I wasn’t able to find a way to append data to an already read file.
In my case, I have two (or many) csv files, with the same structure, and I have to process them together. I was searching for something like a “Read File appending to…” node, but I wasn’t able to find it. Any Hint?
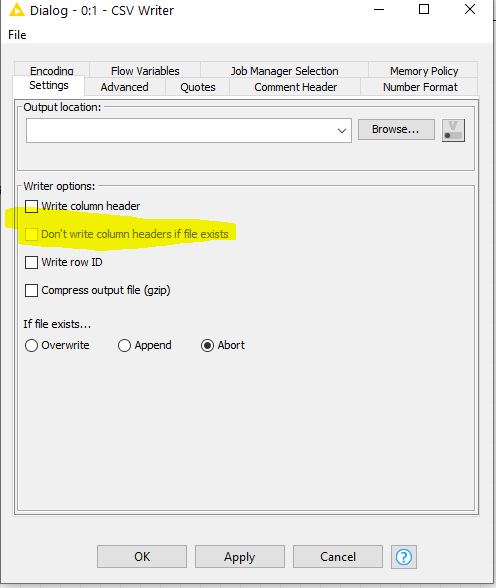
I also tried to process the two files separately (in this case it is possible, but not always), using the csv Writer as output, and configuring the output node for “Append”. The only issue is that in append mode, the node rewrites the header line. I was expecting that the headers are written only as the first line of the output file (if the “append” doesn’t happen, because the file doesn’t exist.
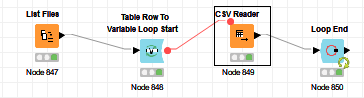
This workflow is on the example server, it might help. Basically you can load as many tables as you want if they’re in the same folder and have the same structure. You’ll want to replace the Excel Reader with the CSV reader or File Reader node.
I think you’ll want to use the Reader, not the Writer. And when you configure it you’ll want to hit the V button beside browse so that the reader reads the location as a variable. So you’re feeding the loop the format of the first sheet and then its treating the location as a variable derived from the list of files you already generated using the List Files node and will loop through all those files you want to combine.
In the Flow Variables tab of the CSV Reader set the url to URL, and then in the settings Tab set the Input Location (as a variable) to url.
Make sure your delimiter is correct; sometimes my files are ; delimited instead of , for instance.
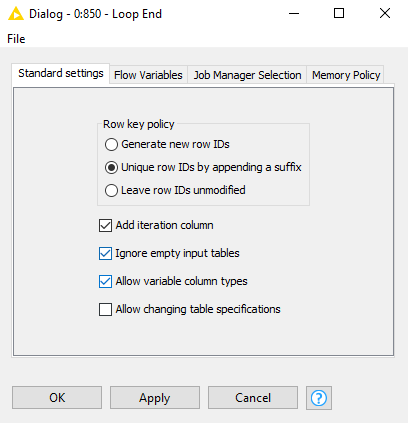
Another common bug here is in the Loop End node, you’ll get an error if some of your tables have purely numbers in a specific column and another data type in the same column in another table, like a mix of text and numbers. You can avoid this by ticking the ‘Allow variable column types’ radio box in the Loop End configuration:
So as long as everything works as advertised it should bring all your csvs together, stacked on top of each other with the columns matched.
I’ts clear. I have started using Knime recently, so I wasn’t aware that the loop was offering the functionality of appending row sets to the result. I think that it’s the right approach, and I will test it.
Yes Iris, I was aware of this, but as I was simply running the workflow twice, for the two input files, this required a change in the configuration (yes at the first run, no at the second) for each run.