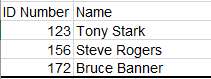
I would like to add rows from one table to another, but only if they aren’t already present in the existing table. For example if I started with a table like this:
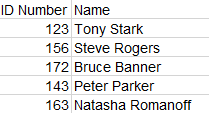
Then obtained this table:
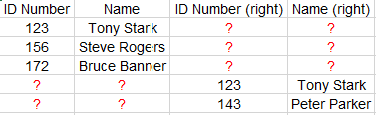
How can I combine them so only one of two identical rows is present? Like this:
Hi @Christine1302 , provided that the tables are the same structure, ,another options is to use a concatenate node followed by a duplicate row filter.
@Scott’s joiner node can do it with a single node though, and I’m guessing is probably more efficient on large data sets, although requires a little more configuration. (specify joins on every column, return matched, left unmatched, right unmatched. Have them all return to the same port (don’t split) , and tell it to Merge join columns)
I’ve tried using the Joiner node and I am getting a result that places the tables next to each other and shows missing values in the remaining columns. Similar to this:
The concatenate node seems to organize the tables in the way I was hoping. When I use the duplicate row filter, Include ID Number, and specify that I want to keep the first row of the two, it doesn’t actually remove either of the rows. I’m not sure if I am missing something that would make this node more effective for me.
Hi @Christine, re the Joiner method, did you tell it to Merge join columns ? This should then stop you getting the (right) columns separated
With the concatenate and remove duplicates method, for the example table it ought to work without requiring configuration as it should act across all columns
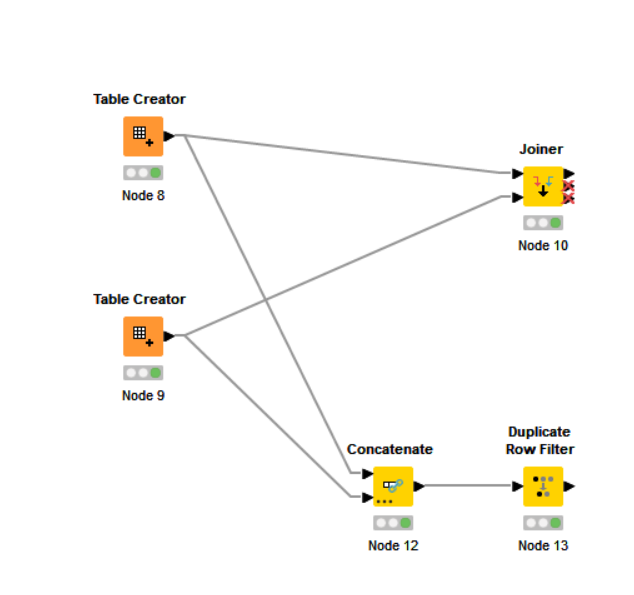
Here is an example of both the Joiner and the Concatenate-Deduplicate methods
I’m realizing that in my example, the tables only have the same existing columns. In the actual data I’m using, one table has 5 columns, and the other has 7, 5 of which are the columns from the first. Could that affect the way my tables are joining/filtering?
I did get the joiner node to stack the two tables, but it still isn’t removing rows with the same values.
Hi @Christine1302 , yes that will have an effect, and that’s what I mean when I said if the tables have the same structure. Sorry if it wasn’t clear what I meant by that.
If one table has more columns than the other, then it presumably has additional data in one of the tables, so this is important as you don’t want to lose that data.
With the concatenate and deduplicate method, it is now important which table is first in the concatenation because if there are duplicates, you want to make sure to keep the “wider” row (i.e the one that has more data on it)
So concatenate the tables ensuring the “wider” table with 7 columns is attached to the top input port, and the other table with the 5 columns is second. Then set the duplicate row filter to look only at the first 5 columns, and in advanced settings have it remove duplicates, keeping FIRST row.
With the joiner method, you need to make sure it is joining on the 5 columns that can match, and that it is set to merge the join columns.
Check that the column data types are the same on both tables. It sounds like it isn’t able to perform the join and this is usually either because of mismatching data types, or because there is additional white space in the data in one of the tables.