From time to time, I faced a need to save hierarchical data to or delete it from a database. So far I’ve incorporated several approaches to achieve it but I like the most the one I’m going to describe. It’s not just I’d want to share my knowledge and help others. I’m more motivated by the fact I always search for the solution in my notes and among my workflow.
Let’s consider we have a DB table consisting of, but not only of, columns ID and PARENT_ID. There’s a foreign key binding these columns together.
Now we have got some data to store to the table. If we tried to write the whole data we would probably end up with constraint violation error. Sure we could disable the constraint and recreate it after we have done but it wouldn’t be funny enough. Well, we need to split out data and save it piece after piece so that we always save the data with no dependency at all or with already satisfied dependency. Let’s employ the Recursive Loop to have the task done. The workflow fragment would look as follows.
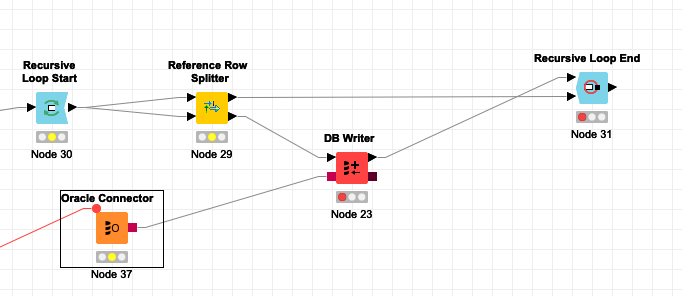
The Reference Row Splitter is the magic. Have a look at its configuration:
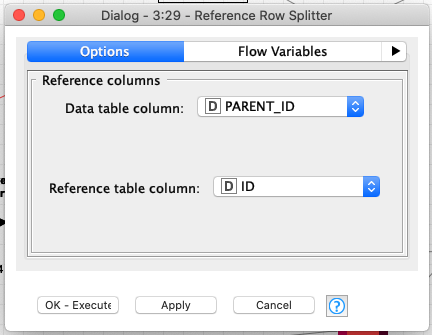
This node extracts records whose parent records are not part of the data we haven’t saved yet. So they either don’t have parents at all or their parents have been already saved. Now we can save these records and pass the others to the next loop. After a few leaps, we’ve done.
This task is tightly coupled with another one which is deleting hierarchical data. The solution is similar. Let’s see the nodes:
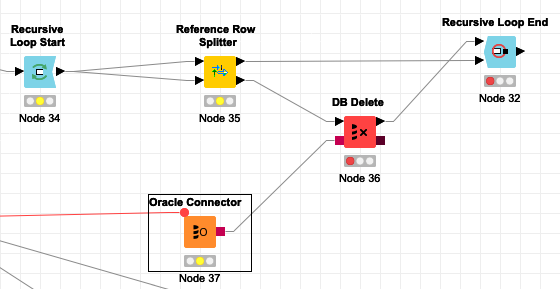
You can see, we replaced DB Writer node with DB Delete node. The only additional thing we have to do is reversing the order of columns in Reference Row Splitter so that we unlike what we did previously, delete the data nothing depends on, first.
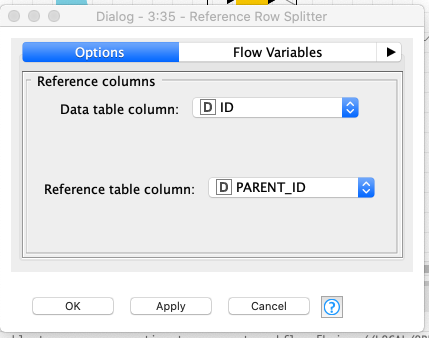
And that’s all.
