I am in a trouble. I am studying the feasibility of creating and applying an Artificial Neural Network to do a time series model. In my workflow the first step is creating across optimization the best Artificial Neural Network, which includes given its architecture 425 differents models. Only for a SKU it takes approximately 3 minutes to find the best model in my laptop. That’s fine if It needed to predict the demand for a product, but the project is designed to do it for 25,000 SKU. So using my laptop that is not feasibility. A few weeks ago I knew about Knime in Amazon Web Servise. I bought an acount and with a friend who is expert in cloud computing we were configuring an instance with 72 cpu (A big machine) but unfortunatelly it didn´t work. Time to finish training ANN was the same because that virtual machine doesn´t parallelize. In other words, my project is not feasibility because its not logic to have a sale´s prediction out of time.
I need to know how can I do a workflow in AWS (I have the workflow ready and it is working) that could parallelize. I need to reduce timing to train and apply the model to 3 minutes for SKU to 3 seconds at least.
No, but since you told me I did it. I tried on my laptop and it took the same time. It woulb be change If I use Pararell Chunk Start and Parallel Chunck End Nodes in “the cloud” that is ti say AWS?
In my mind, I imagine myself being able to deliver the task to different computers that are very powerful. Will something like that come, Knime? For example, to a computer to pass the flow with the first 100 products and at the same time to another computer another 100 and so to finish with the 25,000 products or SKU. It could do that with a node???
I will think about an example of how to set up a parallel chunk to split up the tasks. Another possibility could be to call sub workflows with parameters. Would have to use some configuration.
Other things to explore could be:
make sure you give the KNIME on the server all the power configuration it could use (especially RAM)
force KNIME to do everything in memory at the nodes
think about using batch workflows so they would run without the graphical overhead and feedback
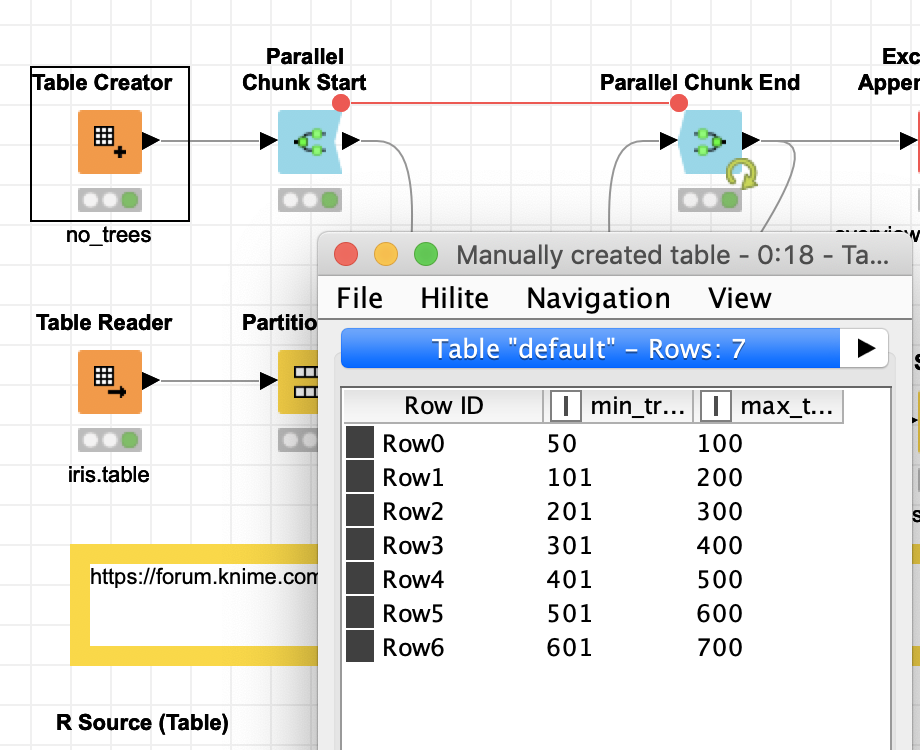
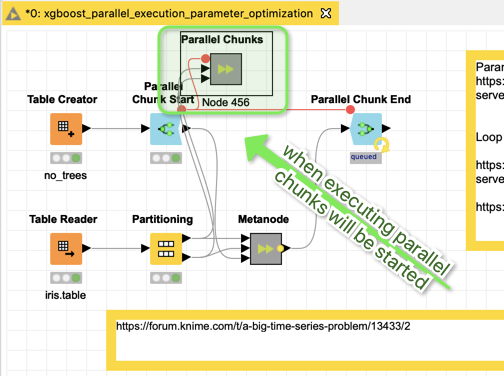
I put an example together you might try with parallel chunks (might be good to increase the number of maximum working threads on your powerful machine).
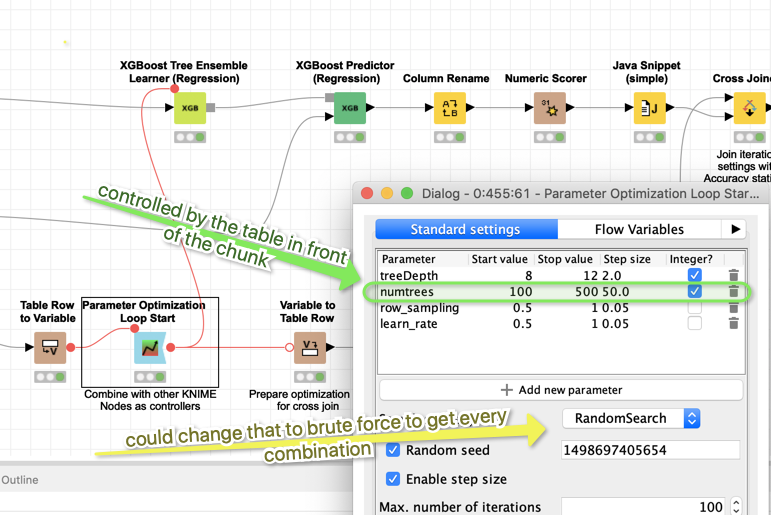
This workflow combines a meta table with (in this case) various depth of trees (you might use other settings) - for your case this might be quite a long list since this is where the parallel chunks will be drawn from (you can control the number of chunks KNIME would start parallel or you let KNIME decide)
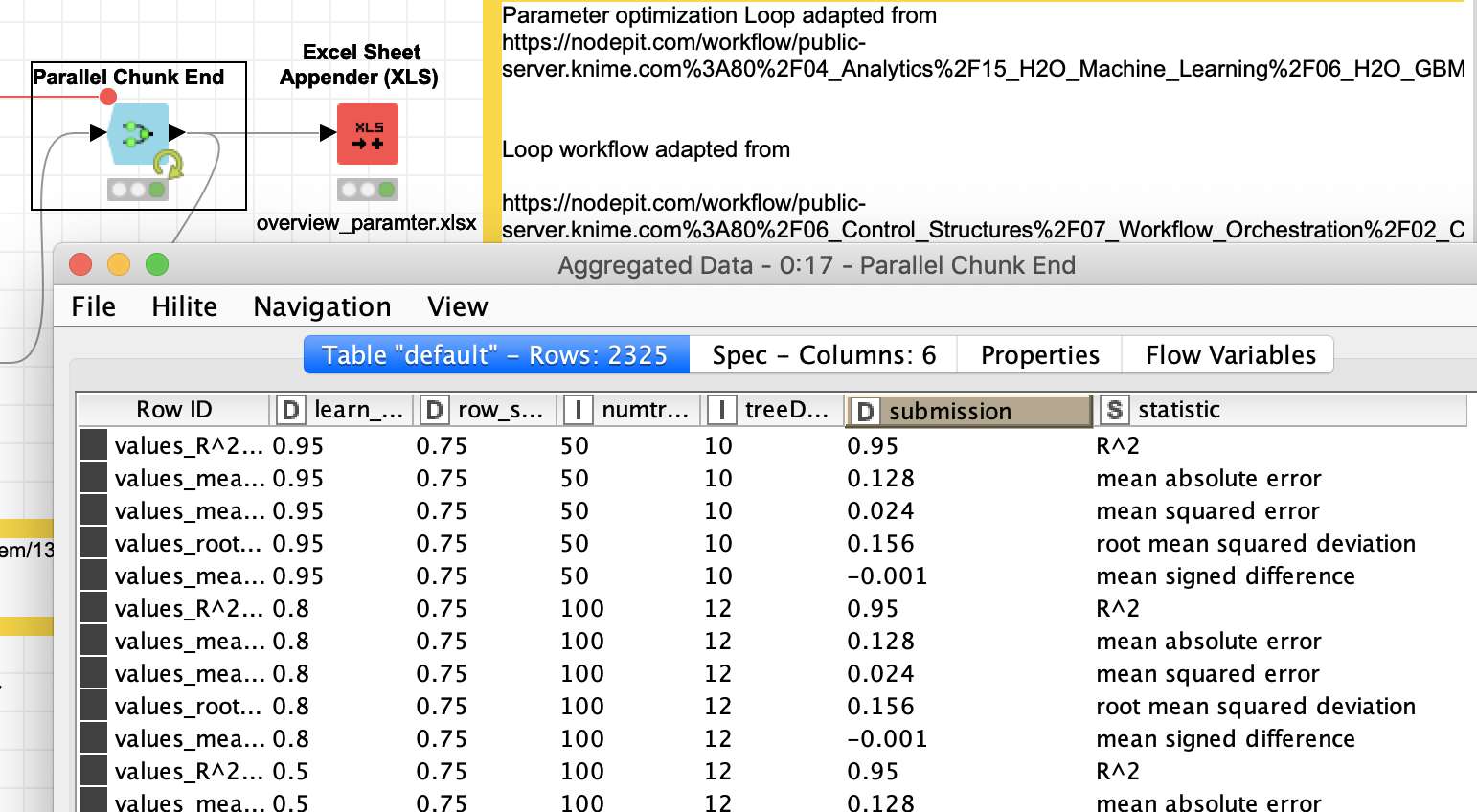
Inside the Metanode that will be the base for the chunk loop we have a Parameter Optimization loop that would test all the variants we want with the limitations of the settings from the initial table. So you could cascade more searches and see what your server does with that.
In the end the loop would have produced a large list of combinations it had tried and kept a record of the success (in this case for the iris dataset the hyper parameter optimisation does not make any real difference - it was just used as an example).
I also set all the nodes so that they would keep the data in memory to speed up the process (of course that depends on your machine)
You could think about starting such a workflow in batch mode to speed things up. Also with regards to your idea of using several powerful machines you could have several of these workflows with a (meta-)chunk of you parameter world and you would send each one of them to a separate computer in order to collect the results.
For educational purposes here comes the ‘server’ variant calling sub-workflows but the description says it will only execute in parallel if it is run on a KNIME server.
Seems like you are in some trouble because from 3 minutes to 3 seconds is a big gap to overcome. But there is a chance What is your target time for all 25.000 SKUs?
Start by:
1.) Finding bottlenecks in workflow and speed them up!
2.) Configure knime.ini file
3.) Parallelize
I changed in Preferences: “Maximum working threads for all nodes” from 8 to 24 as you show it. I am not yet know what that mean.
I realiaze that in every node it could change in the tab Memory Police: “Keep all in memory”, but it is a little slow going changing every node one by one. Do you know if that could be done to ALL nodes at once?
Thanks for your tips. I am going to follow them, I configured knime.ini Xmx12132m is it that ok?
Can you tell me how to find bottlenecks in a workflow?
Now I am using Parallel Chunk Node, but just in mi local machine I have not yet tried in the virtual machine in the cloud.
My target time for all 25.000 SKUs is at least 24 hours.
You could try to further increase that number depending on your machine and task. In the end you need to find an optional setting. You will have to explore a combination of CPU, RAM, IO number of jobs and also setup like if the jobs would involve heavy writing on a disc, if you have an SSD how a virtual machine handles that (if you use AWS).


 What is your target time for all 25.000 SKUs?
What is your target time for all 25.000 SKUs?