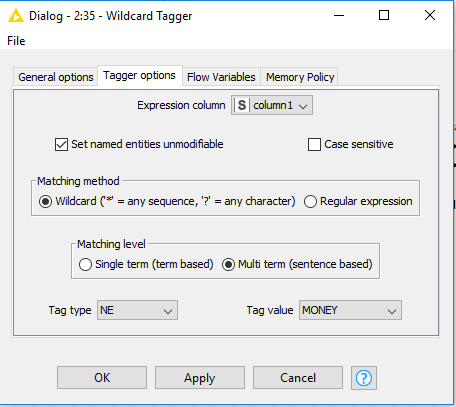
Hi,
When I was trying to tag a corpus with following settings I keep getting these error messages:
ERROR Wildcard Tagger 2:35 Execute failed: String index out of range: 33
ERROR Wildcard Tagger 2:35 Execute failed: String index out of range: 72
ERROR Wildcard Tagger 2:35 Execute failed: String index out of range: 63
ERROR Wildcard Tagger 2:35 Execute failed: String index out of range: 63
ERROR Wildcard Tagger 2:35 Execute failed: String index out of range: 72
My corpus is about 1M documents, when I run the sameworkflow for 100K rows it works perfectly. What would be the issue here?
I don’t think it’s a problem related to the number of documents. I guess there might be document which can’t be processed by the tagger. This can (but shouldn’t) happen if there are some encoding issues or special characters.
It would be quite helpful, if you could detect the document or a subset of documents which leads to this error by tagging only a few documents at once. Maybe 100k rows and then another 100k rows and so on. If you can find the document, I can have a closer look to see what the actual issue is.
I was just getting the same error when tagging 300k tweets in various languages. Out of the whole dataset, it appears that the only character that caused the error was this one: İ (basically a capital I with a dot on top). Filtering out tweets that included this character solved the problem. And I even deleted this character (and no others) from the tweets to check that the remaining content was fine.
Perhaps this information will be useful for future revisions of the node.