Hi, I am new to KNIME and has found this software very impressive!
I want to do some text mining work with KNIME and watching this official tutorial: - YouTube
But I notice that if I want to mine Chinese text, I have to segment the sentences first. Unlike English, Chinese sentences aren’t separated by space.
I know that there’re many other tools can do the segment job, such as the Stanford parser. But are there any extensions of KNIME can handle this? or how can I handle this job using other tools and still combine with
KNIME workflow?
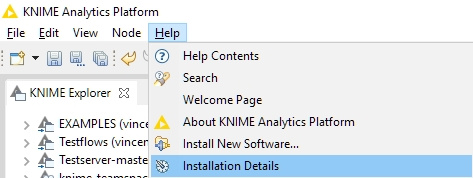
Last question, how can I find out what nodes exactly being installed when I am installing a KNIME extensions?
With the Text mining extension, KNIME Analytics Platform provides the Tika Language Detector to detect the language of a given String/Document value. The detected language will be appended to the input table as a new column. From there you can process the documents based on the language.
You can also visualize all the detected languages in one single document. Then, you would need to ungroup the collection created for the column Language.
Does it help?
To find out all the software that have been installed, you can go to Help and then click on Installation Details. The first tab _Installed Software_shows all the software installed in KNIME Analytics Platform.
Thanks for your help, but I don’t think Tika can handle this job.
To my knowledge, Tika is used to parse files with various file types, but not for separating words.
My problem is, for example there’s a Chinese sentence below:
今天天气很好
I want to separate the sentence into words:
今天 天气 很 好
Anyway, thank you!
there is a Chinese Tokenizer available within the “KNIME Textprocessing Chinese Language Pack”. This pack can be installed via: File -> Install KNIME Extensions… -> Expand KNIME & Extensions -> Select KNIME Textprocessing Chinese Language Pack -> Finish.
After the installation, you can use the Strings to Document node. You can select the Chinese Tokenizer within the node dialog. Afterwards, you can use the Bag of Words node to list the occurring terms.
Unfortunately, there aren’t any further tools for Chinese Language, but we plan to integrate models for part-of-speech tagging and named entity recognition soon.