Hello,
I am trying to use the cellsplitter node to seperate out some input text. There are two columns, one for the text that I’d like to split out (using ‘space’ as the delimieter) and the second column has a flag for the first and last item in the sequence.
I’d like to add an additional space to the beginning of the ‘LAST’ text so that all cells are essentially shifted over once to the right. Simirarily, I’d like to add a space after the first text field in the ‘FIRST’ item.
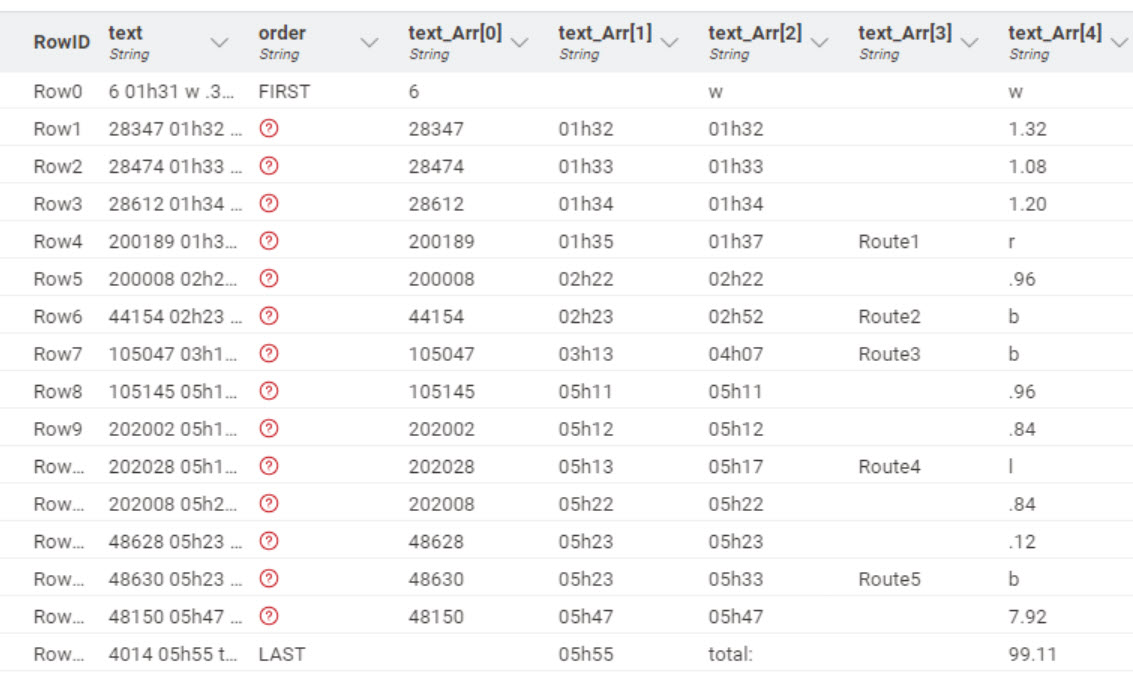
In the example workflow, I’d like to have the text_Arr[1] column blank for the ‘FIRST’ text, and text_Arr[0] blank for the ‘LAST’ text.
Beyond this, my second problem is that I’d like text_Arr[3] to only have text when there is a RouteX number, and otherwise be blank. This would mean that the single letter text (w in row 0, r in row 4, b in row 6, l in row 10, etc) for all rows would end up in text_Arr[4].
I hope this makes sense, would really appreciate any help on this issue.
Test_Splitter.knwf (7.6 KB)
Hello @zoe_knime,
Could you please show the sample table of the exact output you want?
Unless I’m missing something this description doesn’t match your dataset:
Beyond this, my second problem is that I’d like text_Arr[3] to only have text when there is a RouteX number, and otherwise be blank. This would mean that the single letter text (w in row 0, r in row 4, b in row 6, l in row 10, etc) for all rows would end up in text_Arr[4].
Adding blanks will not move the data to adjacent cells since they’re in different columns:
I’d like to add an additional space to the beginning of the ‘LAST’ text so that all cells are essentially shifted over once to the right. Simirarily, I’d like to add a space after the first text field in the ‘FIRST’ item.
There’s probably a way to do this, but your suggestion won’t work - unless I’m missing something.
I wrote a workflow which produces the output below. I’m not going to upload it until you comment on how close this is to what you want.
Hi, sorry, I wasn’t very clear, this is a great clarification.
This is how I’d like the data to look in an Excel format, so all the ‘routes’ are aligned and all the single letters (w, r, l, b) are aligned
Hi, sorry for not being more clear. What you’ve done for the ‘first’ and ‘last’ rows is exactly what I’m after, thank you
I’m looking to have all the ‘routes’ aligned, and all the single letters (w, r, l, b) aligned.
I’m sorry but I’m struggling with trying to understand what you mean by “aligning” the single letters. There’s no obvious pattern in the original data which I can see which will produce your desired output.
I wasn’t sure how to do it either, but was hoping there might be a trick I didn’t know about in rule engine or similiar that could say something like ‘if string is in format X then add a space’, then put it into a cell splitter. If there isn’t a solution then there isn’t one - that’s fine. Thank you for trying
You’ve got to be more specific about which columns you’re talking about. Describe your decision process about why you manually configured column E the way you did. What does it depend on? With that we may be able to extract rule(s).
I need to bring this dataset into Tableau, where I’ll need all the routes in one column and all the single letters in another column in order to filter by route and filter by the letters. Therefore where there is a route, I want it listed in column D (in this example) but a blank space if there is no route, then the letters in column E. If it helps, there will only be a route number in the rows where column E is equal to ‘b’, ‘r’ or ‘l’ - any ‘w’ rows won’t have a route (and will therefore have a blank space in the route column (E))
How did you assign the letters in Column E to the specific rows they’re in?
This output is actually straight from another program, I showed that Excel output as an example of how I want the output to look. The original output that I import into Knime looks like the below in NotePad. I’m not fussed about the information after the letters (column E in the Excel version). This is how they automatically come out of the original program
Now I’m even more confused. Is the data from your first post what you’re trying to manipulate? If so, I don’t think there’s a way to produce column E. Why don’t you just use the data produced by “another program?” It seems to produce what you want.
This is all the same data - the data from the first post is what it’s like when I bring it into Knime, the Excel and NotePad screenshots are what I want it to look like. There is a lot of other data attached to the output that I’ve put through Knime and cleaned up to the correct output, this is just the last piece of the puzzle that I don’t have cleaned up yet (so I can’t use the other program output).
If there isn’t a way to add spaces partway through a string then it is what it is, I’ll need to figure something else out. Thanks for your effort
The issue isn’t spaces (I assume you mean in Column D), its how you assign the letters in Column E. My workflow correctly cleans Column D.
The letters are included in my original dataset, they don’t just magically appear in my output examples
Check this. I didn’t bother renaming or moving any of the columns.
that’s pretty much it, thank you! only thing I can see is that row0 text_Arr[2] should be 01h31 but otherwise it looks spot on