Dear KNIME Development Team,
I have been using KNIME since 2018. Watching a platform grow, improve, and gain new features is a wonderful thing — and I truly appreciate your continued efforts.
BUT…!
There’s a critical problem I feel must be voiced — especially on behalf of users like myself who manage hundreds or even thousands of workflows.
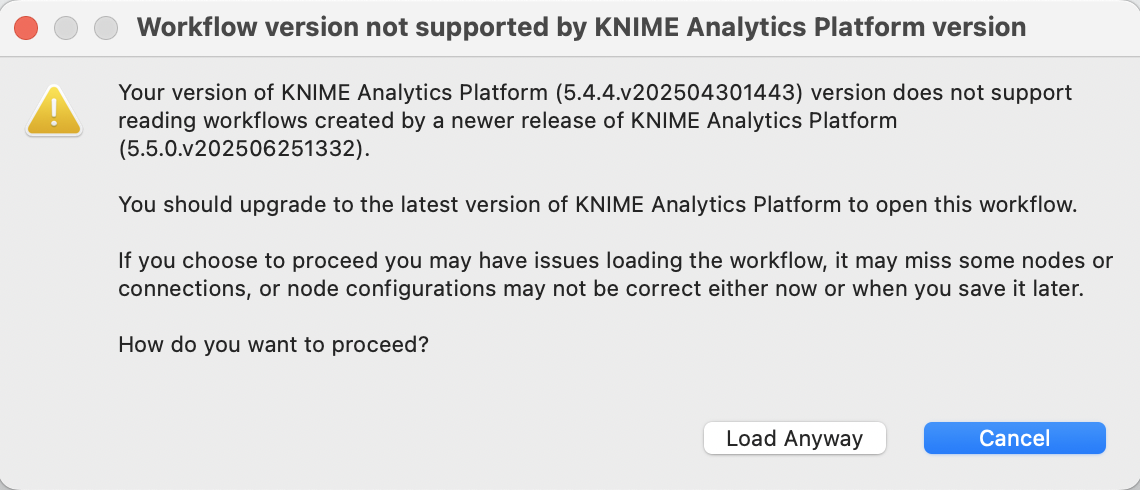
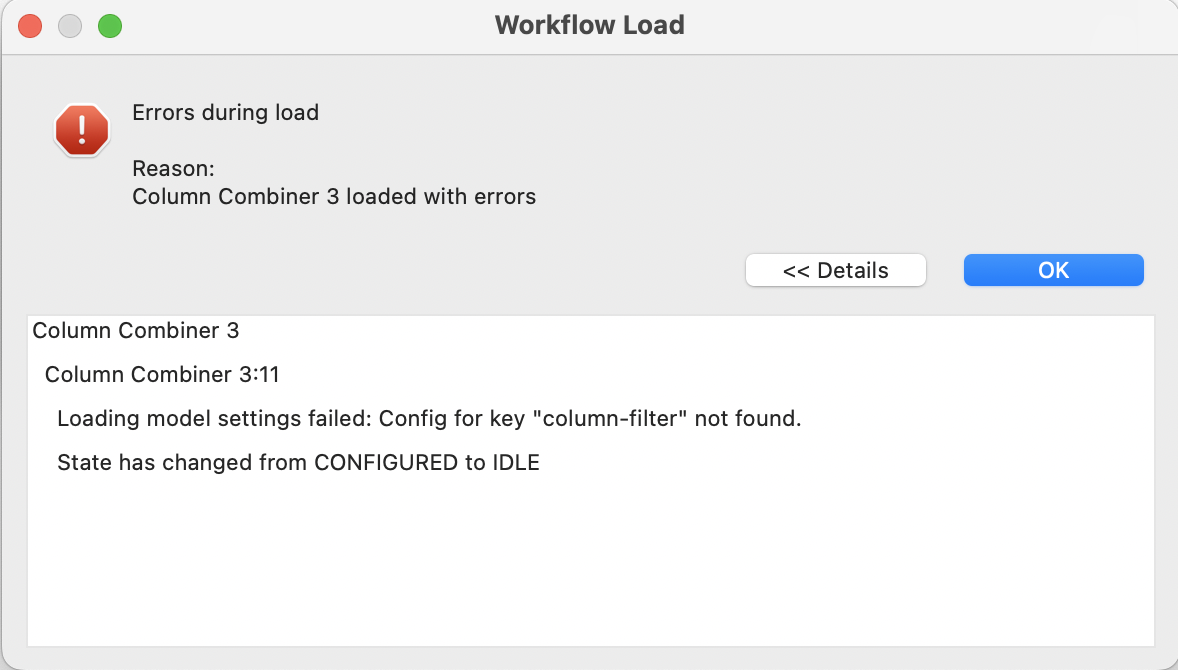
If each new update causes previously working nodes to break or behave inconsistently, this is not just a minor bug — it’s a serious issue.
Every time you change the interface or underlying mechanics of a node, there is a high risk of introducing subtle bugs or unexpected behavior. I’ve noticed this in the past with specific nodes and raised similar concerns during previous updates.
When I build a workflow today, I do so with the latest and best available tools — but an update tomorrow might break that very same workflow. Detecting such issues across thousands of workflows is like finding a needle in a haystack — or playing bingo with broken nodes.
As I close, I want the QA and development teams to please remember:
Even a small UI tweak or functional change — if not thoroughly tested for backward compatibility — can lead to massive time loss, wasted effort, and user frustration. Fixing these problems takes hours or even days for users. Please don’t underestimate this impact.
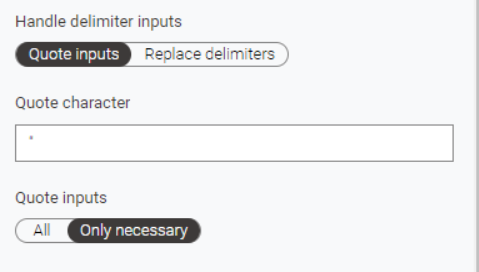
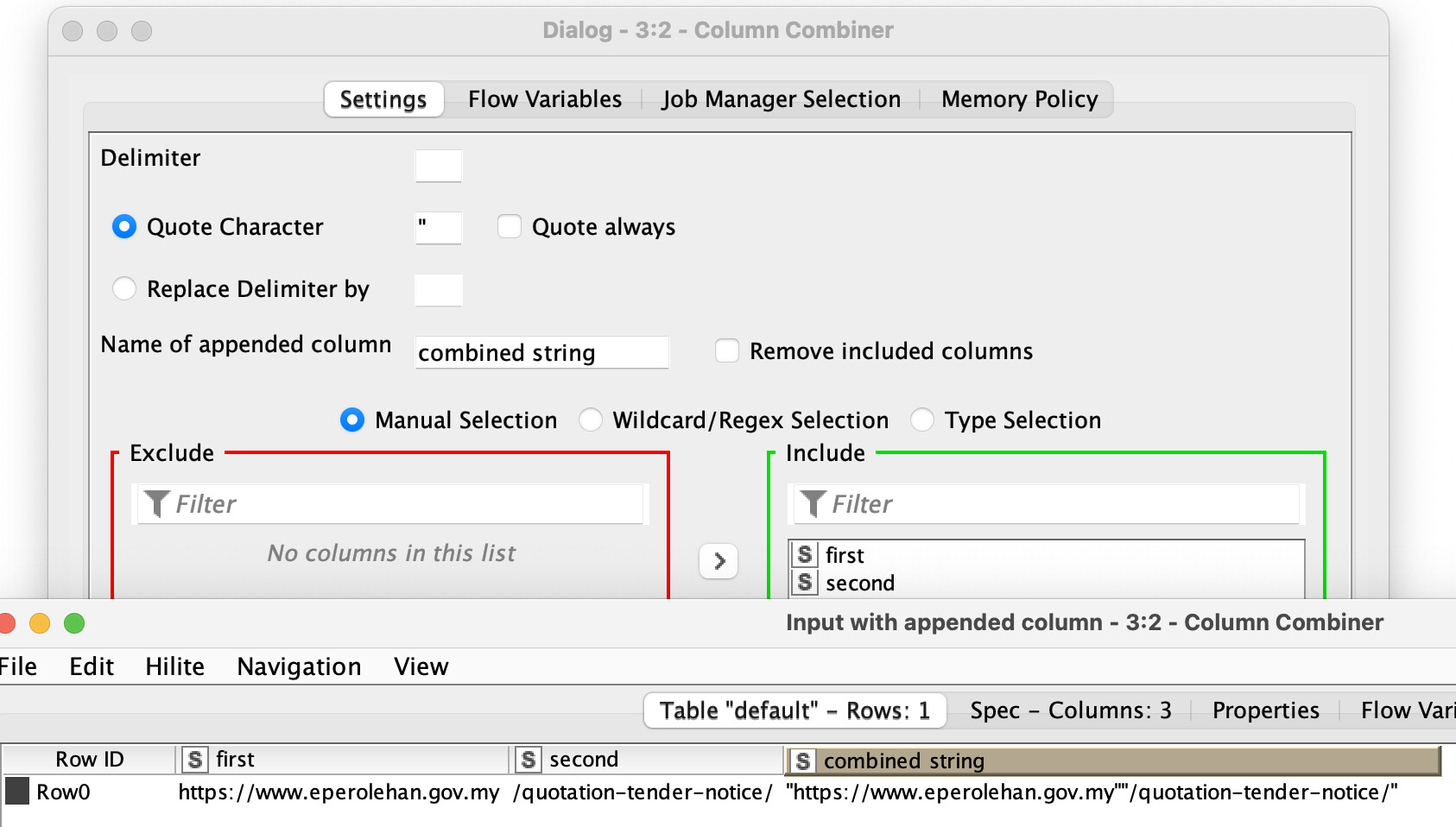
Current problematic node: Column Combiner
Try combining two columns without any separator using the previous version of this node, and then try the same with the latest version. Do you get the same result? Probably not. That’s exactly the problem.
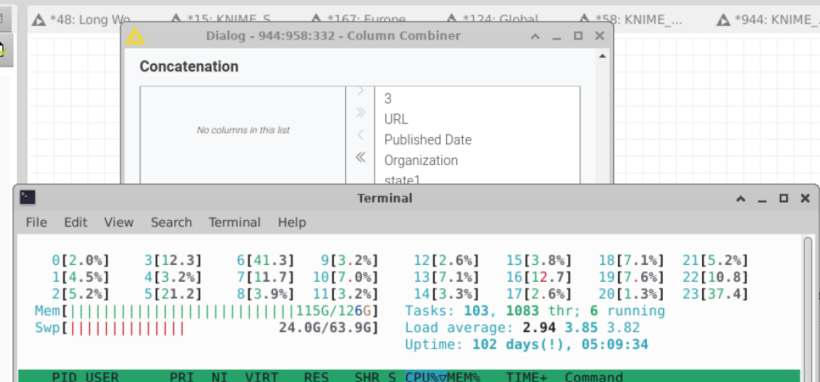
Additionally, the interface in the updated nodes loads slowly. The tested device’s details are shown in the image. The system is Ubuntu.
With all due respect and appreciation for your work,
Sincerely,