I have two files I want to append them into one single table.
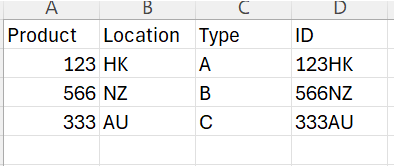
file 1:
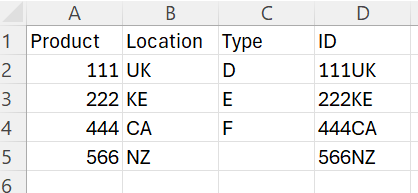
file 2:
As you see, the ID for both files are Product + Location to check if any “Product + Location” has duplicates.
If any ID is already in Table 1, I do not want to append from table 2. Hence, I only want ID which is not in Table 1 append from table 2.
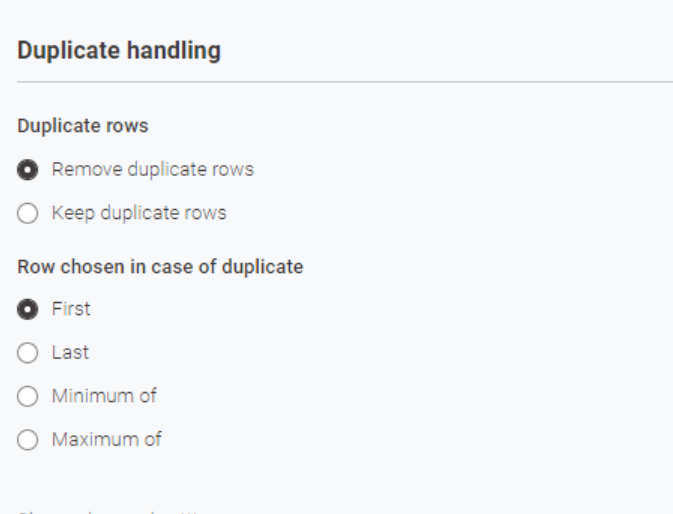
If I use “Duplicate Row Filter” with “First” in row chosen in case of duplicate…does the first row always comes from Table 1?
If not, what would be the best way to do it?
As I have a huge set of data in both table I don’t want them to be mess up. Thank you so much.
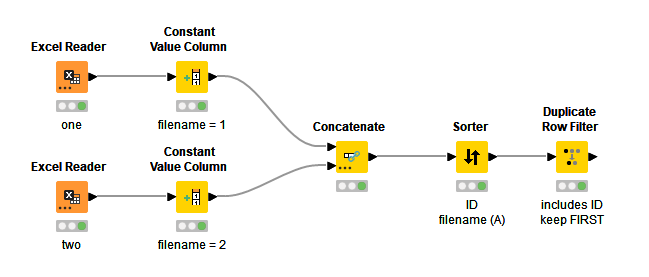
I think your approach is correct. If you really want to be sure to pick the duplicate from table one. Create a column named filename and give it the value 1 for dataset one and value 2 for dataset two. Then after concatenating both tables do a sort on ID and filename.
gr. Hans
Hi @newba , as @HansS says, your solution should work fine. Concatenation stacks the rows of the tables in the order of concatenation, so all the rows from the first table, and then all the rows of the second table,… and so on if there are more tables, so it ought to work exactly as you intend.
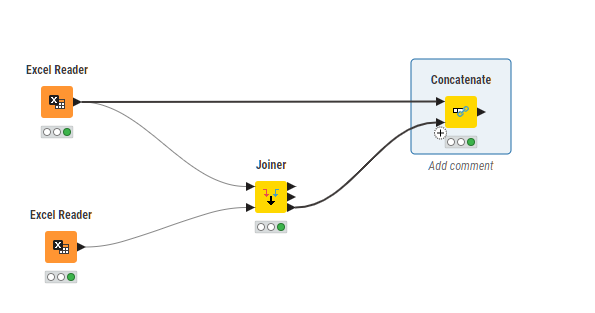
Assuming that duplication will only occur because of the concatenation, and not because you already have duplicates in one or other of the tables, an alternative solution could be to use the Joiner node instead of the duplicate row filter.
Configure the joiner to join using “Product” and “Location”, and set it to “split join results into multiple tables”, and to return “Right unmatched rows”. Then concatenate the first table to the output of the third port on the joiner
Since the third joiner port in this configuration only returns rows from the second table that aren’t present in the first table, the result of the concatenation should be all of the first table, plus additional (non duplicating) rows from the second table.