Dear readers. For me this is a first try at machine learning, so please talk to me like a five year old!
In the Netherlands we have 3d maps of our rivers. I want, with the help of KNIME/ML to automatically determine the type of shore. To make it easy for now lets use 1 type: Nature Friendly Shore (NFS), and ‘type 2’ NOT a NFS.
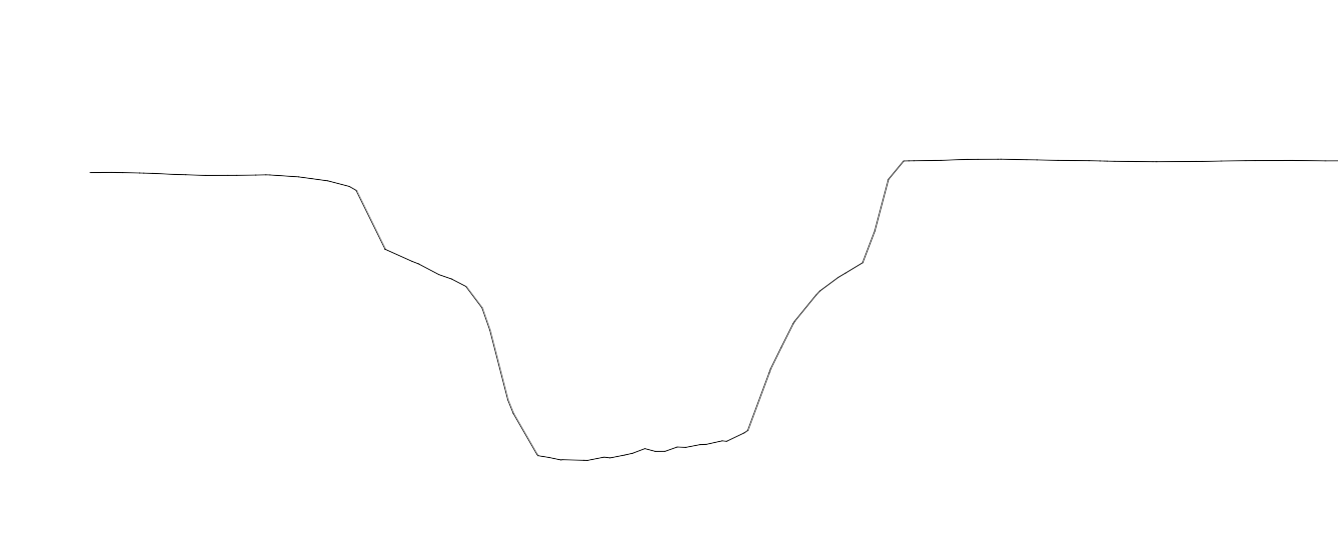
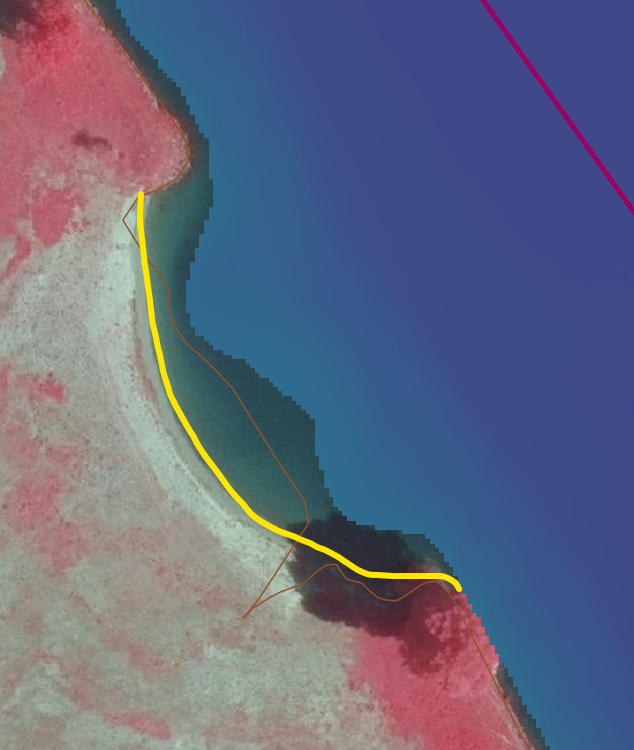
Type 1 roughly looks like this
The angle is always a little bit different; bet never near vertical.
My current plan of attack looks like this:
1/ Determine vector (Blue arrows) of the river. Exporting the purple line to excel will create 2d x,y table with which I can determine de vector AND de geo location.
2/ Create the section cut; should be 90 degrees angle form the vector (Orange below)
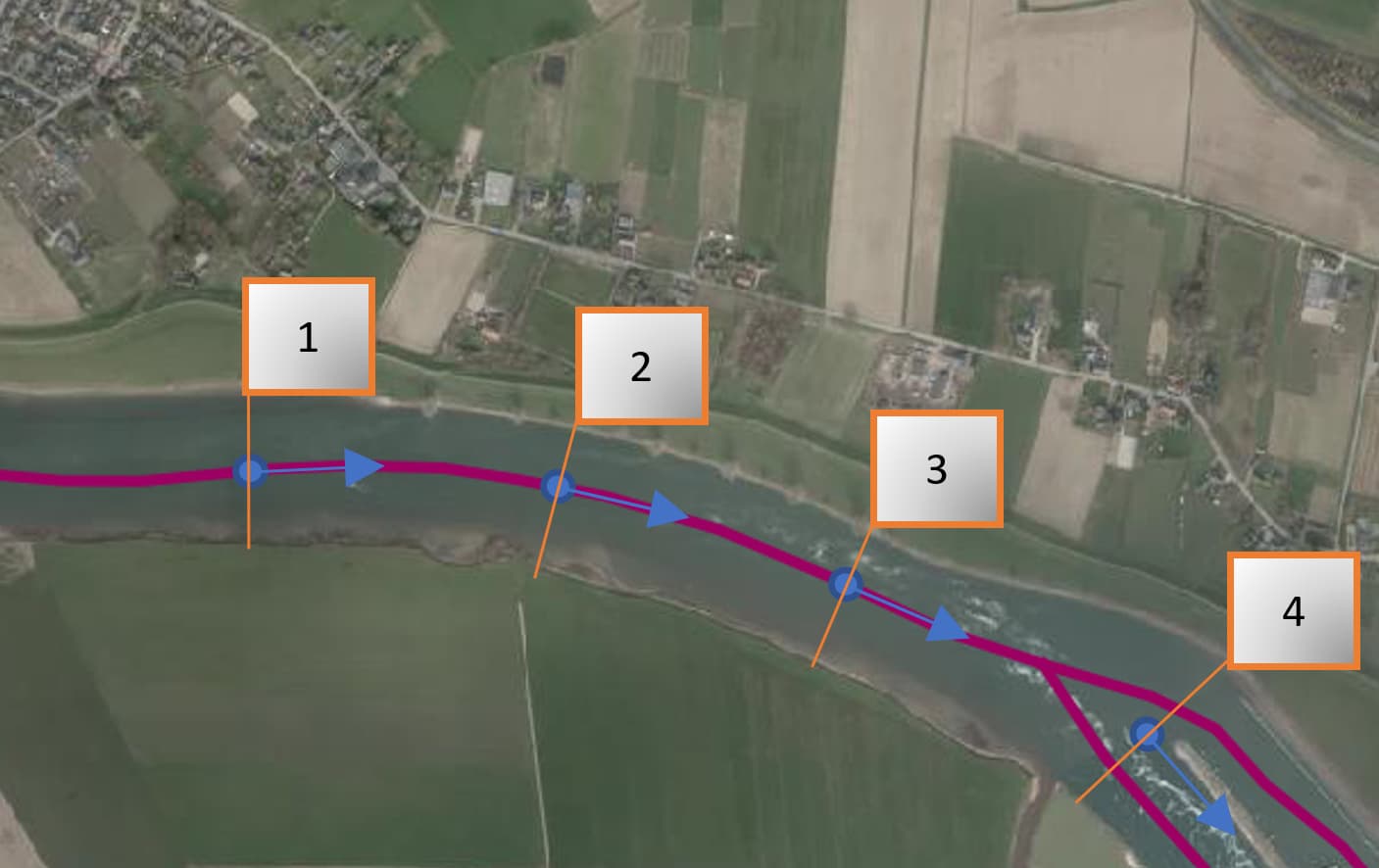
Section cut from number 2; left and right likely to be a NFS.
The 3d model:

3/ Split section cut:
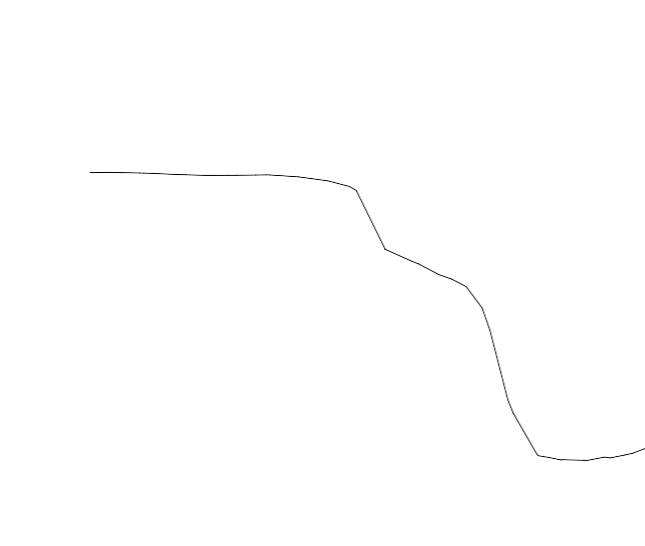
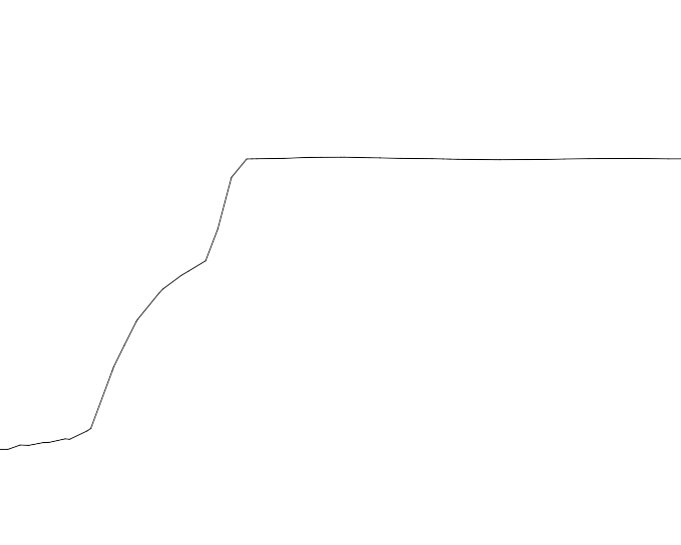
4/ We can create a X,Y plot; lets say N x point resolution per side.
With this we get a list of all section cuts and the x/y coordinates from the 2d section cut:
Section: x1 y1 x2 y2 x3 y3 until N
1Left 0 200 1 180 2 150 etc…
1Right
2L
2R etc…
De x,y coordinates will be the input layers of the model.
I have some geo data that dictates, in specific area’s, which parts are NFS’s. So I could use this to create a learning dataset.
Questions if you think this is a good plan of attack:
1/ How do I automate the conversion from XYZ 3D data to section cuts based on the vectors? I think I have the data i need, but how to convert it to XYZ 2D lets say? There should also be a geo element to this; because I need to now the geo location of each and every section cut!
2/ I have no idea of performance. The section cuts I placed above have a per side resolution of around 25 (50 in total) So there will be 25*2 input layers (2 because of x AND y)
I don’t mind if the whole river takes a week to calculate. Months on the contrary would be a little bit too long ![]()
I would really appreciate any and all input !
Thanks in advance!!
 ).
). If you want to stay in python to do the conversion, maybe
If you want to stay in python to do the conversion, maybe 

 And thanks for the update, great that it begins to work out!
And thanks for the update, great that it begins to work out!


 I’d suggest: just try what you have now and finetune later!
I’d suggest: just try what you have now and finetune later!