Hi, I am trying to do the following for my table
current version:
Column1| clumn2|column3
row1value|row1value|row1value
row2value|row2value|row2value
row3value|row3value|row3value
I want to take all the values and put them on the right side of the row 1 values as follows and make one giant line:
Column1| clumn2|column3|Column1| clumn2|column3|Column1| clumn2|column3
row1value|row1value|row1value|row2value|row2value|row2value|row3value|row3value|row3value|
@takbb Thank you so much for your quick reply! That works perfectly! I just have one other question!
what I just asked you is a small piece in a bigger problem that I have. I have this giant dataset that I am trying split into smaller chunks based on their id and for the ones that have the same id perform what you just told me do (put everything with the same id in one long row)! I am using group loop start with only ID included and putting your loop within it but for some reason it doesn’t work. Do you happen to know what I am doing wrong here?
I’m trying to picture what you mean here, and what your data looks like.
So you have a set of rows something like this:
and you are using IDCol as the grouping ID, so you then process within the inner loop all rows sharing the same IDCol, in an attempt to make a single long row for each value of IDCol? Does that describe it?
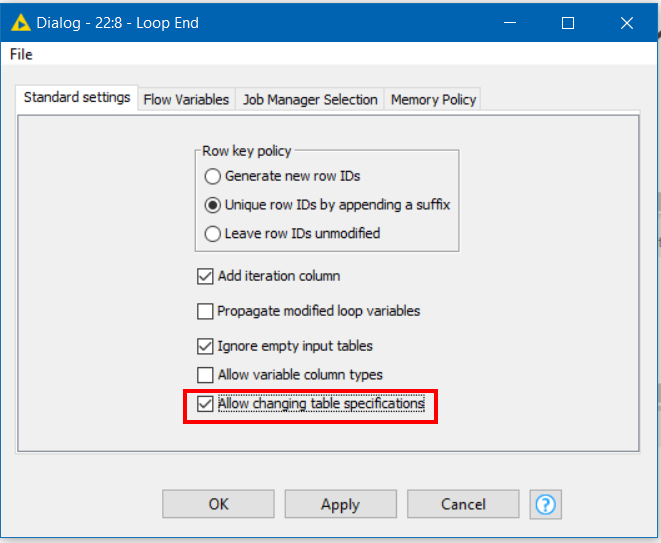
If so, I suspect the error you are seeing on the second loop end is
Input table’s structure differs from reference (first iteration) table: different column counts
That would occur if you have a different number of rows per IDCol as I have in my example screenshot, as the outer loop is then trying to create a single table with varying numbers of columns per row.