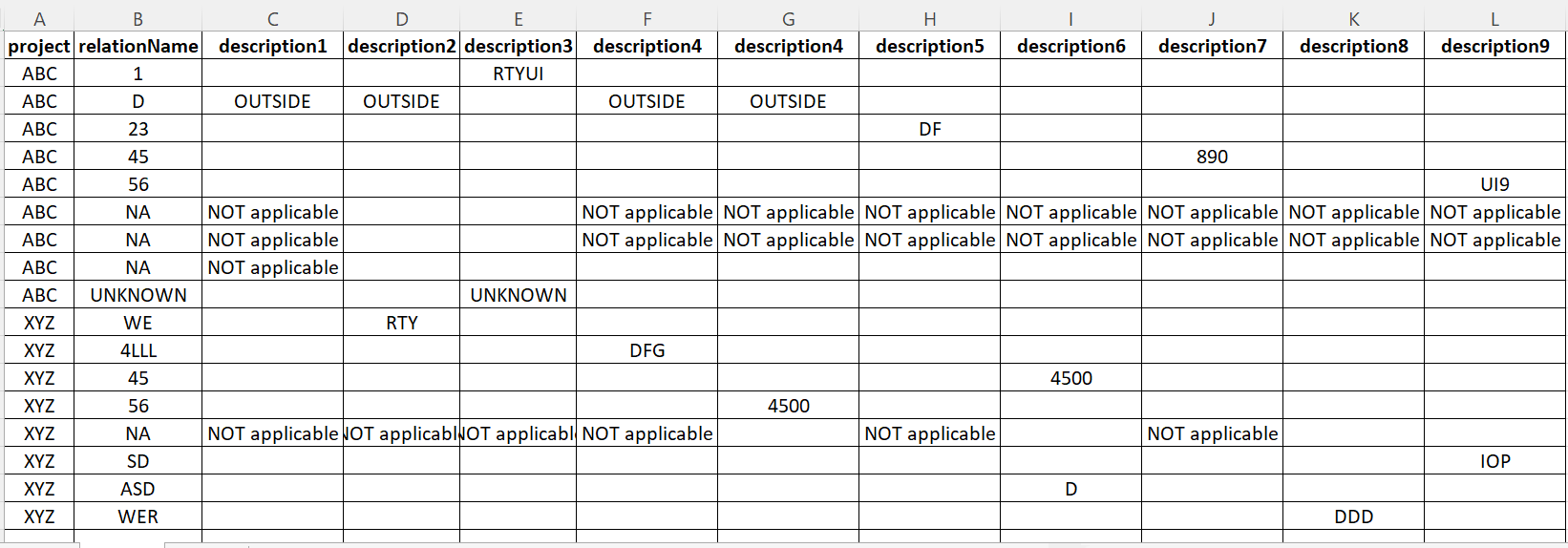
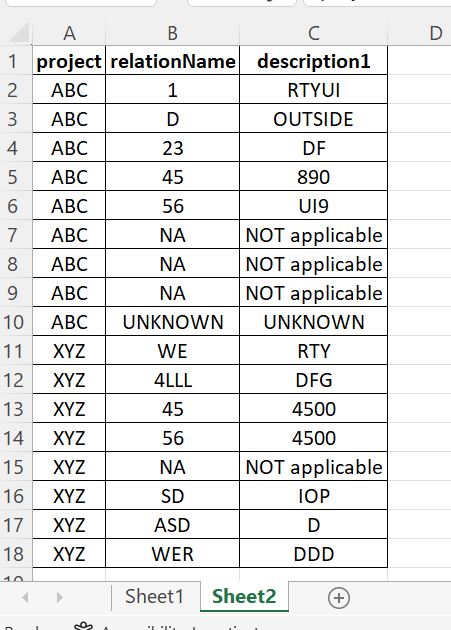
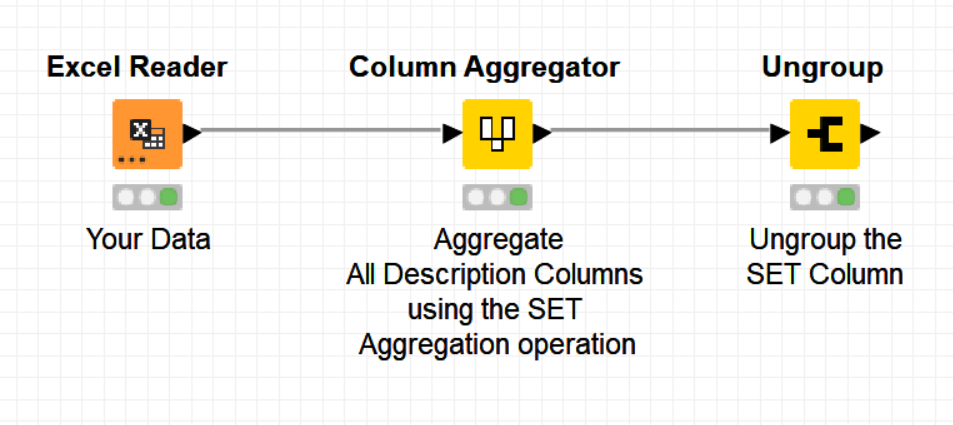
as per the image above I have project, relation name and their description columns. If there is a value/values description1 to description9 and if they are equal in each row then I need get them into one column as per the image below.
I would probably combine all of the “description” columns into a collection, and then use the Column Expression node to remove everything including and after the first comma.
If you upload a dummy workflow, then I would be happy to show you.
Just a quick answer out of the hat. You could use the -Column Aggregator- node to aggregate all the description columns making sure that when you aggregate, the “SET” operator should be chosen. This will force to have just one content, for instance “OUTSIDE” or “NOT applicable” in your column.
Then you will need to convert this column to a STRING type so that it is not anymore of type SET. This can be done with the node -Collection to String-.
If not clear enough, please share your excel file to help further with a workflow.
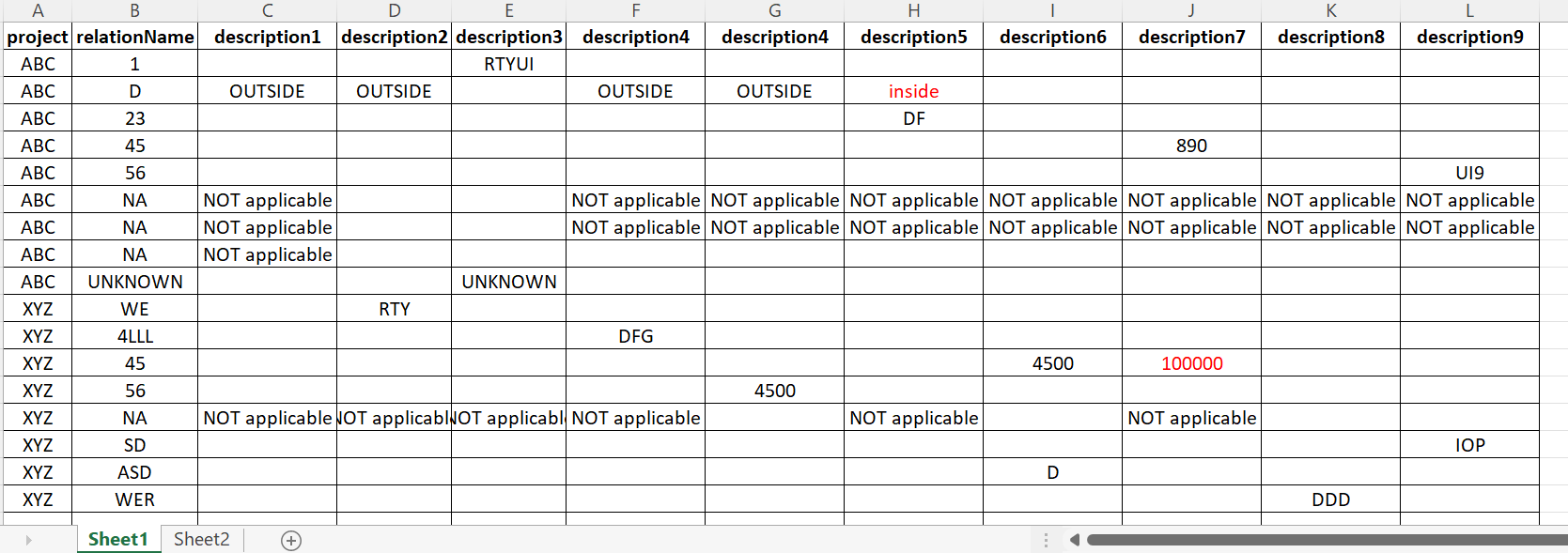
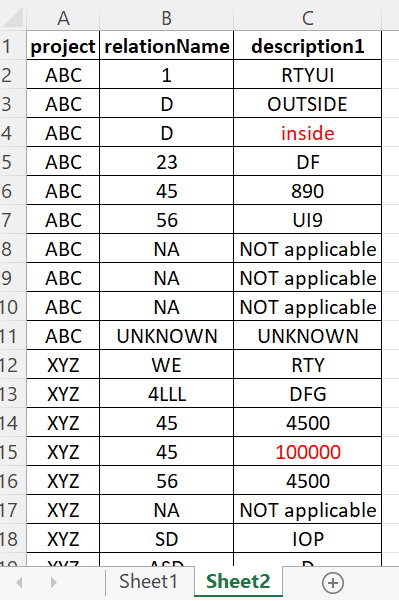
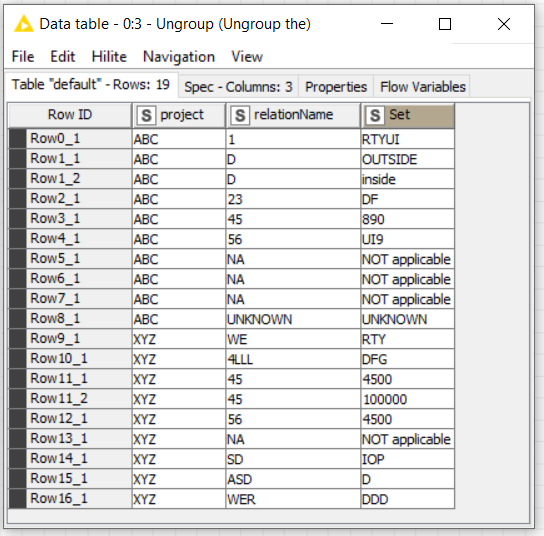
as per the image above I have project, relation name and their description columns. If there is a value/values description1 to description9 and if they are equal in each row then I need get them into one column as per the image below. If the values are not equal then I have to add another row to relation name and add that value in a new row. Please check both images red colour values.
My solution is still valid in your latter case if instead of using the -Collection to String- node, you use the -Ungroup- node which will generate the table as desired.
Just needed to make sure that the “missing” option in the “SET” aggregation operation was not checked so that missing values are not gathered too in the creation of the set.
I did it the way that I first posted, but there are a ton of ways to do it. I would like to mention that your sample data did not always include just one singe unique entry in the description columns per row. (for example: Row ID1 contained both “Outside” and “inside” / Row ID11 contained 4500 and 100000) . My approach takes the first one in the list.
Edit: I now see your above post with the red highlighted rows for dealing with multiple unique descriptions. Now that I know that that you were going for more of a “pivot” solution, I would go with the @aworker approach.