No problem @stanage , and I can confirm that choosing the encoding to UTF-8 actually takes care of it:
Without UTF-8:
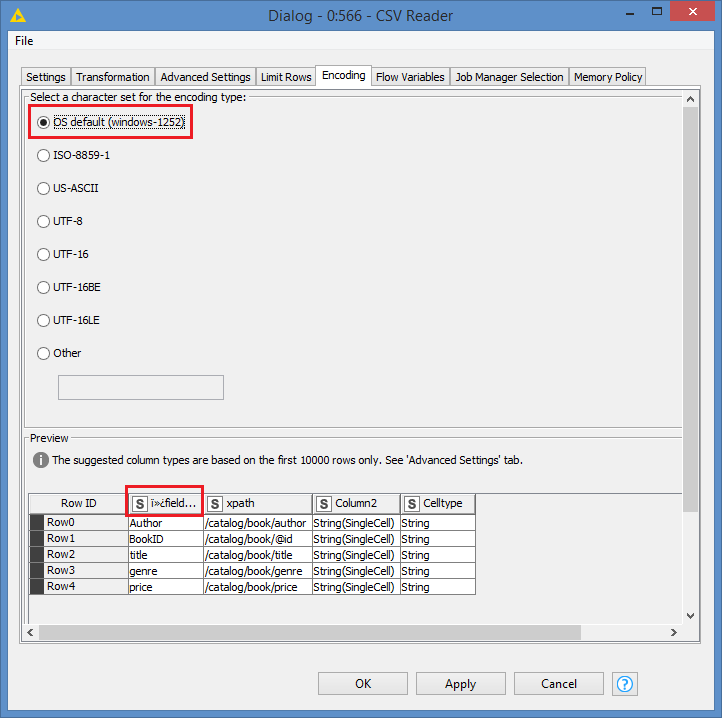
With UTF-8:
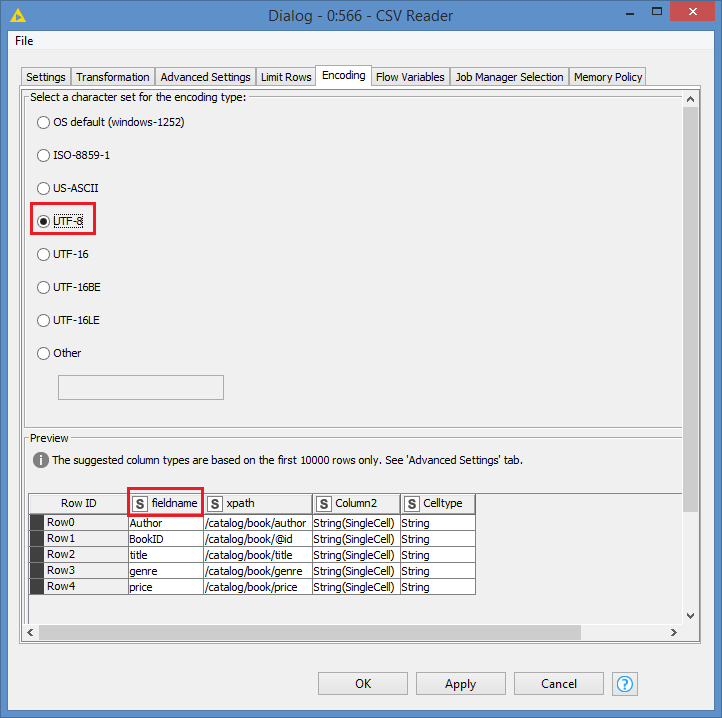
Regarding your issue now, there are a few things that are wrong:
First of all, I don’t think the loop is a good approach. If you do it this way, it will actually run the XPath multiple times, that will create duplicates each time the XPath runs. You want to run all the rules at once in the same XPath.
Secondly, I am guessing that you want the information of each book on a separate line, correct, like this:
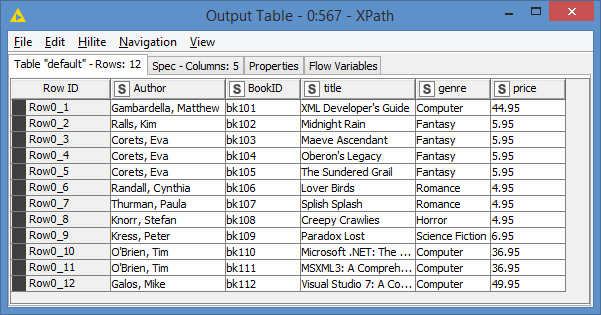
If that is the case, then you have to use type String(Multiple Rows) instead of String(SingleCell)
Now, putting everything together… The thing is, while the approach with the separate file that defines the title and path, etc is great, it does not look to be efficient with XPath. Let me explain:
Let’s first look at how all of these path should be defined manually:
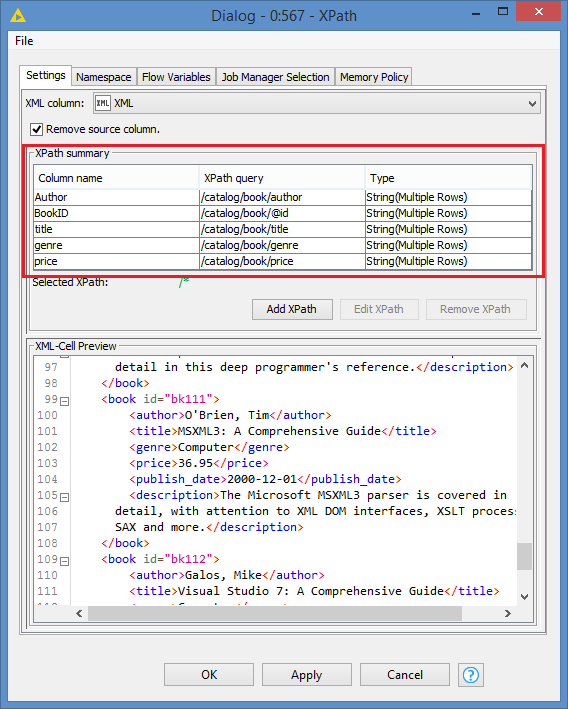
It’s basically 1 XPath node only, with all the queries defined in the XPath summary.
Now, to make use of Flow variables here, unfortunately the node does not take arrays/list/collections of data that you can pass dynamically, but rather it will create a certain amount of the following sets, in your case, since you are defining 5 queries, it will create 5 sets of these (0 to 4):
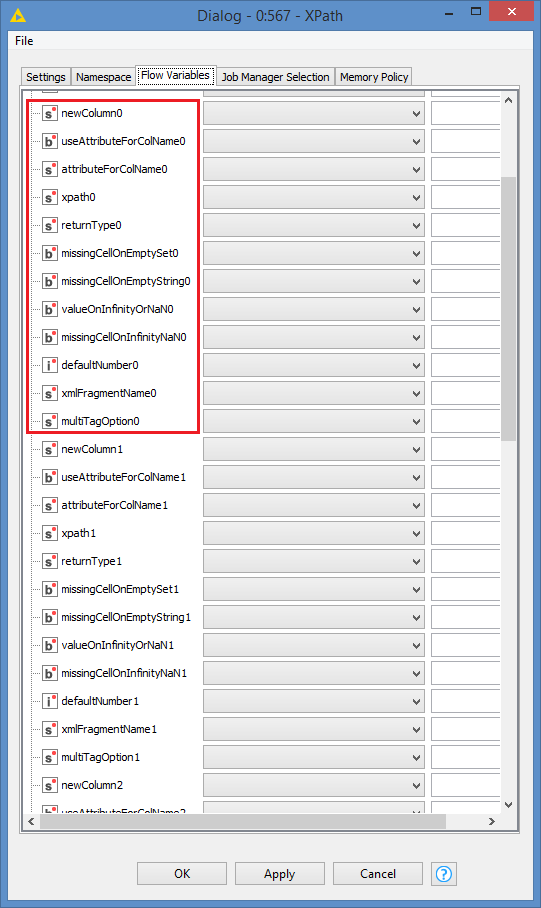
This means that you have to manually and add your variables 5 times. Then you might as well just add them directly manually into the XPath Summary:
EDIT: So, because you are using a Variable Loop End, you are not collecting the data during the loop, so that is why you see only the last column, which is price.
If you use a Loop End instead, it will then give you the data, however, you will get duplicate entries as I mentioned. There are ways to then process the data to remove these duplicates.
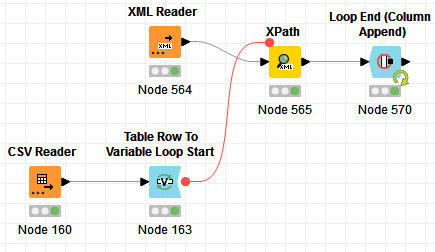
However, there is also the Loop End (Column Append), which will append each new column to the table, without duplicating anything. And this works perfectly with your approach.
Workflow looks like this:
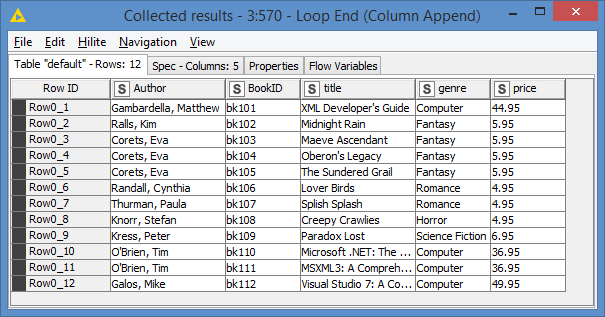
Results:
Here’s the workflow: XML Parser - Bruno.knwf (17.8 KB)