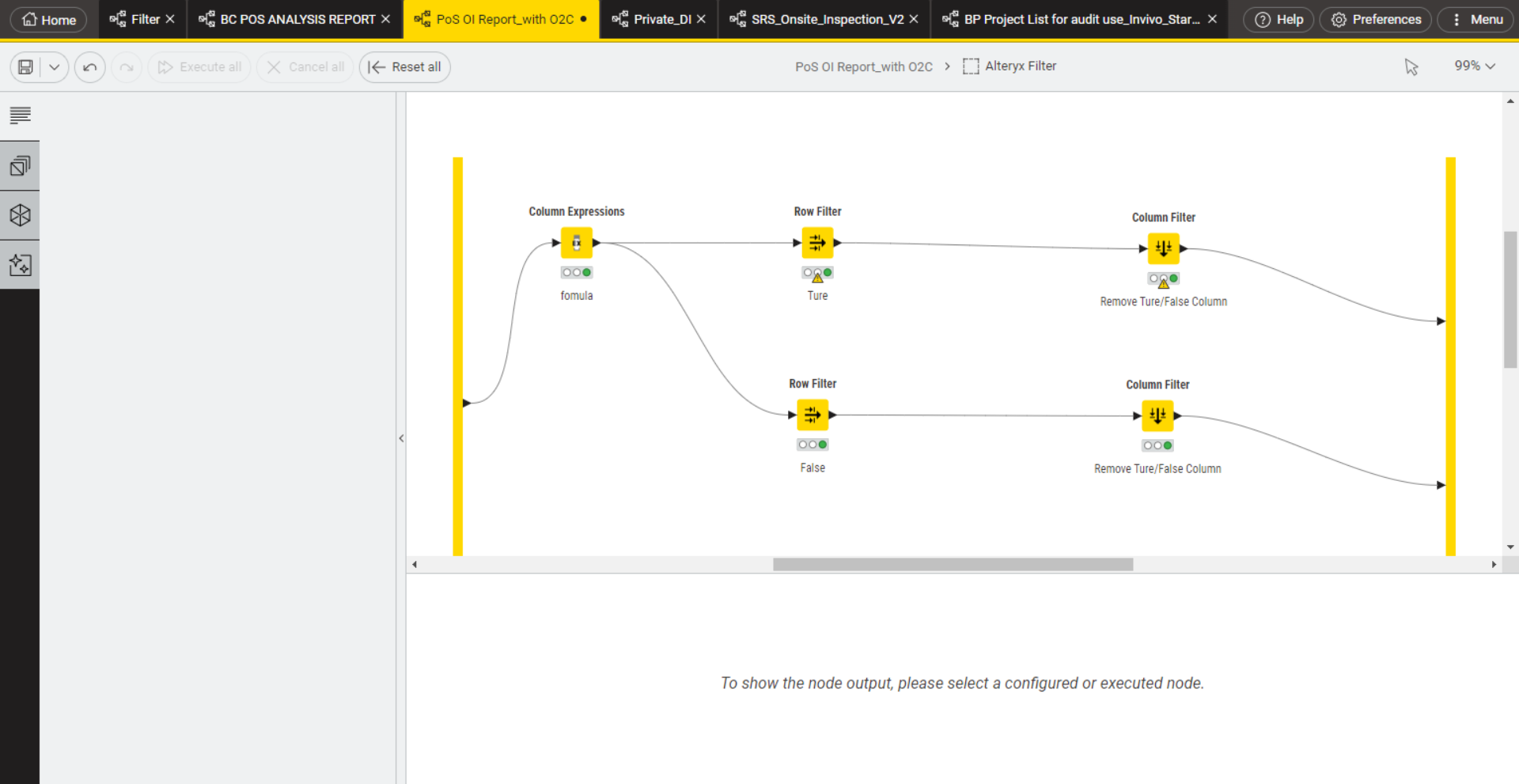
Can anyone help me convert the following node (Filter in Alteryx) from Alteryx to KNIME to give the same output?
I’m using KNIME 5.2.5. I tried to use column expression, row filter and column filter to filter, but the result is not correct.
Can anyone help me convert the following node (Filter in Alteryx) from Alteryx to KNIME to give the same output?
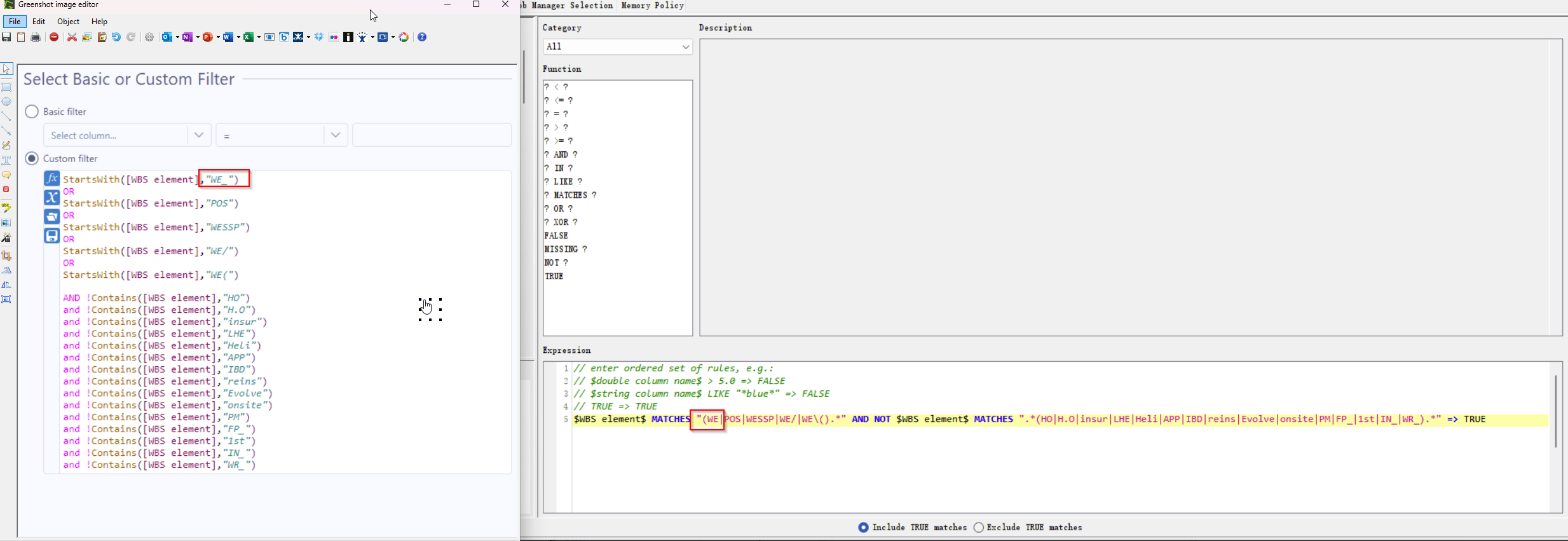
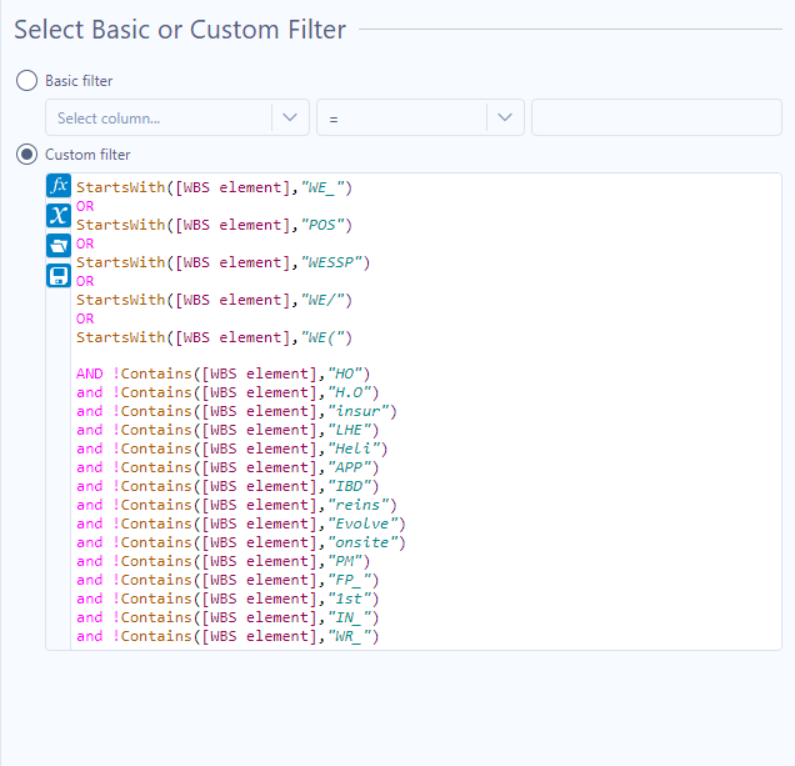
As the WBS naming etc. looks very familiar ( ![]() ):
):
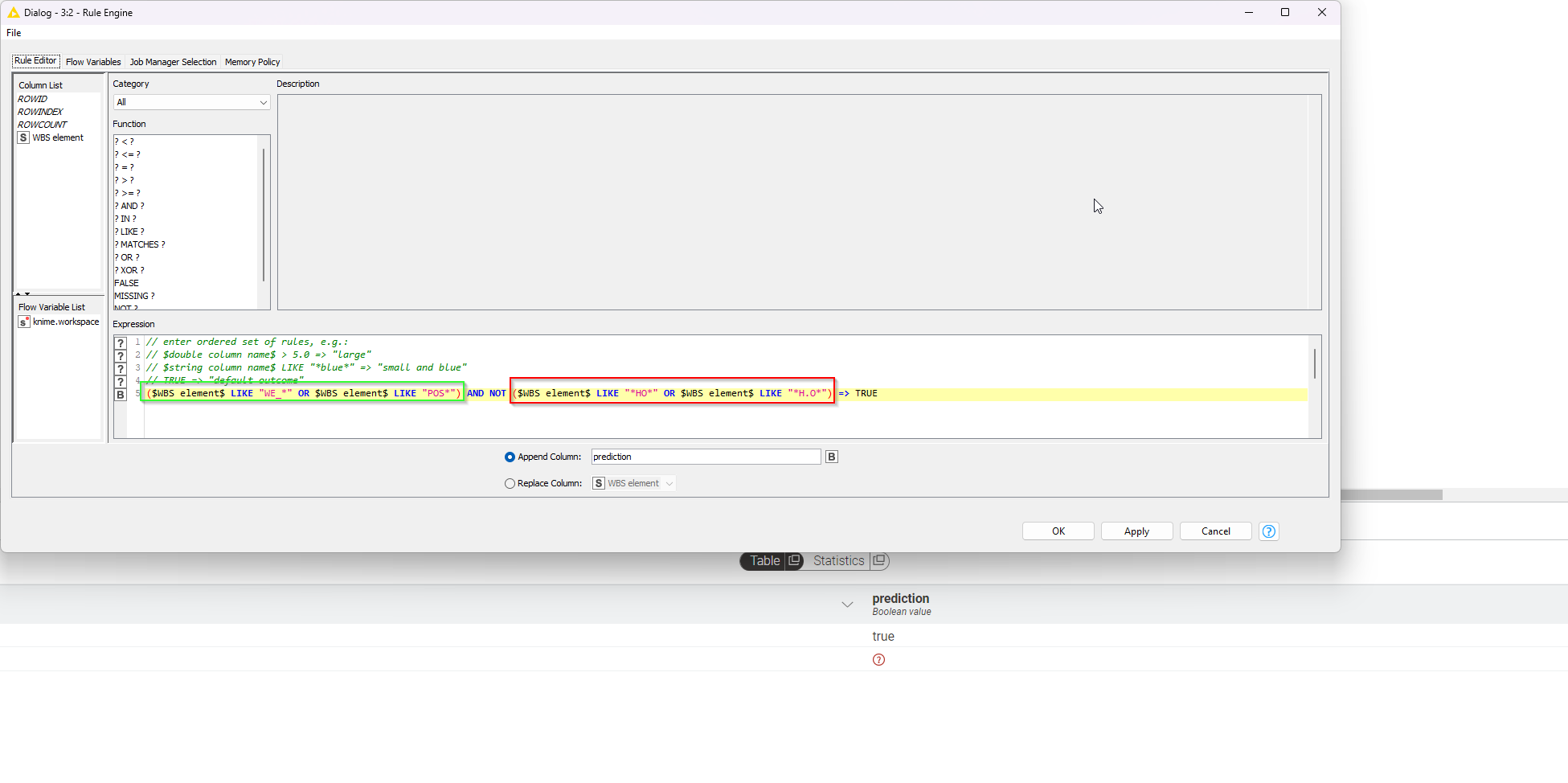
You can also solve this using normal rule engine - here’s and example on how to implement the first part (WBS starts with) and the second part (does not contain):
You can chain the additional “starts with” conditions in the green box and the additional “does not contain” conditions in the red box.
I take that you want the rules to cumulatively apply to each row…
Import: For “starts with” use LIKE with an asterisk only at the end, for “does not contain” also use LIKE but with asterisk at beginning and end of the search string.
Example WF:
FilterWBS.knwf (75.1 KB)
Hi @ThomasChen,
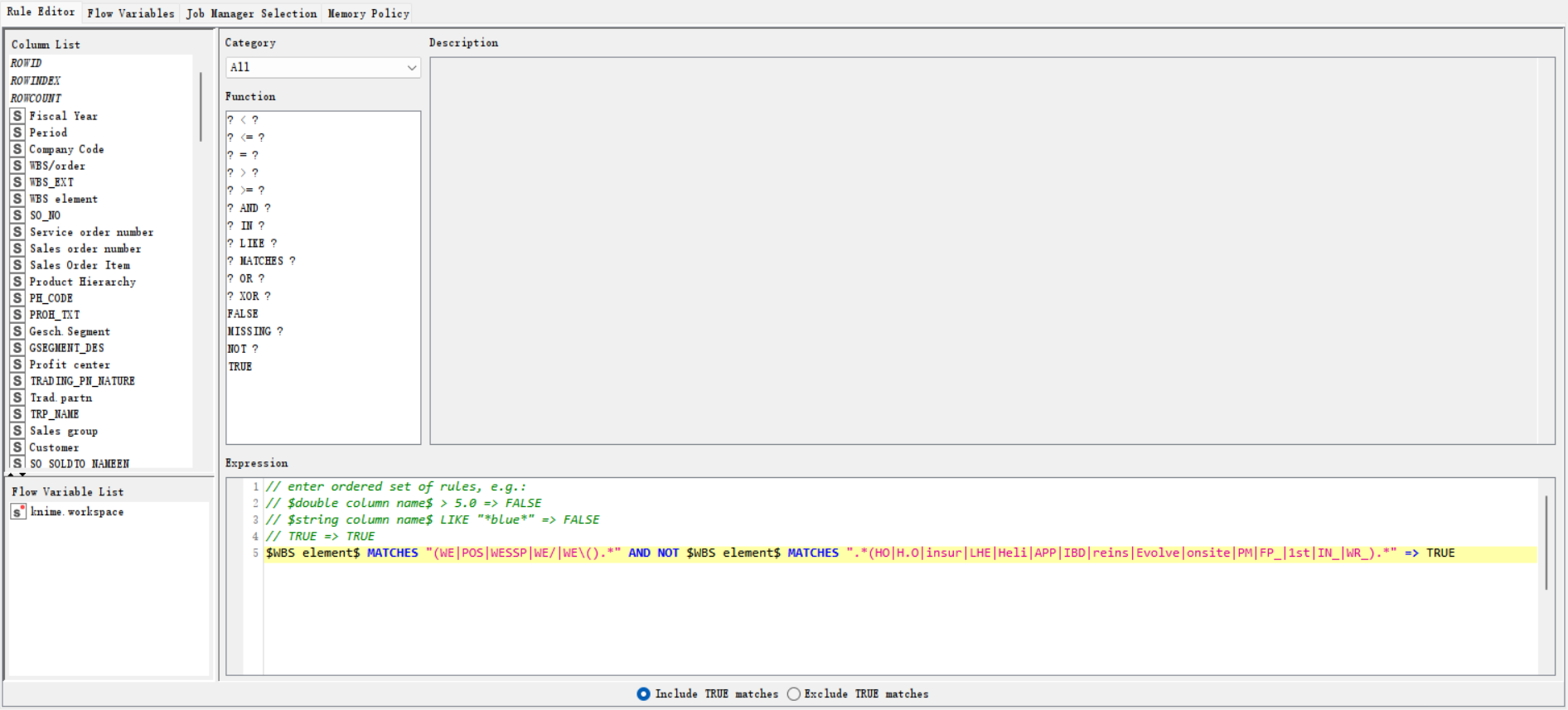
In additon to the already suggested solutions I would like to suggest using an expression like this (I didn’t add all your terms):
$WBS element$ MATCHES "(WE_|POS|WESSP|WE/|WE\().*" AND NOT $WBS element$ MATCHES ".*(HO|H\.O|insur|LHE).*" => TRUE
in the Rule-based Row Filter node where you can include or exclude matches.
Hi Armin, I have tried you solution, but it does not have the same result in Alteryx. The result in KNIME is 56325 rows while the result in Alteryx is 57696 rows. Do you know why? Thanks!
Hi,
And MATCHES uses regex so “.” must be escape I think :
But the two corrections should decrease Knime number of responses. I don’t know Alterix and the booleans rules but the custom filter seems to say : all wbs (begining with we_ or pos or wessp or we/) or (begin with we( and not contains ho h.o etc). The Knime rule says : (begin with we_ … we() and (not contains ho h.o etc ) wich is different.
Best,
Joel
You’re right, but the result changed to 56321 rows, still different from the alteryx.
My understanding (by looking at your conditions) is that you want to filter values which start with ANY of the provided “Startswith” terms AND contain NONE of the “!Contains” terms. Is that correct?
Is it possible for you to check the difference between the two tables and provide us with a few example values which appear in the Altryx output but not in the KNIME output?
I bet that
$WBS element$ MATCHES "WE_.*" OR $WBS element$ MATCHES "POS.*" OR $WBS element$ MATCHES "WESSP.*" OR $WBS element$ MATCHES "WE/.*" OR ($WBS element$ MATCHES "WE\).*" AND NOT $WBS element$ MATCHES ".*(HO|H\.O|insur|LHE).*") => TRUE
will give 57696 rows ![]()
Joel
Hi Joel,
Your code gives result 58036 rows, which is the result does not consider “!contains” part. When I delete the “!contains” part in Alteryx, I got the result 58036 rows.
Hello,
So have you find a solution ?
Best,
Joel
Hi Joel,
I have tried your solution “$WBS element$ MATCHES “WE_." OR $WBS element$ MATCHES "POS.” OR $WBS element$ MATCHES “WESSP." OR $WBS element$ MATCHES "WE/.” OR ($WBS element$ MATCHES “WE)." AND NOT $WBS element$ MATCHES ".(HO|H.O|insur|LHE).*”) => TRUE”, but it’s not correct.
I’m afraid the devils seems to be hidden in the detail.
Can you do the following to, as suggested by @armingrudd , filter for the differences?
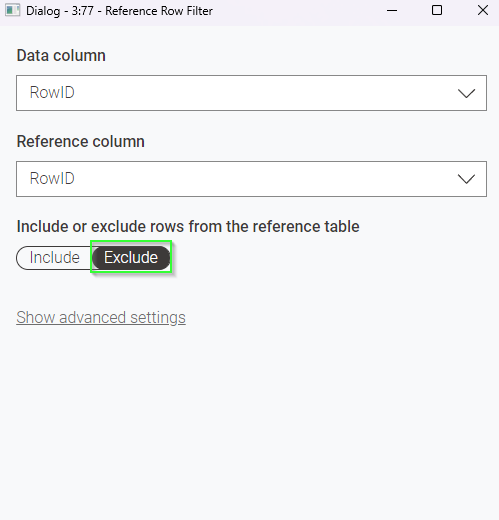
Luckily this is very easy with KNIME using the Reference Row Filter:
If you can share some samples of those WBS elements that are in one but not in the other I think we can investigate further.
Hello !
In the code you post, there are little mistakes : the first . must be quantified with * and the . in H.O must be escaped ie matches .*(HO|H\.O etc).* And you have to add the other !Contains elements ie insur, LHE, Heli etc.
What about the @armingrudd’s question ? “My understanding (by looking at your conditions) is that you want to filter values which start with ANY of the provided “Startswith” terms AND contain NONE of the “!Contains” terms. Is that correct?”
The results are differents but which one is the correct result ? There is no “(…)” in the Alteryx formulation for the booleans priorisation and that could be a source of ambiguity.
The analysis suggested by @armingrudd and @MartinDDDD would be very useful.
Best,
Joel