Hi, I am working in DB nodes and I am looking for a way to aggregate data and pick FIRST value for a certain criteria.
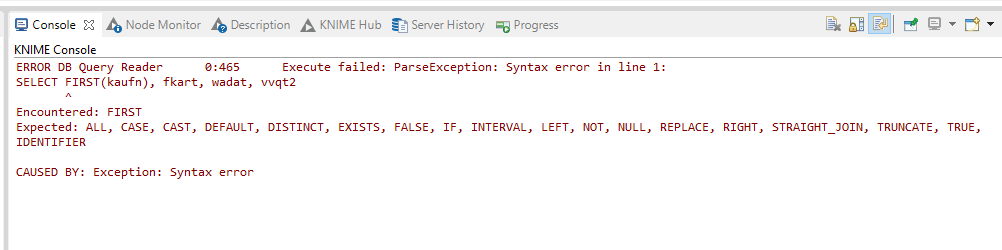
I have tried using FIRST and TOP 1 in custom aggregation in DB query. I have tried DISTINCT ON within DB Query, but all seems to be not supported. How I can get use FIRST in my data?
It also seems to not recognize FIRST function. I would also like to stay within DB tools, and DB QUERY READER takes the operation outside Impala I am working in.
Hi @Piotr_S,
as far as you didn’t stated which database you use the solution could be different.
If you are connected to an oracle database, then read this description FIRST_VALUE (oracle.com).
Thank you morpheus. With you advice i was able to come up with syntax below. As far as I know I am working with Apache Impala.
SELECT `sales_order`,
FIRST_VALUE (billing_type) OVER (partition by sales_order order by `vol_sold_sku_qty` DESC) as billing_type,
FIRST_VALUE (delivery_date) OVER (partition by sales_order order by `vol_sold_sku_qty` DESC) as delivery_date
FROM table