Hello;
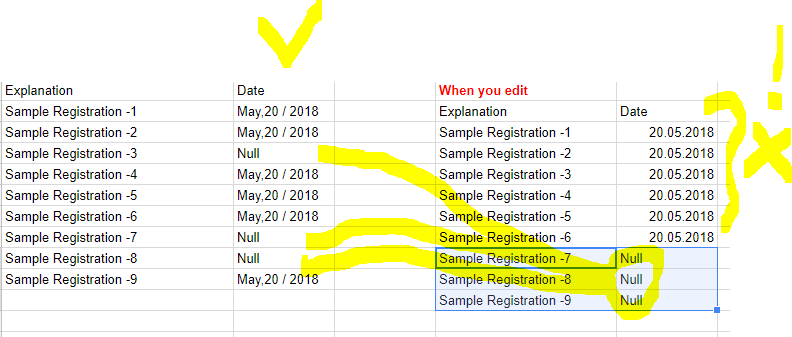
I am editing to standardize date data. It works fine but; It causes the problem of skipping empty lines and sorting. That is, when I combine the dates with the other dates, I am collecting the necessary gaps (that is, the blank date lines) in the bottom rows. It’s breaking the general history. (DateExtractor node)
You need to add the empty lines according to their order. you need to add the line without scrolling the rows without canceling the lines that are not the date.
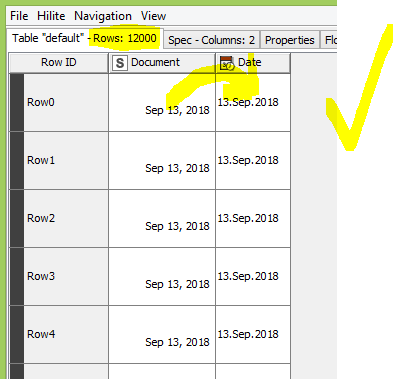
There are 12,000 dates in the two columns of the picture. it does not keep the order of records after conversion.
since these lines do not show any sort, they do not place the correct date in the converted dates because they only take into account all the converted dates.
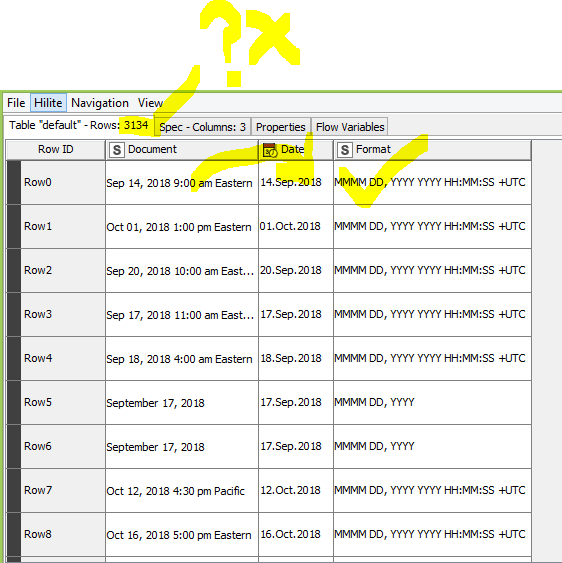
It will only output input rows which contain at least one date (i.e. it will skip blank lines as well as lines which do not contain any parsable date),
In case an input row contains more than one date, it’ll be repeated (i.e. an input row which contained three dates, will produce three output rows, one for each date).
This means, there’s especially no guarantee that the number of input rows reflects the number of output rows.
1 - Can you add a sample stream?
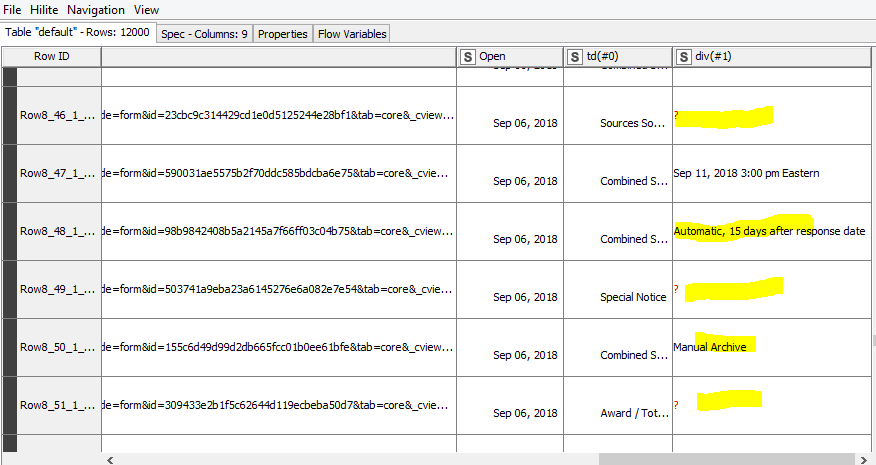
2- I’m adding an alternate workflow below. Would it be possible to turn this into a solution? (ie is it possible to arrange empty or non-empty data so that the rows of the data are empty and only convert the dates but not break the row sorting)?
I don’t have time to look at your workflow now, but here’s an idea:
A potential solution to keep those things in order would probably be to use a chunk loop node and then process your input one line by line. Then you make sure, that the subworkflow within the loop outputs exactly one row for each input row.