Hi,
I’m trying to use Pivot Node with flow variable customization.
According to previous variable I’ve to aggregate data in different ways so I would use flow varialbes. I’ve read the topic [solved] Using flow variable in Pivoting node - #8 by ipazin but it’s not good for my cause.
In that topic the solution is the creation of aggregation variables by standard interface and the override of them by flow variables.
In my scenario, the number ov aggregaion variables is … variable so I cannot populate agggregation column interface.
When I opened PivotNode flow variable interface I’ve found the aggregation column section
In this section I can see 4 variables:
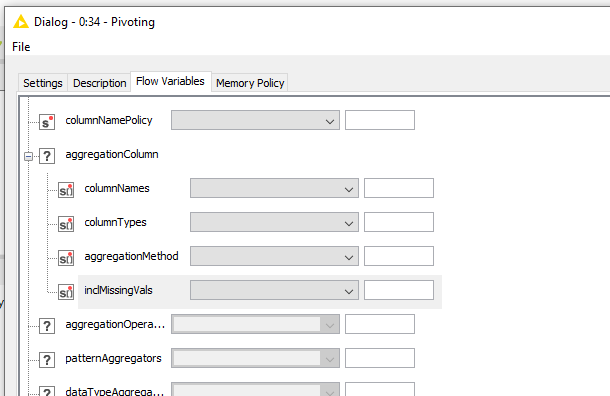
So I created 4 string array variables (according to types listed in image). Then I passed them to node.
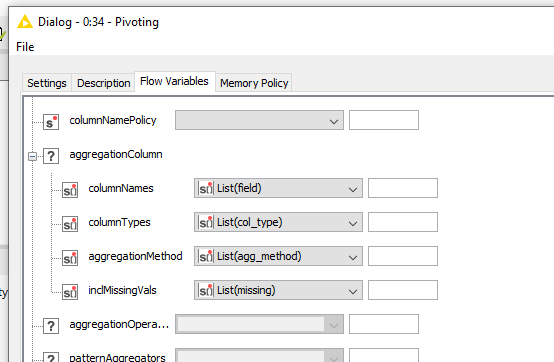
The problem is that, with this configuration, the node display a configuration error with this stacktrace (exracted by a verbose logging).
> 2020-04-24 16:58:06,090 : DEBUG : KNIME-Worker-45-Table Row to Variable 0:32 : : Node : Pivoting : 0:34 : Errors loading flow variables into node : String for key "numericColumnMethod" not found. > org.knime.core.node.InvalidSettingsException: Errors loading flow variables into node : String for key "numericColumnMethod" not found. > at org.knime.core.node.workflow.SingleNodeContainer.applySettingsUsingFlowObjectStack(SingleNodeContainer.java:355) > at org.knime.core.node.workflow.SingleNodeContainer.access$2(SingleNodeContainer.java:328) > at org.knime.core.node.workflow.SingleNodeContainer$1.preConfigure(SingleNodeContainer.java:283) > at org.knime.core.node.Node.configure(Node.java:1836) > at org.knime.core.node.workflow.NativeNodeContainer.performConfigure(NativeNodeContainer.java:528) > at org.knime.core.node.workflow.SingleNodeContainer.callNodeConfigure(SingleNodeContainer.java:304) > at org.knime.core.node.workflow.SingleNodeContainer.configure(SingleNodeContainer.java:196) > at org.knime.core.node.workflow.WorkflowManager.configureSingleNodeContainer(WorkflowManager.java:5996) > at org.knime.core.node.workflow.WorkflowManager.configureNodeAndPortSuccessors(WorkflowManager.java:6155) > at org.knime.core.node.workflow.WorkflowManager.doAfterExecution(WorkflowManager.java:3198) > at org.knime.core.node.workflow.NodeContainer.notifyParentExecuteFinished(NodeContainer.java:630) > at org.knime.core.node.workflow.NodeExecutionJob.internalRun(NodeExecutionJob.java:248) > at org.knime.core.node.workflow.NodeExecutionJob.run(NodeExecutionJob.java:124) > at org.knime.core.util.ThreadUtils$RunnableWithContextImpl.runWithContext(ThreadUtils.java:334) > at org.knime.core.util.ThreadUtils$RunnableWithContext.run(ThreadUtils.java:210) > at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) > at java.util.concurrent.FutureTask.run(FutureTask.java:266) > at org.knime.core.util.ThreadPool$MyFuture.run(ThreadPool.java:123) > at org.knime.core.util.ThreadPool$Worker.run(ThreadPool.java:246) > Caused by: org.knime.core.node.InvalidSettingsException: String for key "numericColumnMethod" not found. > at org.knime.core.node.config.base.ConfigBase.getString(ConfigBase.java:405) > at org.knime.base.node.preproc.groupby.GroupByNodeModel.loadValidatedSettingsFrom(GroupByNodeModel.java:485) > at org.knime.base.node.preproc.pivot.Pivot2NodeModel.loadValidatedSettingsFrom(Pivot2NodeModel.java:869) > at org.knime.core.node.NodeModel.loadSettingsFrom(NodeModel.java:462) > at org.knime.core.node.Node.loadModelSettingsFrom(Node.java:641) > at org.knime.core.node.workflow.NativeNodeContainer.performLoadModelSettingsFrom(NativeNodeContainer.java:534) > at org.knime.core.node.workflow.SingleNodeContainer.applySettingsUsingFlowObjectStack(SingleNodeContainer.java:353) > ... 18 more
Can you help me?
Thanks

 )
)
