Hi everyone,
I wonder that Do all the DB Nodes like DB Reader vs. execute a query in the corresponding database engine or in KNIME? Does anyone have an idea?
Best,
Hi everyone,
I wonder that Do all the DB Nodes like DB Reader vs. execute a query in the corresponding database engine or in KNIME? Does anyone have an idea?
Best,
@KKERROXXX the query would be executed on the correspomding database. If you want to explore that further I have a collection about KNIME and databases
To start you might want to check out the Database extension guide
https://docs.knime.com/latest/db_extension_guide/index.html?u=mlauber71
Or you might want to try a small example with a local database that ‘ives’ in a single file (without the need for installation)
Thank for your response @mlauber71,
You mean that when a query executes in a DB nodes in KNIME AP, the corresponding query will be executed on ORACLE SQL Database engine not in KNIME AP, right? For me, KNIME AP just take the result from the Oracle SQL Database?
I will look at your workflows asap.
Best,
yes this is how it works. The nice thing is you can use all the KNIME features like Flow Variables and combine them with the DB nodes that could substitute writing SQL code on your own. But you are also free to write your own SQL statements. If you use the dedicated DB nodes (with the brown ports) you can use them on different data bases and KNIME (and the drivers) will make sure they do work.
And if you are done with the database doing all the work you can use all the other KNIME functions to work with the results.
Hi @mlauber71,
One last thing, to prove that a query executes in Oracle DB, what can I do? I use sql developer, when I execute a query by using DB Reader, can I see any log about this operation in sql developer?
Best,
Hi @KKERROXXX , I’m wondering what sort of proof you are needing… Clearly when we run a query and it retrieves data from Oracle, it must be making the request to Oracle in order to get the data out. There isn’t any other way of getting data out of an Oracle database, so I maybe this isn’t the question you are asking.
But let me try to find a couple of things that would “prove” that this occurs.
Assuming you have access to some of the dba views such as v$session and v$sql, you could try this:
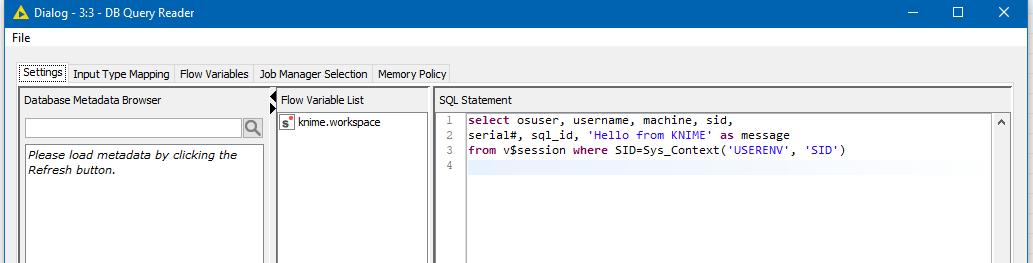
Create an Oracle Connector and put in your database and credentials, then attach to it a DB Query Reader as follows:
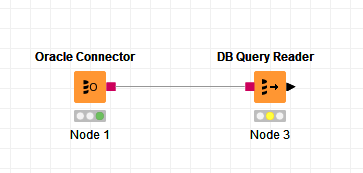
Into the DB Query Reader, enter the following SQL:
select osuser, username, machine, sid,
serial#, sql_id, 'Hello from KNIME' as message
from v$session where SID=Sys_Context('USERENV', 'SID')
Then execute the query
You should get back a result such as this:
The SQL_ID is Oracle’s id for the specific SQL statement that you have just executed.
So, copy the value from the SQL_ID column into clipboard, then head over to SQL Developer and enter the following query,
SELECT * FROM V$SQL WHERE sql_id='f5j4z9xrtnydn';
Obviously replacing the sql id value with your value.
SQL Developer will return you a result set showing the SQL that was executed against the database (i.e. the query from the DB Query Reader
So that demonstrated, I believe that this particular piece of SQL was known to Oracle, and was now residing in Oracle’s SQL area, having executed it in the database.
However, if you are anything like me, I wonder if the question you are really asking is whether JOINS are executed on the database, or in KNIME. The answer to that is that data retrieved from the nodes with a black output triangle are returning data to KNIME and any subsequent joining of data is done by KNIME, and not in the database.
However, the “in database” nodes, which have the brown output connectors DO perform the joins in the database. So how can I prove that?
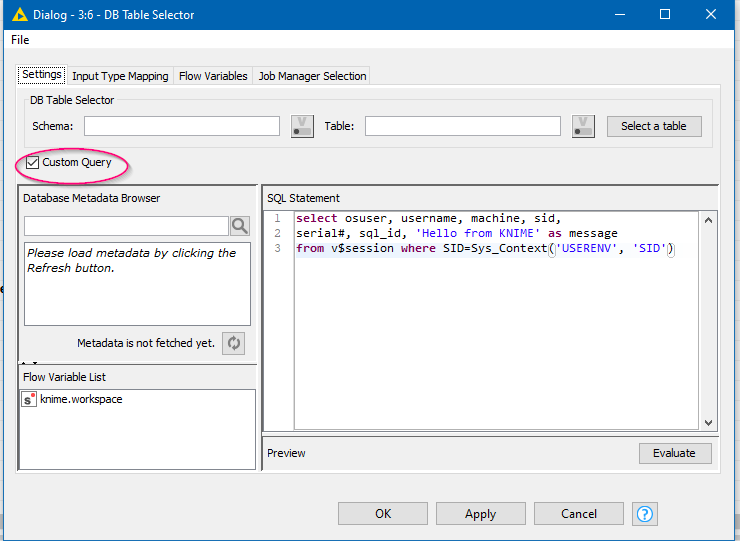
Well, once again use your Oracle Connector, but this time attach it to two DB Table Selector nodes. Then attach each of the DB Table Selectors to a DB Joiner, and finally attach the DB Joiner to a DB Reader.
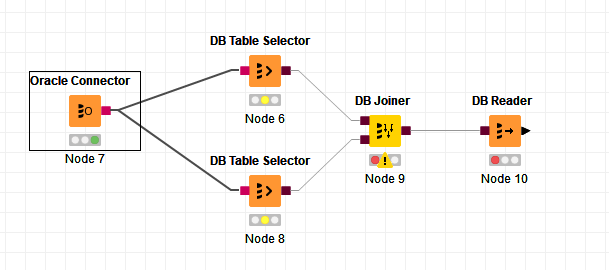
Into the first (top in my screenshot) DB Table Selector, enter the same query as we used just now:
select osuser, username, machine, sid,
serial#, sql_id, 'Hello from KNIME' as message
from v$session where SID=Sys_Context('USERENV', 'SID')
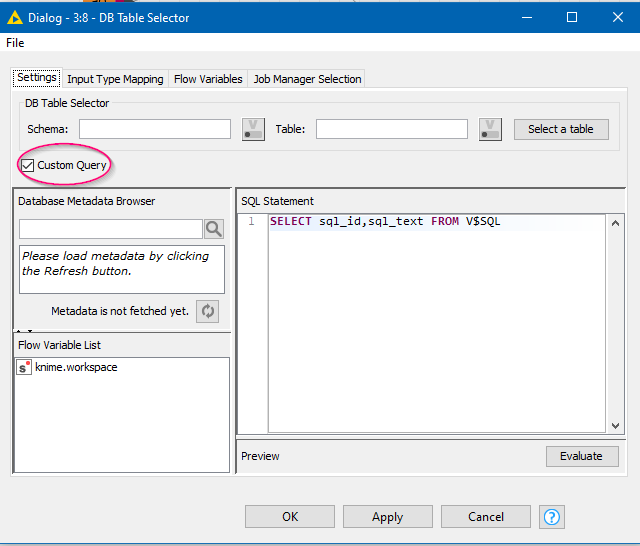
Into the lower DB Table Selector, enter the query:
SELECT sql_id,sql_text FROM V$SQL
Each of these two nodes look like they will execute individual statements and that they would be joined by KNIME. But they won’t. These nodes work together and KNIME creates the SQL statement so that the join is performed on Oracle, by wrapping these with additional SQL.
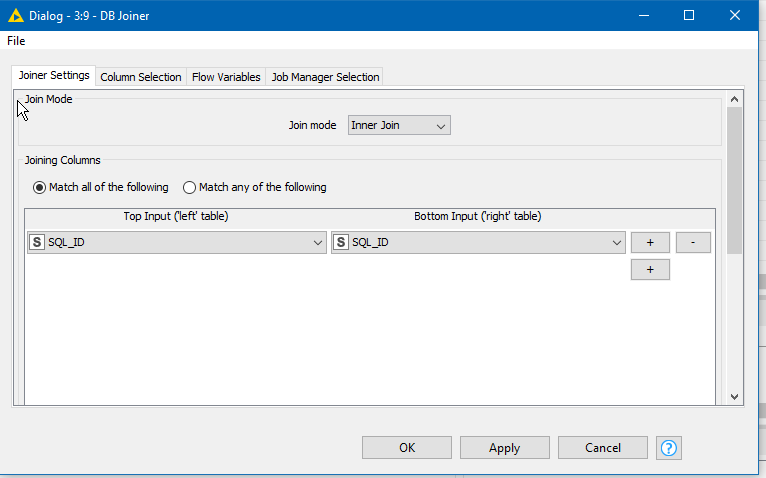
Go to the DB Joiner, and configure this node so that SQL_ID from both DB Table Selectors is used as the joining column:
Then go execute the DB Reader node. Inspect the output from this node
and once again copy the SQL_ID from this node to clipboard. Go back to SQL Developer and paste that new sql_id into the query we used last time, and execute it:
You’ll see there is quite a large piece of sql produced. If you were to copy that sql to clipboard and paste it into an editor, and reformat it into something a little more readable, it will look something like this:
SELECT
"tempTable_7769992362885823591"."OSUSER" AS "OSUSER",
"tempTable_7769992362885823591"."USERNAME" AS "USERNAME",
"tempTable_7769992362885823591"."MACHINE" AS "MACHINE",
"tempTable_7769992362885823591"."SID" AS "SID",
"tempTable_7769992362885823591"."SERIAL#" AS "SERIAL#",
"tempTable_7769992362885823591"."SQL_ID" AS "SQL_ID",
"tempTable_7769992362885823591"."MESSAGE" AS "MESSAGE",
"tempTable_2879647759173066582"."SQL_TEXT" AS "SQL_TEXT"
FROM (select osuser, username, machine, sid,
serial#, sql_id, 'Hello from KNIME' as message
from v$session where SID=Sys_Context('USERENV', 'SID')
) "tempTable_7769992362885823591"
JOIN
(SELECT sql_id,sql_text FROM V$SQL ) "tempTable_2879647759173066582"
ON "tempTable_7769992362885823591"."SQL_ID"="tempTable_2879647759173066582"."SQL_ID"
So there, we have proof that a pair of individual select statements are have been executed by Oracle as a combined (joined) query “in database” in order to return the data to you.
I hope that helps.
I think execution time proves it. Otherwise KNIME would really use some magic underneath ![]()
Br,
Ivan
Hi @takbb,
Firstly, thank you for your well explained answer!
But, when I run the below query in DB Query Reader and DB Table Selector Nodes
select osuser, username, machine, sid,
serial#, sql_id, 'Hello from KNIME' as message
from v$session where SID=Sys_Context('USERENV', 'SID')
corresponding node throws an error like
ORA-00942: table or view does not exist
What can I do at this point?
Best,
Hi @KKERROXXX , yes that will be because you don’t have access to the v$session view, which you need to be granted by the DBA. As I mentioned, this post assumes you have access to the necessary dba views.
However, on the plus side, it has proved that the query was running on Oracle, since Oracle returned an error code! 
The information you need is effectively in those system views so
you will need to execute the following as a dba user:
grant SELECT ANY DICTIONARY to username;
or alternatively
grant SELECT ON SYS.V_$SESSION TO username;
grant SELECT ON SYS.V_$SQL TO username;
v$session and v$sql are synonyms to the sys.v_$session and sys.v_$sql views.
If you cannot be granted access on your current database, all I can really do is suggest installing a local copy of Oracle on your pc (where you will then have dba access), for the purposes of this demonstration. Whether that’s worth the effort depends on how far you need to go with this.
I hope that helps
@takbb to clarification,
I write sample query in DB Reader Node given below,
and go back to SQL Developer and execute a query to given below
![]()
and the query written in KNIME DB Query Node can be seen like below
So, seeing this query in V$SQL table, does it proves that this code coming from KNIME DB Query Reader executes in the database?
Best,
@KKERROXXX, yes it does.
That view shows the sql that has been executed recently.
One of the reasons it’s stored here is so that if exactly the same query is seen again, while it’s still in the sql area, oracle doesn’t have to waste time generating a new query execution plan as it knows it already has one available.
Simply put though, in a proper client-server database, such as SQL Server, Oracle, MySql, Postgres etc, the sql will always be executed in the database. There is no alternative to that. Security models prevent any access to the data other than through the database management system(dbms).
The exceptions are the “toy” desktop databases such as MS Access. Queries in Access run on your local PC as there is no centralised Access database system. The data itself is just stored in one big .mdb (or similar extension) file and is one of the reasons why it performs so poorly across networks and in a multi-user environment, where essentially every user is dragging this data file across the network so that their local software can process it. That’s not the case with a client-server database. Requests are made of the server in the form of SQL. The server processes that request, and returns the data. There is no ability to connect directly to “data files” so there simply is no other way for KNIME or any other tool to get to the data directly.
So @takbb, Can I call this situtation as “push-back” or “push-down”?
Best,
Hi @KKERROXXX , I’m guessing that depends on your definition of those terms
In terms of “SQL Pushback”, which my understanding from an IBM reference to this term, relates to “pushing the SQL back to the server so that it executes there”, I believe that what they mean by that is instead of streaming your data and then manipulating it locally, you get the dbms to manipulate it by sending more detailed requirement in the form of sql to the dbms.
So, say you had a table of customers and their orders.
A simple options, which are applicable to KNIME is use two DB Query Reader nodes: One is “select * from customer” and the other is “select * from cust_orders”. KNIME could then do the local merging and manipulation of that data, and if the dataset where very large, it wouldn’t be that efficient. The individual SQL statements have still been executed by the DBMS, but the joining of the data has occurred locally.
The alternatives are to hand-craft the complete SQL query that joins the two tables…
select cust.cust_id, cust.name, cust.address , ord.order_number, ord.order_date... etc from customer cust join cust_order ord on ord.cust_id=cust.cust_id
… something like that…
or you use the DB Table Selector nodes to each read the individual tables, and a DB Joiner, telling it what columns to join on and then it constructs the SQL that performs the join and sends that back to the DBMS as a sql statement to be executed.
This “pushing the join” and other data manipulations back to the database for efficiency purposes is I suspect what is meant by “push back”. Looking up a definition for “Push Down” I found very similar references to “Push Back”, that looks to me like they are synonymous. I couldn’t tell you if there is a difference between them.
Maybe share your definitions and we can put it to the vote
Based on the above, whether the situation is “push-back” or not, I would say depends on the situation.
Is the heavy-lifting work being done locally (if you are getting KNIME to join your two datasets that have been separately extracted from the database), or is it being remotely (you tell the dbms to join the datasets on your behalf and have it delivered to you as a single data set already joined)? And that all depends on which nodes you use, and what you ask of them.
One thing to keep in mind is that one can combine the KNIME DB nodes with ease and make quite complicated statements that are syntactically correct; but they still will have to be executed on the database. In case of powerful ORACLE machines you might benefit from a query optimiser that would spot that the WHERE condition you put in the last statement actually can be done in the first place, but other databases namely Big Data system (yes you Cloudera) do not have this option or only have it in an infant status so you might have to do some optimisation yourself and might have to think about creating intermediate tables and use early WHERE conditions to just access the data you really need.
Especially large joins over several tables and columns can be very costly and might need some planning and care.
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.