Introduction
Welcome to the thread devoted to the course “A Codefree Introduction to the Principles of Data Science”. The course introduces you to the overview of various Data Science techniques and shows how to apply them on your own data (if you have some) without coding - via the open-source software - KNIME Analytics Platform.
The course is run by Prof. Michael Berthold and a number of experienced data scientists from KNIME. The introduction lecture takes place on Wednesday, November 2 at 17:00. Following, there will be weekly sessions on Wednesdays also at 17:00. At the end we will arrange a Hackaton (lockdowns etc. permitting with beer&pizza at the KNIME offices). For more specific information, such as schedule and zoom links to the lectures, please use ILIAS.
Posting guidelines
Post any organizational or topic related questions in the thread by clicking “Reply” at the end of this message. Please be polite and respectful and remember: there are no stupid questions!
I have an administrative question: if we want to get the 3 credits we need to pass the L1 and L2 KNIME qualifications, right? We can do this on our own by following the self-paced course or is there a date and time when we need to take this exams?
Second, I also have a practical question: I tried the 01 exercise and I need to find out the most popular first name. I used the group by node but I can’t figured out how to configurate it. Could you please give me a hint?
Regarding the certifications, we will announce a due date by which you shall pass the qualifications later on. We will also provide you with the voucher for the L2 certification. Please, do not hurry, it will be closer to the end of the course. Please, do not try to do certifications before completion of the lecture course/self-paced courses, since if you fail you have to wait 3 months to try again.
Regarding the practical question, do you mean the exercise in the folder Data Wrangling, Parts 1 and 2 on Hub? If yes, then either you may wait for the lectures of Maarit, which will take place on
23 and 30 of November, or you can watch our videos - What’s data aggregation and Basic Aggregations with the GroupBy node and try to solve it by yourself.
Dear Students,
to your questions during the last lecture on recordings. I have clarified and as I said yesterday, we do not provide the video-recordings.
If somebody missed the lecture, please catch up with the slides and exercises and feel free to post any question here. The corresponding lecturer or me will help you!
Best,
Daria
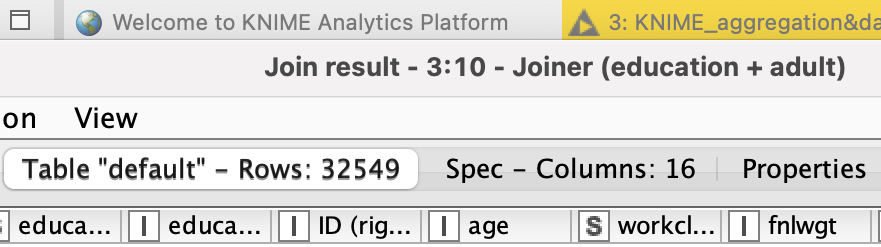
I tried to do L1-DS Hands-on Exercises: Aggregation and Data Blending and at task 3 I have a small problem. I manage to do the first join (education+adult), but when I try to join the joined table with the income table, I get more rows than I should.
I tried anything I could think of to resolve it, but I am out of ideas. Do you think you could help me? My workflow is uploaded in the student workspace.
Thank you in advance and I hope I was coherent when explaining!
Dear @Ana_Dinu,
very nice problem description. Also it was really useful that you have provided the WF. Thank you!
I will explain below the issue and give you a hint how to solve it! If there will be any additional problems, feel free to text me
The problem occurs not only in the second Joiner node but also in the first one. And it lays in the way you preprocess the data.
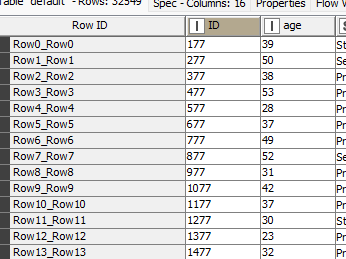
You had a right way of though regarding deletion of the 00 from ID column, such that it matches with the ID column of another table. You have used String Manipulation node for that - great idea. However, the command you have used replace($ID$,"00" ,"" ) did a bit of extra unexpected work. It not only deleted the 00 in the beginning of the IDs but also in the middle and in the end. For instance, look here:
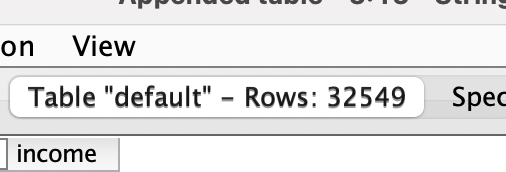
in the original data Row99 has an ID of 0010077
when you use String Manipulation node it will also delete 00 in the middle, resulting in 177
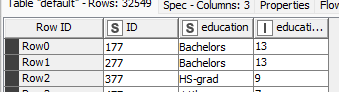
now look at the ID of the first row:
What do we see? We have a duplicated ID = 177. And that basically destroys the uniqueness of the ID in the data.
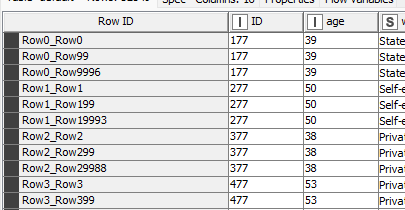
Hence, when you configure and execute the first Joiner node, and match the IDs: the matches are nor unique. That you can observe in the way how RowIDs are concatenated:
If IDs are unique, then after the execution of the Joiner node for this data, you would have also matching RowIDs:
Solution
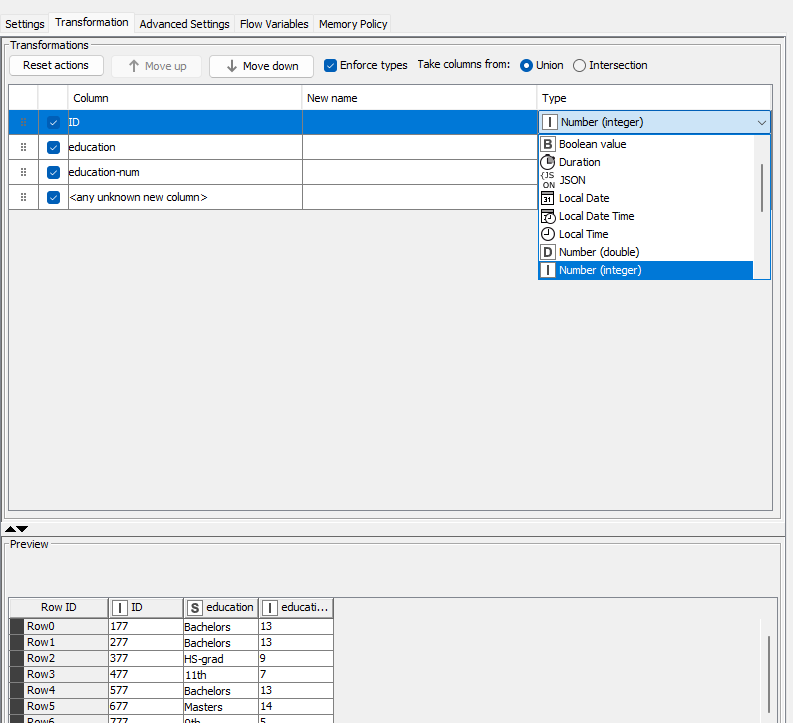
One of the elegant solution is hidden in the dedicated Reader node configuration.
After you have selected the file path in the configuration window of the Table node, for instance, you go to the “Transformation” tab and select the Type of the column ID - Number (integer). Then 00 in the beginning are automatically eliminated.
Hello! Happy New Year! I have a question: is it enough for the L1 Certification to finish the L1-DS self-paced course or do I need to take the L1-DW as well?
First of all, thank you for the response to my question! Secondly, I realized that I completed the form for the hackathon with my personal email instead of the uni one. Do I need to complete the form again? Sorry for not paying attention.
I was doing the L2-DS Hands-on Exercise: Data and Time Databases and I got stuck. At task 2 I’ve done every operation, but in the end instead of 38843 rows, I get way more when I look into the data from DB Reader note.
Do you think you could advise me how to resolve this? My workflow is uploaded in the student workspace.
Hi @Ana_Dinu!
Thank you for your question
I have taken a look at your workflow - it was really helpful. You have done everything correctly, and your workflow gives correct results if you run it ones. However, if you rerun the workflow, then you may notice that the rows, outputting DB Reader node, double. If you rerun again - again double.
Why does it happen?
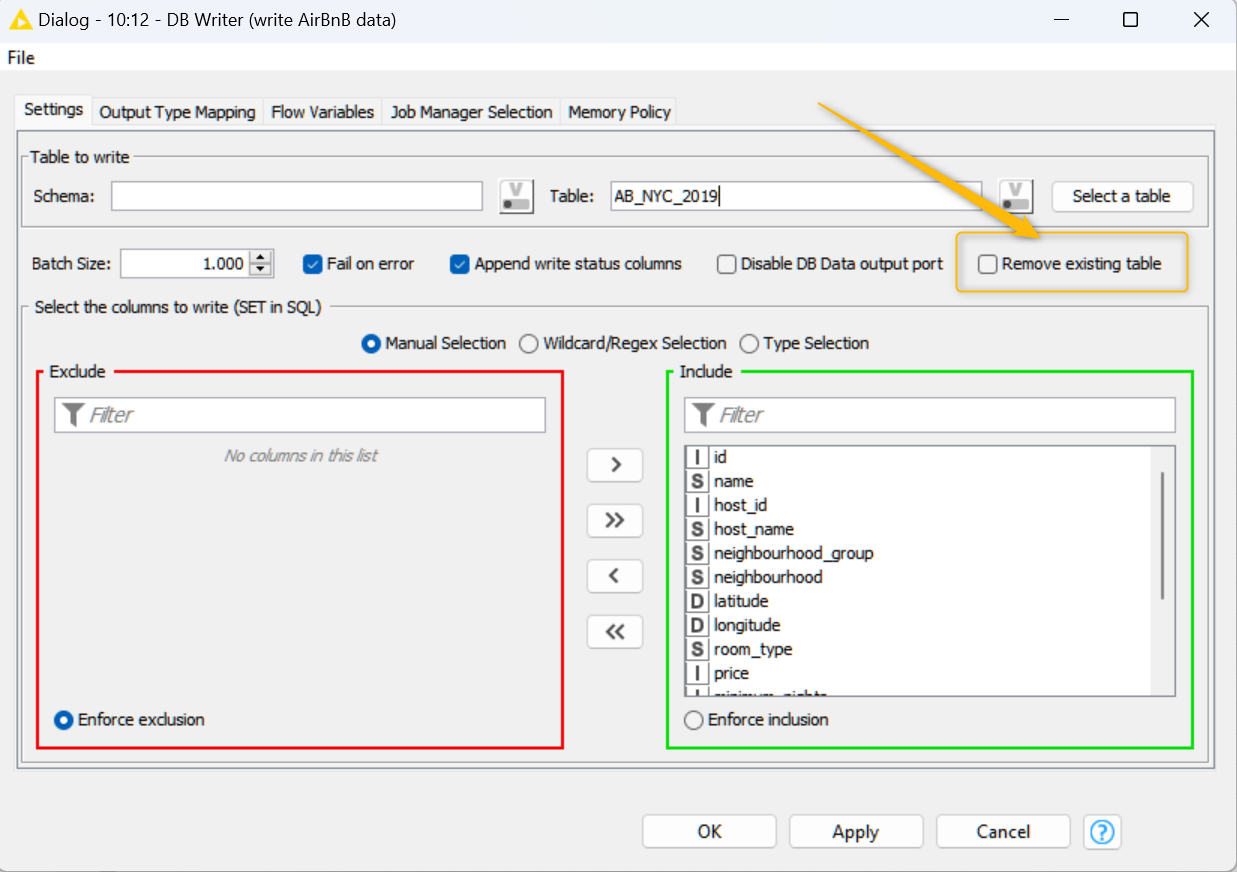
If you look in the configuration window of the DB Writer node, there is an option to Remove existing table, which you should tick to prevent such a behaviour. If you do not tick it, then each time you rerun the workflow, DB Writer appends the table (rows) from Modify Time node to the table you choose in Table to write in the DB Writer node.
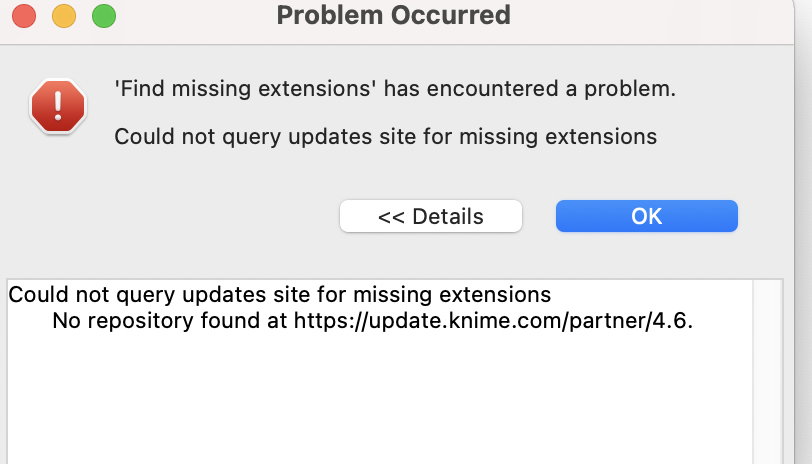
Good afternoon! I come yet again with a question regarding the Flow Variables and Components Hands-on Exercise. I’ve tried to do the third part, but I got an error message telling me that I don’t have a node installed. When I tried to install the extension which contains the node, the following message appeared:
I don’t know how to proceed from here. I would be grateful if you could advice me. Also at the second task, I can’t connect the final node in the component to the component output.
Hi @Ana_Dinu ,
could you please check 2 things for me:
which version of the KNIME Analytics Platform do you have (Help → about KNIME Analytics Platform)? If it is below 4.6.3, you might need to update KNIME Analytics Platform.
if the version is above 4.6.3, could you please send me a screenshot of Update Sites?
Let us deal first with an installation problem and then, if the second problem remains, I look into it too