I’d like to propose the option to persistently mark the sensitifiy level of data. That would allow to prevent i.e. sensitive data to be passed un-anonymized to AI-Agents, providing the ability to instate safetymeasures and automations to anonymize data.
Adding to this (have discussed this with Mike and also some KNIMErs at DataHop in Stuttgart):
I feel this would be a great feature - especially in the context of working with AI Agents.
The overall story with having a data layer that allows the user to control what data (if any) gets fed to the LLM is great already. In my use case I still face a challenge that any data required to actually call a tool right now has to go to the LLM.
E.g. if my agent should create a customer record in my CRM, say for Customer “MartinDDDD” then:
MartinDDDD is typed into chat interface
It is then send to LLM
LLM generates the Payload required to call the tool (which will include the parameter e.g. customerName: MartinDDDD
The tool creates the record
I have thought about alternatives on how to implement this:
Option 1: Create a custom Agent UI (i.e. not using Agent Chat view etc), sanitise user input before it goes to the LLM (e.g. using Presidio extension) => this works for the input, but given that the tool call happens before the response gets back, this would mean that a record for the sanitised name is created (and also not using the great Chat Views / Widgets seems like a waste)
Option 2 (and this is just conceptual, probably impossible): Somehow funneling the customer name into the data layer - but this would probably mean for the user to have a form available which saves the name in e.g. .table-format in a temp location (which I understand right now is tricky as relative paths are not supported between Agent-Level WF and the Tools), then have the agent use a tool which fetches the data and in the same tool to create the record. This seems super complicated and impractical
Option 3: ignore this challenge in KNIME and e.g. use a self-hosted LLM (renting GPUs…), which will be pricey and likely not a possibility for most users
What I am thinking of how this could be solved in KNIME (possibly with a trade of in terms of increased latency):
MartinDDDD is typed into chat interface
Agent Chat View / Prompter / Chat Widget contain a setting to trigger anonymisation e.g. using Presidio under the hood => if active:
Text from Interface / Table is anonymised, temp e.g. presidio model is stored) - e.g.:
Customer_A: MartinDDDD
It is then send to LLM
LLM generates the Payload required to call the tool (which will include the anonymised parameter values e.g. customerName: Customer_A
Before tools are invoked, the temp presidio model is used to de-anonymise to turn customerName: Customer_A into customerName: MartinDDDD
The tool creates the record
I hope the above reasoning and example makes sense. Happy to explain my views in more detail
Thank you for the feedback, I like the idea of reinforcing the safety of sensitive data.
What I don’t understand, yet, is the how.
@mwiegand how do you envision to mark the sensitive data? Is that on the table level or per row or even cell?
@MartinDDDD I like option 1, it’s like a chat interface for parts of a workflow. Maybe it’s a loop start that has the chat view. It outputs the current conversation state and then the downstream nodes take care of the processing. Then you could use e.g. Presidio to handle anonymization. The loop end would collect the output and update the conversation with the message.
There are some significant technical challenges with that approach but it would be more open and flexible than the single chat view. Anyway, I am curious to hear your thoughts on that!
In general I like that option as well - although as you said it is complex and therefore probably limited to users that are super proficient with KNIME. Honestly speaking I was not able to implement this yet.
I have not had good experiences with wrapping views inside a loop to be honest, but get your point:
collect user input via e.g. string widget
anonymise and pass to chat widget / prompter => this way any personal data etc. is anonymised
use output to update some table with the history and display it
As this is very complex my proposal was to find a way to bake this into the loop that is running under the hood for chat view / widget / prompter
I’d assume that to be part of the meta data / spec table so a per column information:
I agree. I.e. transposing the data can cause the data-type to become undefined and allow cirumvention of any safety measure. Hence, I’d envision that feature more as a guide which throws warnings or even intervenes / prevents certain actions.
Yes, the current execution behavior (especially when running in AP) does not support the combination of loops and views/widgets.
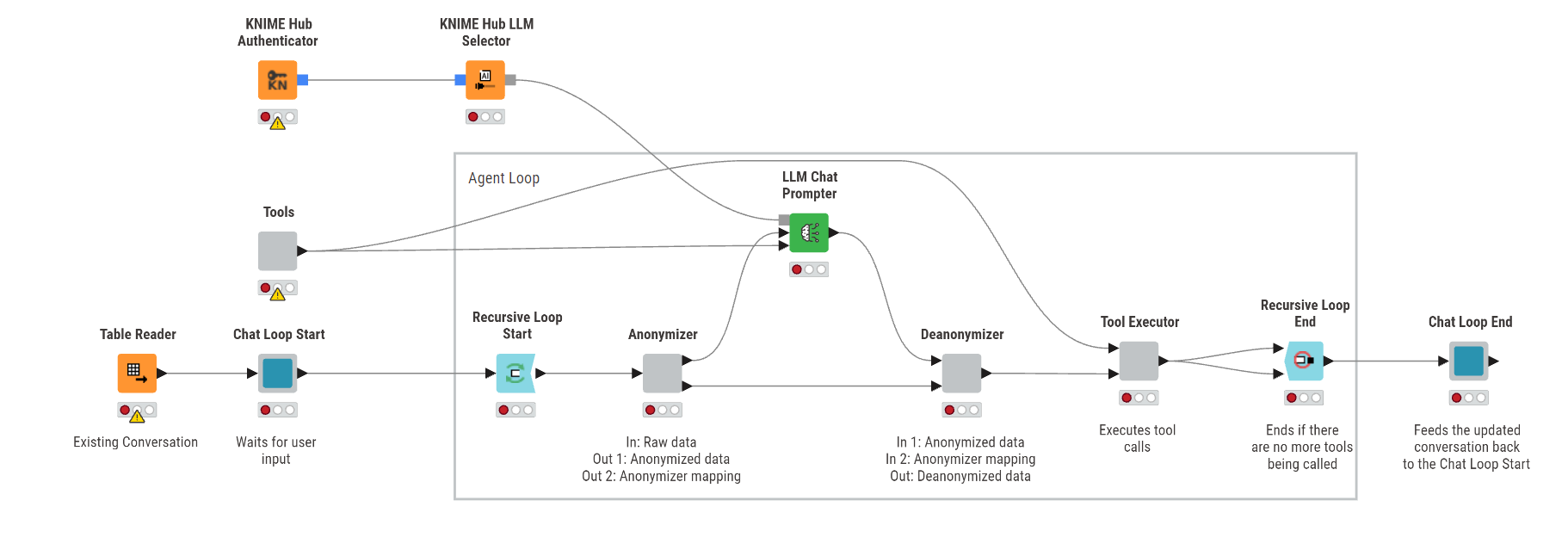
Cramming the logic into the existing nodes is difficult as well. The anonymization use-case shows that quite nicely. Ideally we would show anonymized data to the LLM and operate on the actual data in the tools, i.e. we need to anonymize before the LLM call and deanonymize after, so we can then execute the tools on the actual data. Deanonymization requires data from the anonymizer, though. Here is a screenshot of a workflow that outlines how this would work under the hood:
What I did omit here is the whole data layer functionality that our agentic framework takes care of under the hood as well. There we already hide the data so it’s secondary to the discussion of sensitive data.
At the moment the LLM only sees data that is actually passed to it via the conversation, which can happen either directly in the chat or through the Tool Message Output node in a tool.
Would the Tool Message Output node be the one that would raise an error if it encounters sensitive data, or are you envisioning something else?
Given the complexity of even defining the boundaries or non-goals, especially when it’s a build in process working it’s magic in the background, maybe a dedicated node to classify PII/PI would be the way to go.
Let me elaborate on this. Envision you’ve got the following data scenarios:
Personally Identifiable Information “PII”
Data marked as strictly confidential / sensitive like: Full name, Social Security number (SSN), Driver’s license, Mailing address, Credit card information, Passport information, Financial information, Medical records etc.
Personal Information “PI”: Non-Sensitive Data
Names, Birthdates, Gender, Postcodes etc.
Statistical data
Aggregates like number of male or female persons per ZIP Code
Upon ingestion a node injects or auto classifies, based on pattern matching, the sensitivity as meta information to each column. Upon the data is passed down the workflow, PII i.e. could be strictly prohibited by global system settings to be passed to external services until explicitly allowed, transposed (removing sensitivity meta data) or saved i.e. in CSV providing a guard rail framwork.
PI data in contrast can be passed, transposed etc. but upon a certain amount of metrics are re-combined, possibly resulting in de-identification, like:
Gender
Zip Code
Age
Income
These actions must be prohibited. That would neccesitate a global process which acts as a safeguard of all nodes, like invoking a breakpoint. Eventually teh authors of the @Redfield extension could chime in on that as they clearly have an advantage over “data-novices” like me xD
Some sources I found which I found tremendously informative:
That’s exactly the use case I envison when making my first comment - certainly implementing this - in whatever way - is going to be a big challenge. The screenshot you have posted of your concept also resonates well with me - that said I am fairly sure that very few people will be able to implement this. If the functionality was there, example workflows paired with components that hide some of the complexity may make it much more accessible, but to achieve this in true no code / low code fashion and make it super accessible to citizen developers I think the best option would be to embedd this into an existing node. This certainly is a feature that I am not aware exists anywhere else, but from my perspective would add immense value especially for users within EU that are subject to GDPR.
Even when it could be implemented I am not certain how well it would perform - that’s just a whole different topics how well the LLMs are able to integrate placeholders into the JSON objects to be returned for tool calls…
For our GenAI Gateway we had the idea to register workflows as models, which could then perform this kind of sanitization or connect to custom LLM APIs that are not widely supported.