Hello dear KNIMEler´s (is this an official term?),
I need your help/feedback/ideads about an approach I´m trying out and am a little bit stuck.
The background
Currently I´m working at an energy utility company and we are supplying water, heat, electricity to around 1 million customers. Therefore we are using some big SAP systems (IS-U) with a lot of data (transactions, customer or billing records, base/master data). One major problem is the data quality (as always) in the base/master data (german: Stammdaten), which will lead further down the road to transaction failures, which will have to be resolved (mostly manually). Any atmend to fix these data before the become a problem has failed. There are already several failsafes integrated, but the processes are changing raptly, the system is integrated with a lot of other systems and we are using external workforce for data inputs.
To put it short, “houston we have a problem”.
The biggest problem is, that incorrect data is not discovered right away, but when several processes are already running and using the wrong data. So when we find the false data we have to turn back these processes, which is quite expensive.
The data
As mentioned, we ware mostly working with SAP systems and about 10 TB of tableau data in around 1000 different tables which interconnections (foreign key) between some of them. The good thing is, that I can probably skin the data and tables to around 2 TB and 50 tables of relevant data, but I´m still talking about millions of rows and around 2500 fields (sap likes to make there tables wide…).
The goal
I want to identify false or incomplete data before it becomes a problem.
The idea
To identify the incorrect data I would like to use a multi level anomaly detection.
That means, on the first level I will just use an anomaly detection algorithm to scan one table at a time to detect the outliners. After that I will connect the table to the other tables with some key´s (there are a lot of possible connections) and do the same thing again. After this I will look at both detection levels and make a vote, if it is an anomaly. Also I have to explain “why” this records is an anomaly.
The problem
First I had to select a ml algorithm for the detection. Because I don’t know where the anomalies are, I can’t use an supervised learning approach. Therefore I was looking at my data and because of lot of data is categorical and I wish to explain why the data point is an anomaly I chose an unsupervised learning approach. Because of the high degree of categorically data I had the rule out clustering (eg. DBSCAN) and went with an decision tree approach (Isolation forest).
“Here comes my first question: is isolation forest the right approach?”
I tried it out and some anomalies were detected, but unfortunately also correct examples. These examples all were special constructs (german: Sonderkonstrukte), which are technical correct but really rare. Because I can’t select these beforehand I was thinking about an “active learning” approach. When I got an anomaly detected, a person will look at it and tell if it is one or not. If it is not, we extract the information why it was detected as that and remove it from the pool with all it similars.
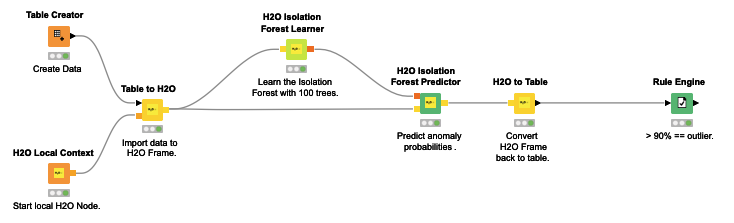
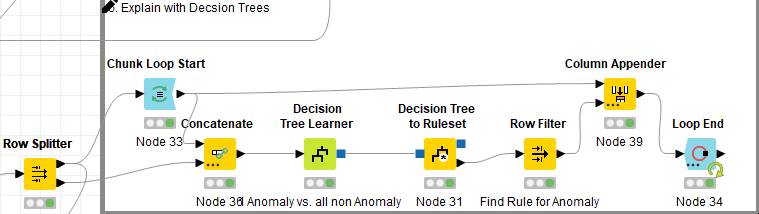
“Here comes my second question: What do you think about this approach and how to I extract the information why it was an anomaly? An isolation forest is basically and ensemble tree approach, so I have maybe hundreds of trees, and they are all voting. Currently I´m using the h2o isolation forest learner/predictor, but I does not give me additional infos or statistics about why it voted that way.”
To put it in a diagramm

Any input or idea is appreciated. Maybe someone has done something simelar?
Thank you all in advance,
Paul