I’ve trained a random forest model which I now want to apply to new data.
The model I trained uses one-to-many node on categorical variables. However, my new data set does not include all the variables that the original included. For example, let’s say in the training data I had the following age ranges:
20-30
30-40
40-50
But my new data sample only includes the first 2.
So when I do a one-to-many on the new data, I am missing a column that is included in the original. How do I go about fixing this? Is there a way to automatically add all columns from the trained model even if they don’t exist in my new dataset?
My other issue is, I normalize my quantitative variables for training the data. If I normalize my new data set, the normalized ranges will be different than the ones the model was trained on. Is there a way to normalize my new data according to the ranges the model was trained on?
You need to have the same data sets in the training and deployed models. Remove the data from the training model that doesn’t appear in your new data set.
Hello @Ana_Proskurin , and welcome to the KNIME community.
The new data is correct if you are treating them as qualitative.
I would keep as in the new data; being aware of dummy variable trap: one of the variables must be removed to avoid double imputation. @rfeigel suggested the right approach .
Your training model became multicollinear, then variables were highly correlated; in simple terms one variable was predicted from the others. There’s plenty of literature about this multicollinearity effect.
Thank you, the issue is that it would be hard to predict which categories will be missing in any new given sample - for example, one set could only have 4 out of 6 cities/provinces used in the model training, while another one will be missing an age range.
This wouldn’t be a problem if I wasn’t applying a one-to-many in the model training, but doing so has improved my results significantly.
Is there no way to automatically add the missing categories as 0 for all into the new data set?
Could you explain in some detail the data elements in your model and what the model is intended to do? If the data isn’t proprietary can you share the model?
Basically, it’s a model that looks at costumer demographics and summarized behavior to predict a binary classification - sort of like ‘will churn’ yes/no, the data is proprietary so unfortunately I can’t share the model or go into too much detail.
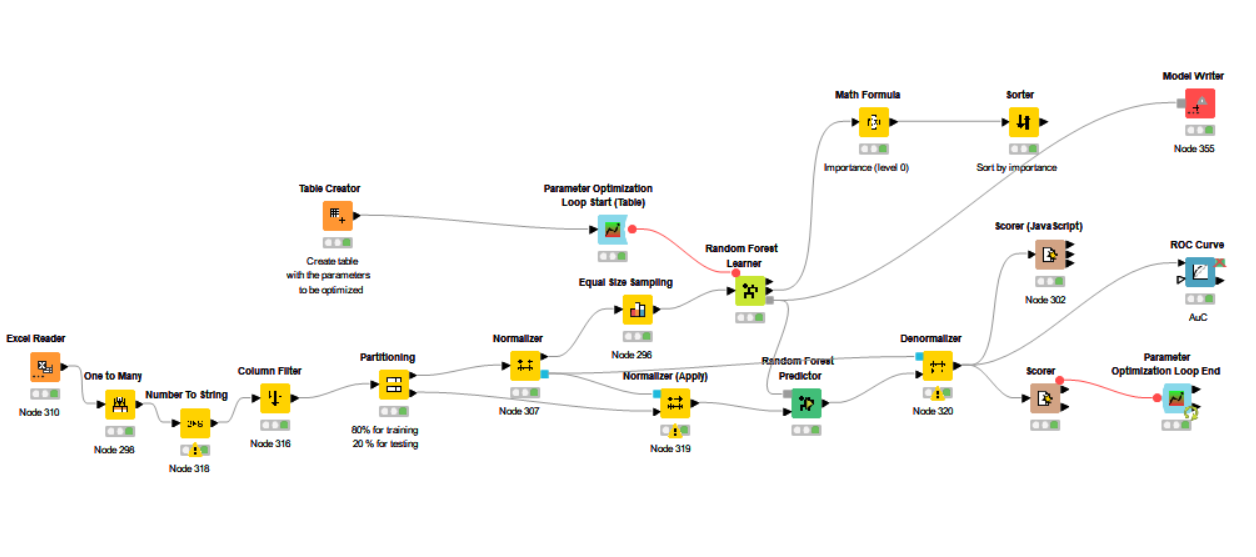
I’ve added a screenshot of my workflow below:
The one to many node is used on my categorical data (things like gender, city, age range etc.). The quantitative information is normalized using min-max. I’m using equal size sampling due to huge class imbalance in my prediction class.
Hello @Ana_Proskurin
Just a few observations about your current methodology:
Random Forest Learner doesn’t need a previous data encoding. As this node takes cares of all the data preprocessing. Can you do it? Yes. And it shouldn’t affect your Scorer Results as a QC, if the preprocessing is the right one. Challenge 23 - Modeling Churn Predictions - Solution – KNIME Community Hub
Then your model can be much more simple, as it is in this provided example.
One to many encoding to create dummy variables it isn’t jus correct. Because you create a multicollinearity effect; and as a result your prediction model underperforms. So you are applying a not needed preprocessing that is downgrading your predictive model.
Multicollinear models work but trend to capture the noise of the training dataset, represented as overfitting. This reduces the variance in the prediction, and performance is penalized by down ranking in the scorer.
I would try to feed the model with raw data.
I have this example on how you can deal with dummy variables. You can play around with this data and feed a model with and without (raw) preprocessing, even including the Normalizer. The result predicting $HeartDisease$ will rate very similar; because the learner doesn’t need it.
Then try to compare model performance with one to many encoding…
You can connect this component to your own data and compare the performance, versus your current preprocessing.
I think what happened is that the one-to-many improved the performance significantly when I was still using logistic regression to train the model, and ended up just keeping it when I switched to random forest thinking it was necessary for performance.