Ich bin noch absoluter Anfänger mit Knime und kein Script Profi. Es wurde mir seitens KI empfohlen, statt mit Excel nun KNIME zu versuchen. Es soll ja ein LowCode Programm sein. Ich bin leicht überfordert mit der Anzahl von NODES.
Zur Problemstellung:
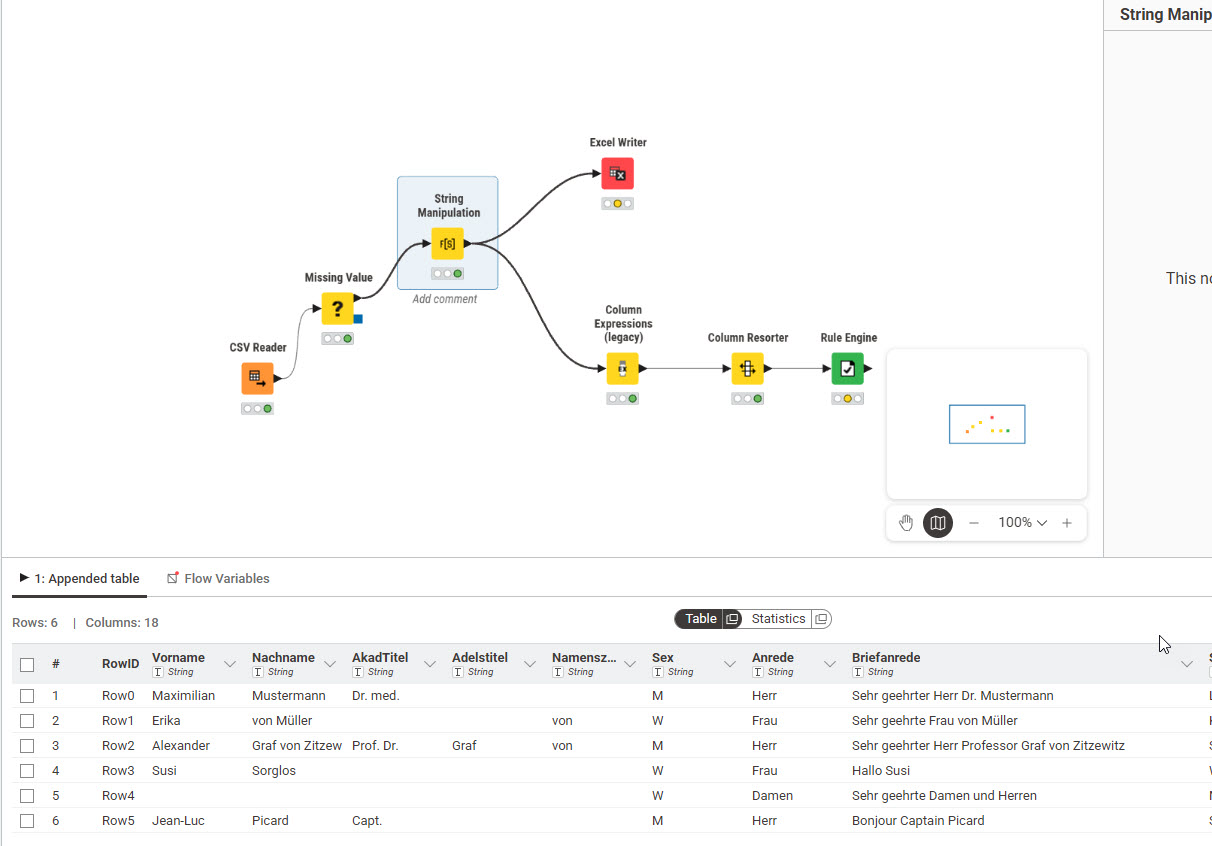
ich bekomme Adressdaten welche ich nun für den Seriendruck vorbereiten möchte. Nun muß ich z.B. eine Briefanrede neu generieren. Dabei ist z.B. zu beachten, dass wenn ein Adelstitel wie Graf, Prinz, Freiherr, usw. enthalten ist, ich nicht Sehr geehrter Herr Graf stehen habe, sondern sehr geehrter Graf. Im Nachnamen haben ich zum Beispiel auch einen Namenszusatz und Titel enthalten. Diese sind aber in den jeweiligen Feldern auch enthalten. Was beim Zusammenbau dann doppelt Graf von Graf von Muster stehen würde.
Die Frage ist, wie ich nun anfangen soll? Es gibt Javascript Nodes und Phyton Nodes, und KNIME hat ihre eigene Sprache noch. Dann habe ich Beispiele gesehen, die z.B. mit einer Zusatz Refernztabelle arbeiten (wenn Input X, dann Output XY).
Dann stellen sich Aufgaben wie Leerzeichen hinzufügen wenn gesetzt oder entfernen am Anfang. Zahlen mit Nullen auffüllen oder eine bestimmte Schreibweise für Kontonummern in XXXX XXXX XXXX Maskierung.
Außerdem eine UUID und Zeilennummer jeder Zeile hinzufügen. Ggf. Dublettenabgleich, Filterungen nach Kriterien, usw.
Nur wo fang ich an? Ich habe jahrelang mit einer Profi Software für Mailings gearbeitet (Quadient Inspire Designer). Nun muß ich das ganze sauber vor dem Seriendruck zusammenbauen, damit ich zum Schluss z.B. fertige Zeile 1-8 habe. Wenn leer, dann rutscht die nächste Variable hoch (wobei das z.B. Indesign kann).
@ThomasMayer es gibt in KNIME eine Reihe von Elementen die man kombinieren kann. Zum Thema Regeln gab es schon ein paar Tipps. Hier ist denke ich Planung entscheidend und die Frage welche Bandbreite an Variationen erwartet wird.
Die verschiedenen Arten Regeln zu schreiben werden hier behandelt
Also ich habe heute mal ein Try and Error mit KNIME versucht und mir die Daten mal ein wenig bereinigt. Ein “low Code” bis NoCode ist KNIME nun auch nicht wirklich. Meine größte Herausforderung ist momentan:
die Selektierung, welche NODES ich für was verwende und welche wichtig sind
Script Sprachen und Syntax. Das eine arbeitet nach Javascript, das andere Python und das nächste wieder in KNIME Sprache. Ich tue mich da schwer, erstmals zu erkennen, welche Sprache welches Node verlangt und wie darin wiederum die Abfragen, Bedingungen, Concatenation/replace/trim/Part/gleich/istLeer, usw. aufgebaut werden müssen. Gibt es da einen kurzen Leitfaden?
bestimmte Nodes auch nicht in den Extensions auftauchen. GUID Generator zum Beispiel. Wie installiert man den? Ich habe in Nodepit einfach das symbol oben in die Oberfläche gezogen. Scheint zu gehen.
Oberfläche: Ich habe die neuste Version und da ist auch das moderne UI aktiv. Nun gibt es aber “Tutorials” die auf das alte UI aufbauen und ich suche mir den Wolf. Z.B. simple Notizen um eine Gruppe von Nodes zu ziehen. Das geht mit der alten UI glaube ich.