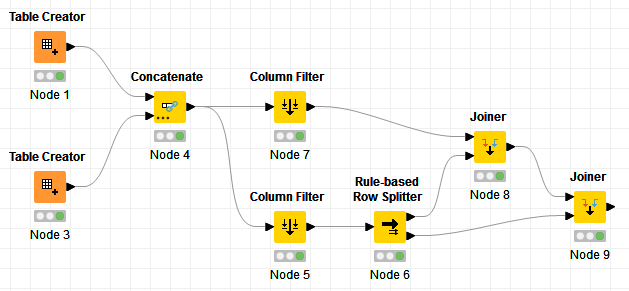
I’ve been trying to find an optimal way to join two tables like those below to get a merged result.
Tables 1 and 2 have two identical columns and one extra column. I want to join on one column, ColA, and to get merged results where the other column entries are identical or ducplicates of ColA where the other entries are not identical.
Is there a single node which can do this or do I have to use a overly complicated cell replacement etc… ?
Thanks,
mike
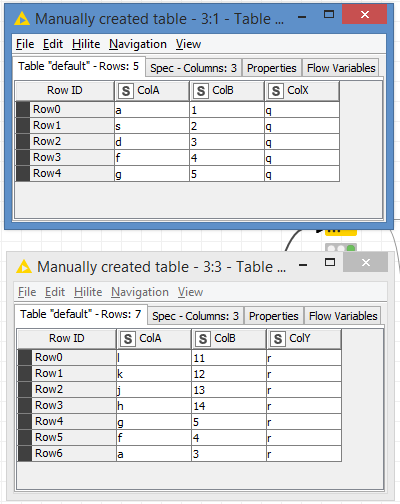
Table 1
ColA ColB ColX
a 1 q
s 2 q
d 3 q
f 4 q
g 5 q
Table 2
ColA ColB ColY
l 11 r
k 12 r
j 13 r
h 14 r
g 5 r
f 4 r
a 3 r
Output:
ColA ColB ColX ColY
a 1 q r
a 3 q r
s 2 q ?
d 3 q ?
f 4 q r
g 5 q r
l 11 ? r
k 12 ? r
j 13 ? r
h 14 ? r
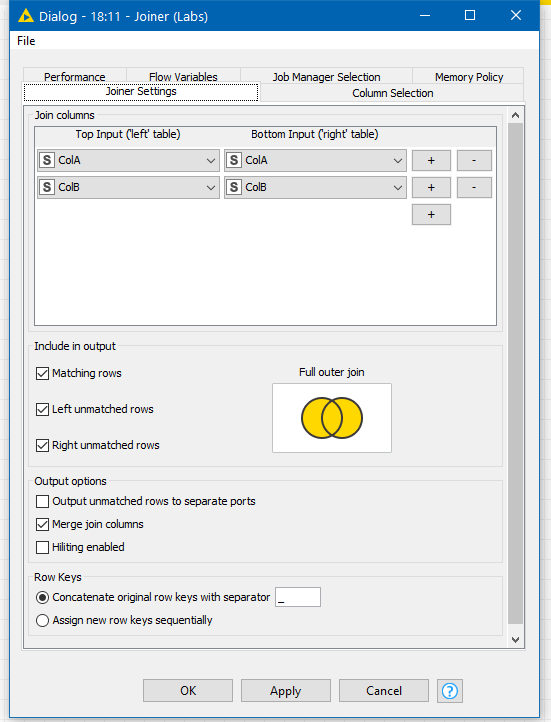
Hi @mazzo, I haven’t got knime in front of me at the moment, but it looks to me like you are wanting a “full outer join”. Take a look at the Joiner node and set the join type to full outer join, and join on both colA and colB and see what you get. I don’t think it’ll be far off what you want.
There are settings to keep or lose the join columns from one of the inputs so you don’t duplicate the colA and colB columns on the output dataset.
You can get more control using the Joiner (Labs) node as an alternative which has more options but on the face of it the Joiner should be able to return what you want.
Alternatively are your tables on a database, in which case the above but with the DB joiner should do it.
Hope that helps but post back if I missed something.
The logic:
I do a concatenate first, to get all possible data, and it will not duplicate the columns:
After that, it’s a matter of separating ColA+ColX and ColA+ColY as 2 datasets. Then use the first table (concatenated one) to left join on ColA with the 2 datasets. I can do a left join with the first table as it contains all ColA and ColB combinations that I need.
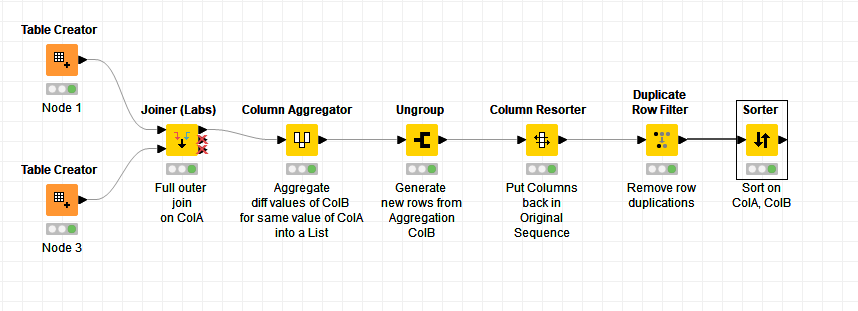
I got back to my pc! It turned out the basic Joiner node would need subsequent merging of columns, although it would get there, but the Joiner (Labs) node does a credible job.
Yes, my bad on my original suggestions. I hadn’t spotted those when I answered.
So I’ve had another look at this, this morning to see if I can salvage any pride!
Actually the thing I love about Knime (which can also be a bit of a curse of course) is that there is more than one way to do just about anything, and I end up spending ages just trying to find an alternative solution, even once I have a solution that works.
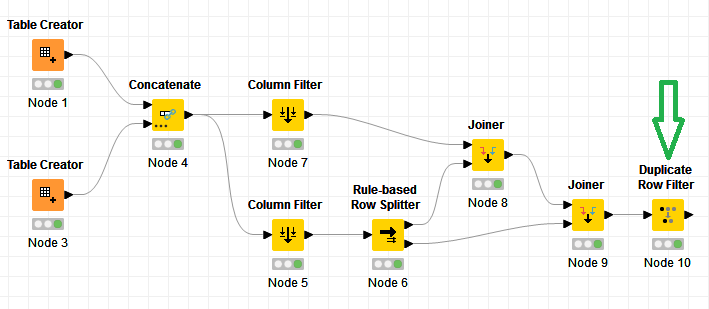
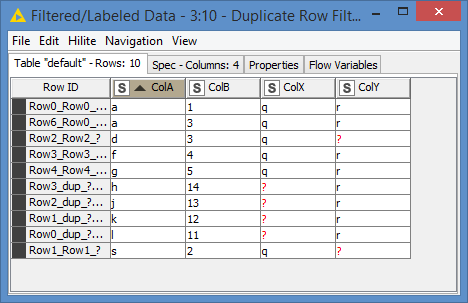
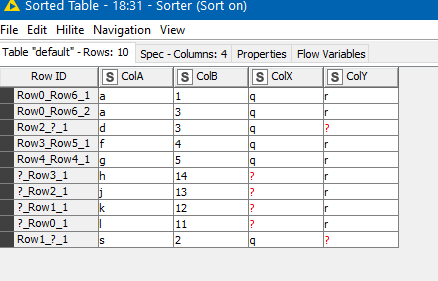
I’m still starting on the Full Outer Join but I’ve refined it and of course added a bunch of extra nodes. The original join is now just on ColA as you would expect. But it then makes use of a Column Aggregator followed by an UnGroup to form the different rows required where ColB can take two values for the same ColA (e.g. A 1 and A 3). It works for the data given. Whether it would work for other data in this scenario would remain to be seen, but it was a bit of fun!
@takbb you can use Set aggregation method (only unique values are taken) instead of List and avoid deduplication
Unless you go scripting there is no one node solution @mazzo but 3 node solution (Joiner – Column Aggregator – Ungroup (not counting formatting nodes)) doesn’t seem overly complicated
Thank you both @takbb and @ipazin for the aggregator + ungrouping, I never thought of this way. I always did this kind of operation by manually separating the dataset and re-joining as per my solution. Glad to learn another way.
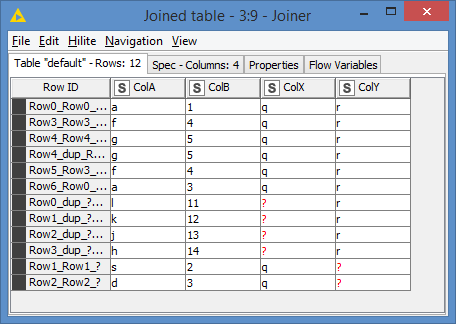
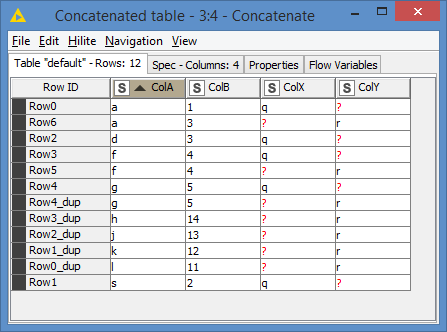
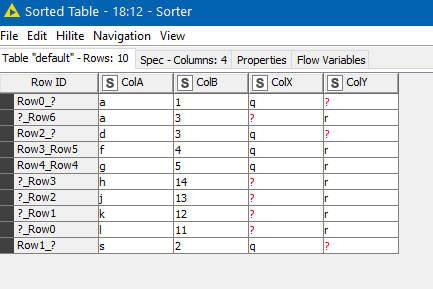
 (that reminds me that I should have de-dupe my results)
(that reminds me that I should have de-dupe my results)