This night I found myself incapable of solving likely the very basic task with KNIME – I don’t know why I found it complex. I lough out loud on myself when in 2 hours I couldn’t find out how to do the following:
I have let’s say 2 columns
Column 1 | Column 2
A ---------------1
B--------------- F
C--------------- N
I’d like to make a table with just one column:
Column 1
A
B
C
1
F
N
I planned to continue my search for the solution in the morning but I’m afraid I will spend another couple of hours searching for obvious node. Please help me
Use -Extract Column Header- node → then apply -Column Splitter- on table with generic header → Concatenate the two Tables obtained from the splitter (This should provide the single desired unique column) → use -Insert Column Header- node to put back the header.
Sorry for my quick reply without workflow. May be there is a simpler way to do it but this is what came to my mind first.
Hope it helps. Otherwise I’m sure other solutions will be posted.
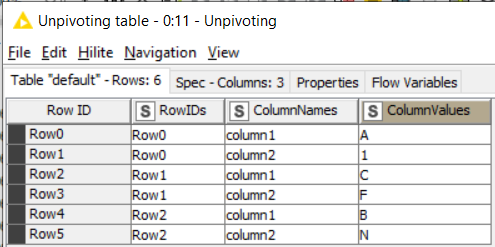
your task sounds like the perfect description for the Unpivoting node
In the upper part of the configuration window you can select the value columns. These are the columns which will be written below each other.
In the lower part you can select the retained columns. These are the columns which will be kept from the the original table and will be added accordingly to each row.
Thank you very much, @aworker , @HansS , @Kathrin !
I will try all proposed solutions. Now I’m not so ashamed of myself - the task wasn’t as easy as I expected
I would first ask @DmitryIvanov76 if it’ll always be 2 columns only, or there could be more than 2 columns to merge into 1 column?
@aworker 's suggestion is what I was thinking of (probably unpivot would do as per @Kathrin , but personally I’m not favouring Pivot/Unpivot simply because I’m not familiar with them - I understand transpose, but never got to understand Pivot), but if it will be a lot more columns than just 2, or the number of columns could vary, then @HansS 's solution with loop would tackle that.
Hi @bruno29a ! Happy to see you.
Certainly, it would be better to have solution allowing to work with 1+ number of columns.
In my case the question arose when I worked with networks - at night I solve this issue professionally unprofessional
I split the table by columns, then renamed “Column 2” as “Column 1” and finally concentrate two tables with columns 1 in a single table. I suppose noone would say that this is a good apporach, but it worked at night (I desperately tried to test if I can make it or not).
Just for information to future readers, @Kathrin’s solution using an -Unpoviting- node does the generic job (as many columns as required) in only one go without need of loops. To get the rows in the right order you would just need to sort them by the newly created column called “Column Names”. @Kathrin’s solution is hence for me the most “professional” and the fastest one
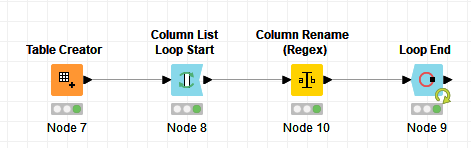
Loop with Column Rename (Regex) worked perfectly with 3+ columns. Regex is still a magic to me despite I made several attempts to learn it.
I absolutely agree with you on Unpivoting solution! It works and likely will be faster than loop, but I can’t mark two solutions in one topic. It would be great to have a kind of video/sample on Unpivoting node. I suppose that a lot of users consider Unpivoting as just a method of getting the table back to normal after pivoting and don’t think that this node is much more powerful. Personally, I will play with unpivoting node and try to implement it in my workflows.
Hey @aworker , I’d argue if the unpivot solution would indeed be the fastest one or not.
The unpivot itself is probably the fastest one, but obviously the solution would not be just to unpivot.
It comes down to number of columns vs number of rows. For the final solution, using unpivot means you have to then apply the sort that you mentioned, and probably to want to also sort by Row Key after sorting on the ColumnNames to be on the safe side. With a large number of rows, the 2 sorts could be slower. In addition, you have to apply column filters, since we want to end up with 1 column, so implementation for row filter could become a problem if the original columns aren’t always the same.
So, I’d say, debatable if it’s the fastest one
EDIT: Also just realized something, sort by ColumnNames would only work if your first column name is < your second column name < your third column name, etc.
It’s working here because alphabetically, Column1 < Column2
You agree with me on what I meant about -Unpivoting-
Yes indeed, but as I previously said, one just would need to use the -Extract Header- node to be in this case. This is cost-less and makes the solution generic.
If I had many columns and rows, I would go for the -Unpivoting- solution rather than using loops. My experience with loops is that they are almost always slower than solutions without them. But definitely, this may be sometimes data dependent and one would need to implement both solutions and test them in parallel with meaningful data to know exactly which one is best.
Just to end, I believe people have here now enough hints to try and chose the solution that fits best to them
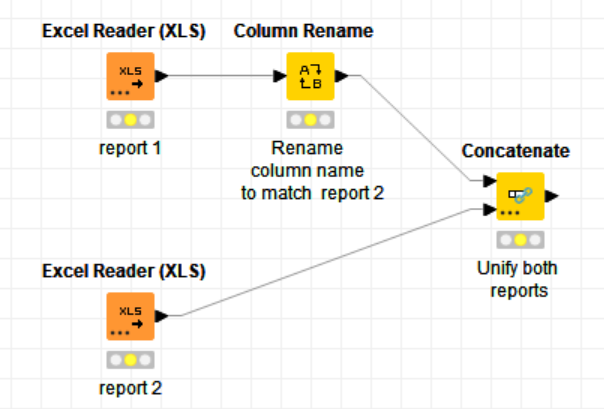
Hello, i learned this trick. If this is only unifying two columns in one, what you need is to have both columns with the same name and then, use the concatenate node under that name.
Thank you! Simple, quick, works with let’s say 2-5 columns (as the node allows adding more inputs and certainly we can add more Concentrate nodes to the workflow).
Thank you for sharing your trick. That’s exactly what @aworker 's and @HansS 's solutions are both doing
In @HansS case, Knime is doing the concatenation in the background, but with his loop, you don’t have to rename each column one by one individually. You can have 2 columns, or 100 columns, it does not matter, the workflow will automatically work for 2 columns, or 100 columns or any number of columns
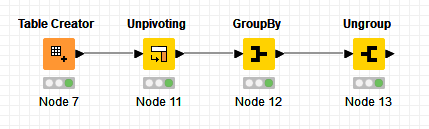
Nice discussion and ideas. Definitely not easy as expected. (Think expectation is to be as easy as many other manipulations are easy with KNIME.) Here is solution with Unpivoting (worth learning more about this operation along with pivoting!) followed by GroupBy and Ungroup nodes to have original row order.


 ? I was wondering
? I was wondering