I have a problem and maybe you can give me some tipps to solve it.
I have 7 columns A, B, C, D, E, F and an Cluster.
The cluster is always present, but in the other columns there are a lot of missing values.
What I want to know is which combination of columns (so no Missing values) is primarily represented for each cluster. Extra points when I get and actual number or the 3 beste combinations that are primarily filled.
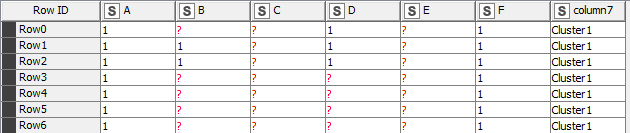
To make an example
Here the primarily combination would be A, F and this combination represents 100% of the rows in the cluster_1
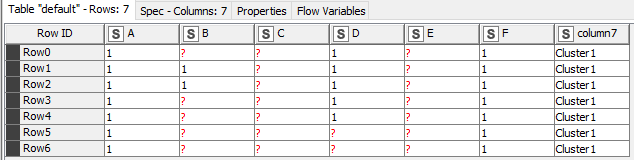
If we adjust the example
the primarily combination would be A, D, F and this combination represents 57% of the rows in the cluster_1
I´m currently working with 2 million rows but this is and one time thing, so performance is not that big of an issue, but it shouldn’t take days…
Hello @goodvirus
I’m just guessing but, aiming to keep it simple as an approach…
What about duplicate Cluster’s column and use a ‘Group by’ grouping by all Available Columns, and $Unique count(duplicate_cluster)$ as aggregation.
Then you can calculate the combination percentage per cluster; then ‘Top k Selector’ and so on…
I hope this brainstorming can help in your challenge.
BR