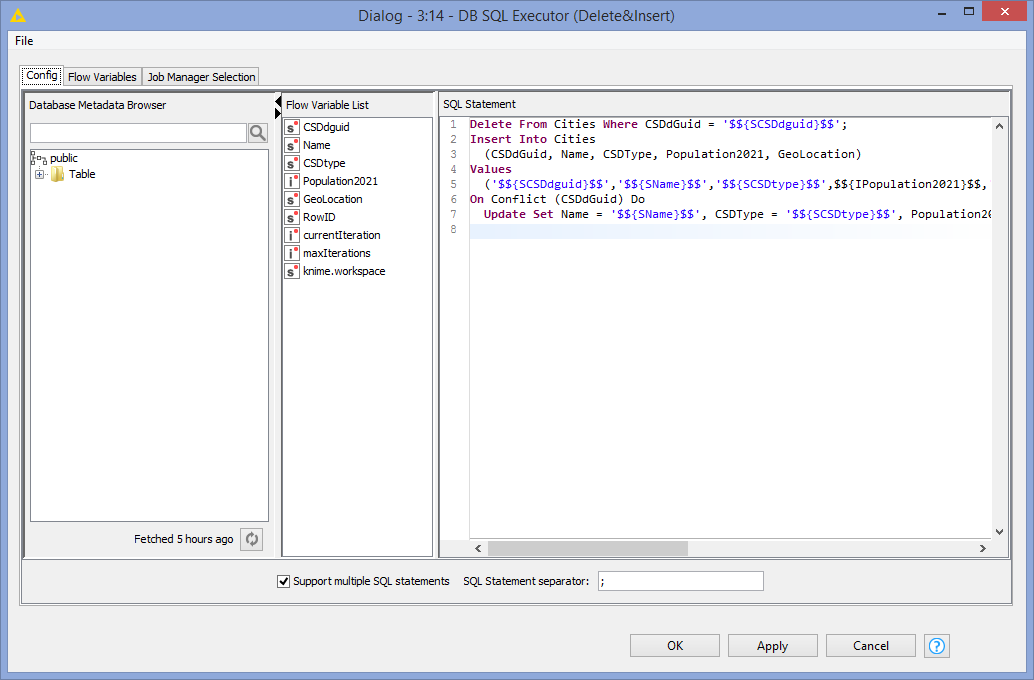
The SQL expression:
Delete From Cities Where CSDdGuid = ‘$${SCSDdguid}$$’;
Insert Into Cities
(CSDdGuid, Name, CSDType, Population2021, GeoLocation)
Values
(‘$${SCSDdguid}$$’,‘$${SName}$$’,‘$${SCSDtype}$$’,$${IPopulation2021}$$,‘$${SGeoLocation}$$’)
On Conflict (CSDdGuid) Do
Update Set Name = ‘$${SName}$$’, CSDType = ‘$${SCSDtype}$$’, Population2021 = $${IPopulation2021}$$, GeoLocation = ‘$${SGeoLocation}$$’ Where Cities.CSDdGuid = ‘$${SCSDdguid}$$’;
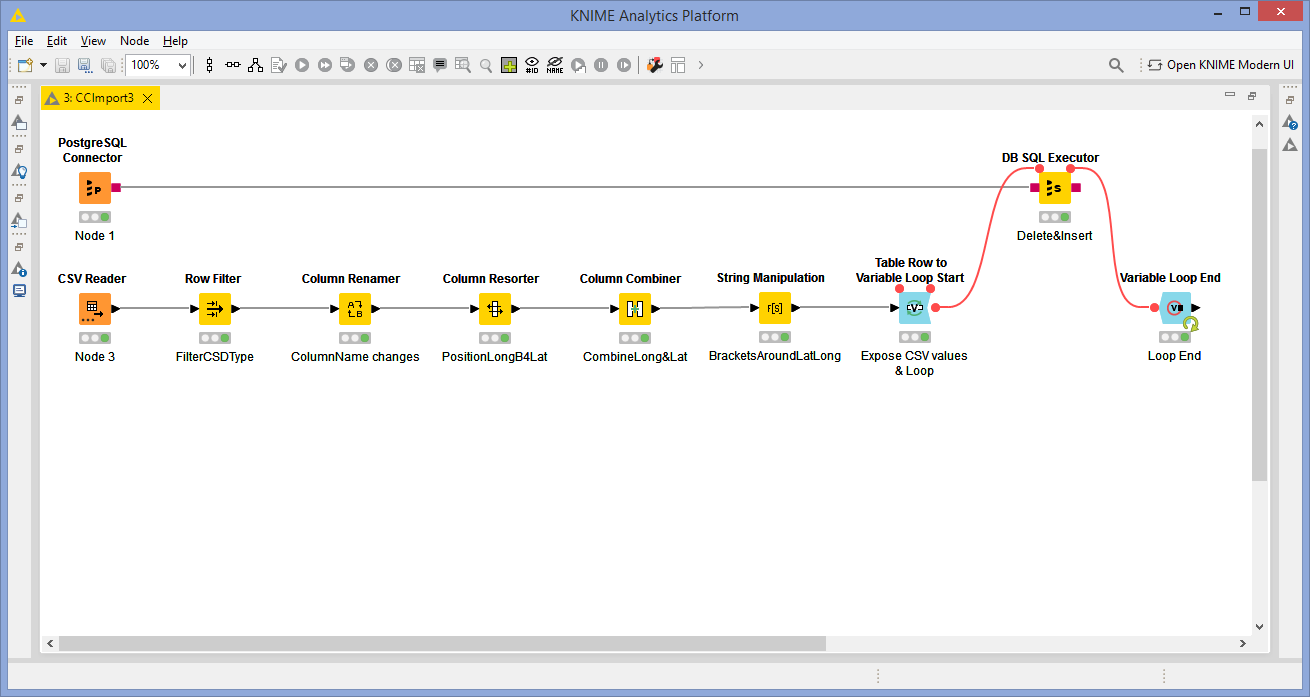
Note: I had to “Show Flow Variable Ports” on the Nodes 1 & 2, to get the flow working.
I’m glad I figured that out, as it has it’s advantages!!!