Dear Knimers,
Hi (again). I have a problem configuring my workflow on the GroupBy node.
I got:
a) I have a [CSV file] with Covid data preprocessed in Knime, with a list of about 1.325.000 cases. The link to this file (from my Google Drive) is here below:
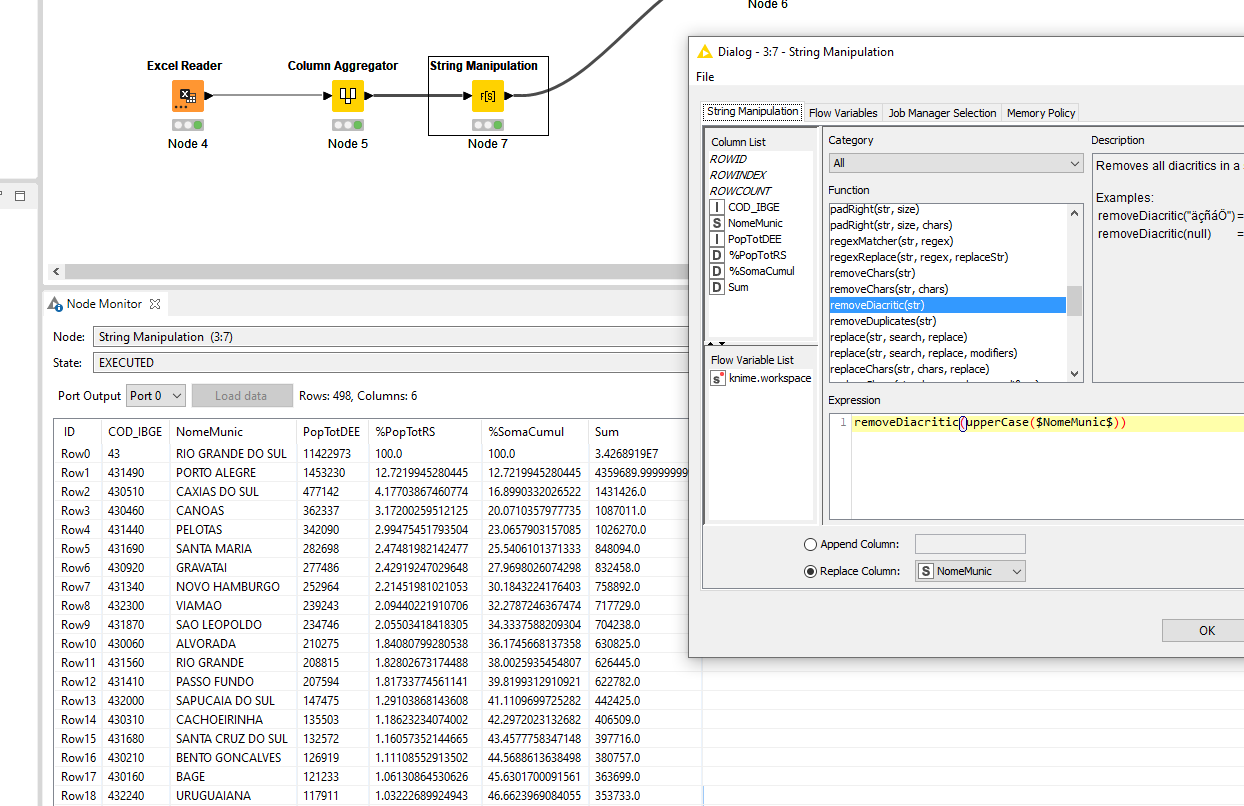
Each case has one column for the city name and another for its “RegionCovid” (an official name for the regionalization (grouping) of the cities and their Covid cases distribution), amongst several other columns. These cases are to be joined by the municipality per every month (“Munic-yyyy/MM”) and by “RegionCovid”, also joined by the city per every month.
b) I have downloaded another file, an XLSX one, with the population for every city in our State:
recalc-DEE-RS_populacao-byPopTot-municipio-sexo-fx-etaria-2020.xlsx (148.6 KB)
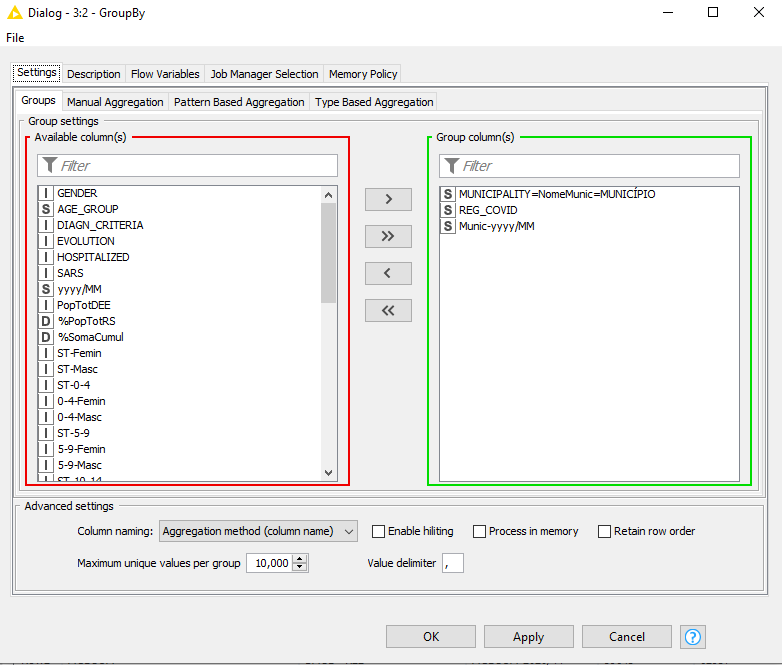
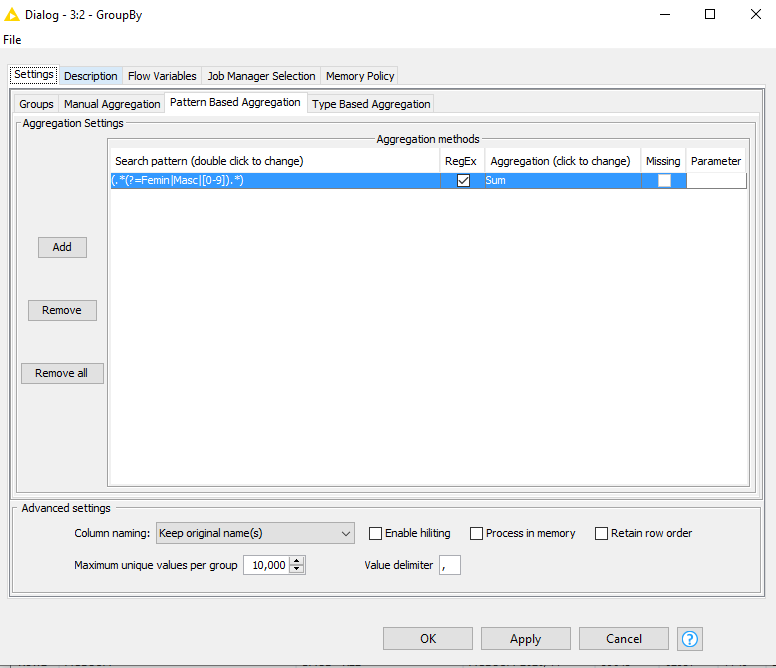
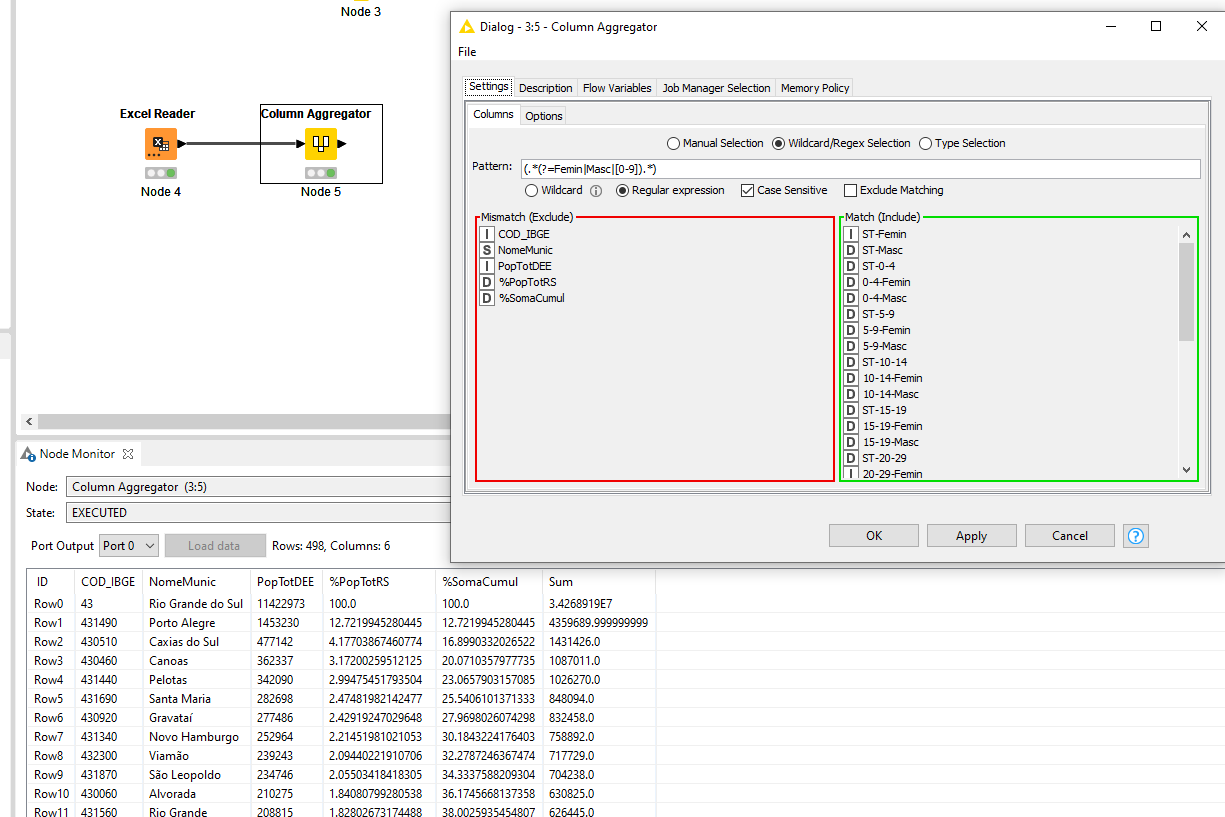
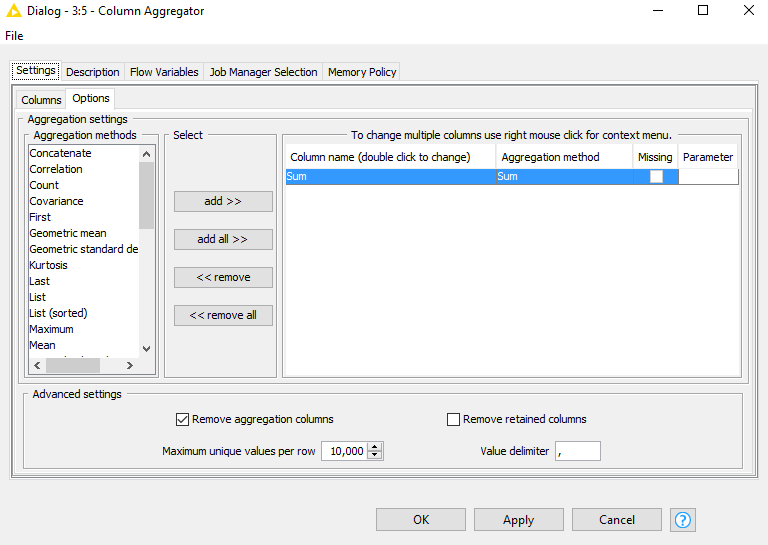
c) Next, I need to group the number of cases, hospitalizations, and deaths by “RegionCovid”, and calculate their respective rates. I have already calculated (in Knime) the rates for every city. But I didn’t get to group cases and populations by Region, in order to calculate their respective rates because I don’t get to gather the sum of inhabitants per “RegionCovid”. I tried several configurations, most of the “Manual Aggregations”, but Knime simply sums their subtotals by month, which renders me an enormous (and worse, artificial and wrong) number for its subtotal.
Would someone lend me a hand on that?
Thanks for any help.
B.r.,
Rogério.