Hi All,
I am reading the data from the source every hour. During every hourly readout I read the data for last 24 hours ( which is minimum for me to analyze the data). I want to store the data in the database after every read out.
So, My problem is, when I am writing the data to the database using DB insert or DB writer, both nodes are duplicating the rows in the database. Which means after every hour, I am duplicating 23 hours of data due to which my database if growing exponentially.
My Question is, how can I just write the new rows every time and to filter the duplicate rows… I tried reading the data back from DB before writing, and then filtering it using row filter before writing back… it worked but this is too much at the edge, if you have any samples missing or extra from any of the table, you will end up with duplicate rows again. I am unable to find, which node writes the data to the database and refuse to write duplicate values. Will appreciate your kind suggestions.
Best Regards
Amir Aslam
One way would be to have a Primary Key in the database that might be composed of a name/id and a timestamp so the DB would not allow any duplicates.
Then at the point where you insert new data, you could check if the ID is already there. An alternative would only be to maybe download the IDs already in the DB and then exclude them from the new lines
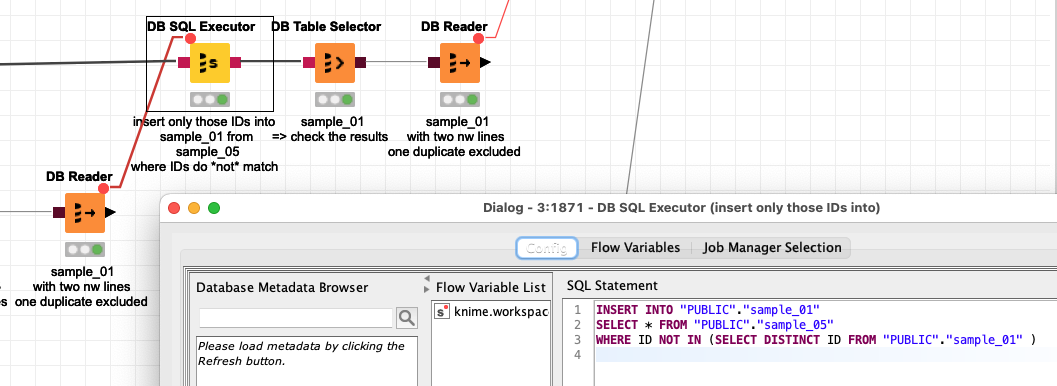
INSERT INTO “PUBLIC”.“sample_01”
SELECT * FROM “PUBLIC”.“sample_05”
WHERE ID NOT IN (SELECT DISTINCT ID FROM “PUBLIC”.“sample_01” )
This command would use some resources but it has the benefit of checking the moment you would want to insert the data into your database.
You could check out this example workflow and play around with the settings and see if they can help you:
Hi @mlauber71, Thanks for the response… I was actually away so couldn`t check.
Downloading the data back is not an option as database size is big and it will be growing over time…so I do not want to read back before writing to optimize performance… I will try and will let you know…
Hello @AmirAslam1986,
I don’t understand why can’t you filter data so only last hour is left before inserting data in database?
Additionally there is feature request for such a functionality and I have given it +1 for you. (Internal reference: AP-15380)
Br,
Ivan
Hi Ivan,
The dataset is not very consistent in terms of number of rows every two hours. If I filter based on the exact time duration, I`ll still have either missing rows or duplicates most of the time. I know its very simple if I read back from the database last two hours of data and then filter the duplicates and write the new rows only but I am trying to avoid an additional step of reading back from the database.
In the example the data is not read back to knime but the IDs are being processed within the database
Hello @AmirAslam1986,
but if data is not consistent don’t think there is way to determine “right” records to insert into table unless you compare it with data you already have somehow…
Br,
Ivan
Hi @ipazin … You are right… I am just stuck because of inconsistency only. I think there is there a SQL Query which checks before writing if the data exist and then write… Can we implement such scenario with SQL Query executor node?
Let me check again… I was thinking the other way… Will check again. . .
Hello @AmirAslam1986,
Don’t think so but @mlauber71’s idea seems one you should give it a try ![]()
Br,
Ivan
This topic was automatically closed 182 days after the last reply. New replies are no longer allowed.