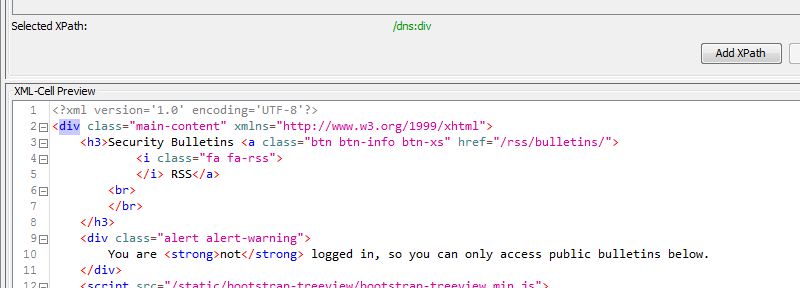
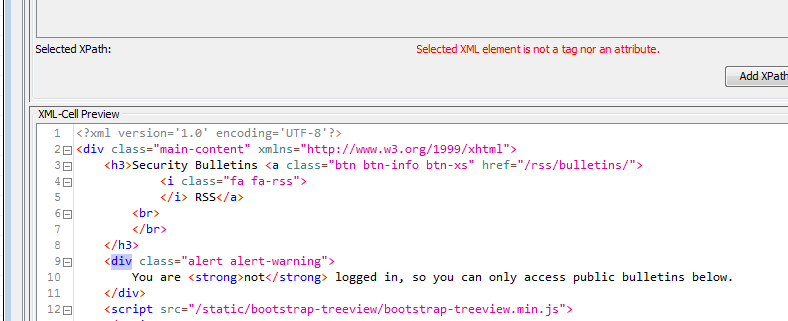
I’m trying to use the Xpath node (which I have used before with no problem) to parse some HTML content (again, which I have done before). So when I’m using the point and click interface I am seeing the following behavior:
I’m not sure if this will solve your problem but here is my suggestion:
Open the document in Firefox and from the menu select Web developer -> Inspector (Ctrl+Shift+c). Then find the tag you want and right click then select Copy and then select XPath. Paste the path in the XPath node and add the “dns:” to the path (e.g. /dns:html/dns:body/dns:div/dns:div/dns:p). Then configure the other settings and press OK.
The reason for suggesting Firefox is that sometimes I get wrong xpath from Chrome but Firefox does well.
I’ll give that a try. What I want is way past the point I’ve highlighted…it’s just that is where it seems to go off the rails, no tags work after that point.
Using the path generated by Firefox gets me past the blockage and I have extracted all the table rows I want. Hopefully everything will be well behaved as I start to unpack the information in the rows.