Hi @iankruger, interesting challenge! 
My thoughts on this were that we needed to find the transitions points between am and pm, and mark those as requiring either 0 or 12 hours to be added to the retrieved datetime.
In between those transition points, all the 0 values then need to be filled-down, and likewise all the 12 values.
After that, we then shift each row by the required number of hours.
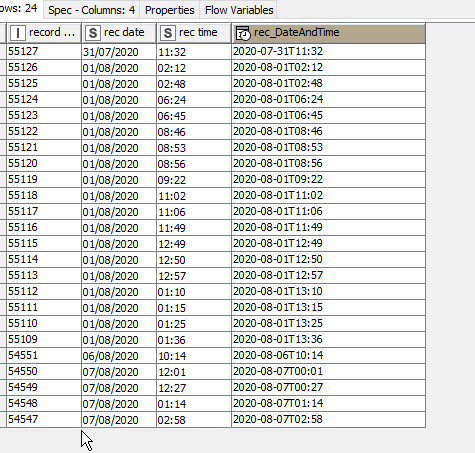
That was the plan! So, first off, we just treat everything as “morning” data. Using a Column Aggregator (or we could have used String Manipulation for example) to combine the Date and Time columns into a Date and Time string as "01/08/2020 02:12". A String to Date&Time using a date format mask of d/M/yyyy k:mm. Note the use of “k” here rather than “h”. Not obvious from the documentation the difference between them, but “k” works here, and “h” doesn’t… I think h requires additional am/pm information but it might be something else- I clearly need to go read up!
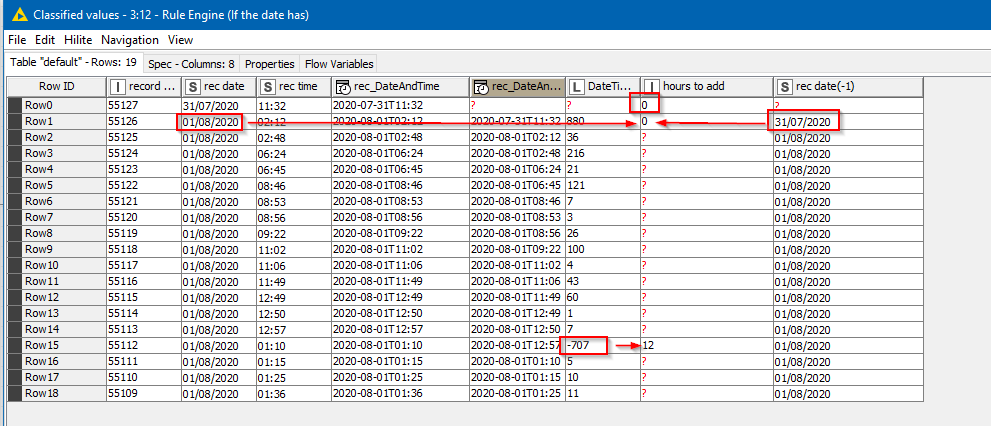
We use a Lag Column to note the derived “morning” Date&Time for the previous row, then for each row use Date&Time Difference (in minutes) to see if time has gone backwards from the previous record. Where time goes backwards… this is the “pm” boundary. So use a Rule engine to mark that boundary as requiring as 12 hour forward timeshift.
Next, use another Lag Column to see the DATE of the previous record. Where the Date changes, this is the “am” boundary. So use a Rule engine to mark that boundary as requiring a 0 hour forward timeshift.
(I use the term “am” boundary rather loosely here. The am/pm boundary is actually at 12:00 noon, but for the purpose of this, we can treat the boundary as at 1pm, because that is the point at which we need to adjust the time from 01:00 to 13:00)
Anyway, at this point we now have data something like the following:
This has correctly identified the timeshift required for Row1 and Row15, but Row0 is problematic as none of these rules successfully identify that 11:32 is in the evening instead of the morning which is the default position.
Unfortunately I haven’t time right now to do the workflow for determining the hour of the first record.
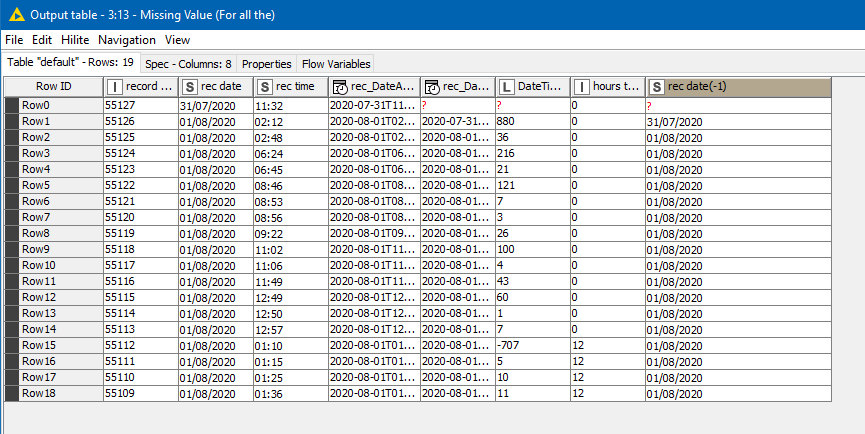
Ignoring the first record, a Missing Values node can then “fill down” the missing timeshifts for the rows in between the boundaries…
and these timeshifts can then be applied.
As I say, what I have at the moment isn’t quite complete. I thought though, that I’d give you what I’ve got so far, and either I’ll come back later, or somebody else can chip in (or suggest a totally different way).
My thoughts for determining if first row is am or pm is that you filter off first row, and all the other rows separately as a “side flow”. You look at the date of the first row, and filter the “other” rows to include only rows with the same date. You then find the minimum time for those other rows with the same date, and if there is a time earlier than the time on the first row, then the first row is “am”. If there isn’t (or if there aren’t any other rows with the same date as the first row) then the first row is “pm”…
Anyway, this is my story so far…
12 hour to 24 hour times.knwf (30.7 KB)
As you can see, this currently determines the correct time of day for all but the first row.
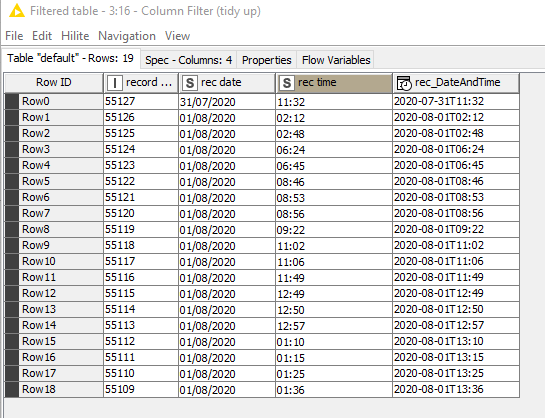
I’d also need to do further tests and maybe some refinement to see if it gets this correct under a variety of circumstances, but hopefully this is a starting point!