Hi @harry2021 and welcome to the KNIME forum
Since most of the Machine Learning methods try to minimize a loss function, oversampling of samples based on their importance is a technique which can bias the training toward examples with more importance.
For instance, if you consider that an example is 4 times more important than all the others, you could oversample it 4 times in your training set. In this case, the error induced by this sample will have a weight 4 times higher than the others for the loss function.
Keep in mind that this should normally be done only in the training set and not in the Cross-Validation set, nor in the test set. The CV and Test sets should remain the same.
On top of replicating the important training samples in the Training set, you could add jittering to the variables (add slight noise to the descriptors) of these samples to avoid to replicate exactly the same samples (so that they are not exactly the same as the originals).
Some references about Jittering (or adding noise):
[1] Koistinen, Petri, and Lasse Holmstrom. "Kernel regression and backpropagation training with noise." Neural Networks, 1991. 1991 IEEE International Joint Conference on. IEEE, 1991.
[2] Holmstrom, Lasse, and Petri Koistinen. "Using additive noise in back-propagation training." Neural Networks, IEEE Transactions on 3.1 (1992): 24-38.
[3] Bishop, Chris M. "Training with noise is equivalent to Tikhonov regularization." Neural computation 7.1 (1995): 108-116.
[4] An, Guozhong. "The effects of adding noise during backpropagation training on a generalization performance." Neural Computation 8.3 (1996): 643-674.
[5] Vincent, Pascal, et al. "Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion." The Journal of Machine Learning Research 9999 (2010): 3371-3408.
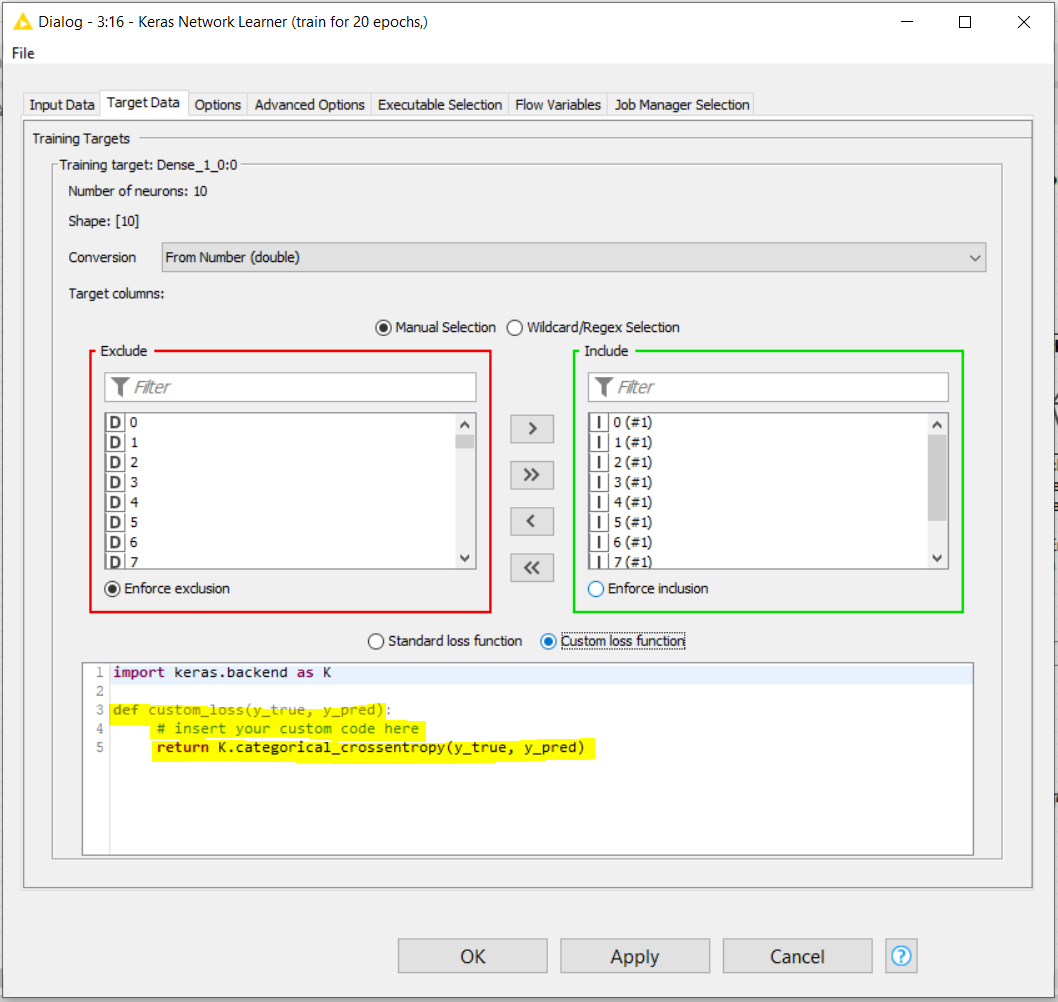
In the particular case of Deep Learning, some libraries as TensorFlow and Keras (even in the KNIME implementation of the -Keras Network Learner- node) allow to implement your own loss function. In this case, the loss function equation could integrate the weighting of your more important samples. This is the place in the KNIME -Keras Network Learner- node where the loss function should be modified:
Hope these hints are of help.
Best
Ael