maybe someone can help me with my problem. I have used the Clustering workflow that you can find here (pattern analysis) to solve the problem regarding typos in company names. In the original Excel sheet there are more information (Columns) like Product, Amount, Currency, country etc and not just the company name as a column. With the help of the workflow I was able to assign misspelled names to a cluster. Because you can only work with one column for certain nodes, I no longer have the corresponding columns that I would like to reconnect. For example, if we have assigned the company name to a cluster here, then it should also use the parent name of the cluster for further processing purposes. For example, if we had the following constellation before:
Company Name, Counterparty, Port of origin, Port of destination
Siemens AG, Altanz GmbH, Germany, Netherlands
SIEmens AG, Altanz GmbH, Germany, Netherlands
Simmens ag, Altant GmbH, Germany, Netherlands
After the workflow used in pattern analysis the following should be created:
|Company name|Counterparty|Port of origin|Port of destination|
|Siemens AG|Altanz GmbH|Germany|Netherlands|
|Siemens AG|Altanz GmbH|Germany|Netherlands|
|Siemens AG|Altanz GmbH|Germany|Netherlands|
And with the help of this schema I would like to continue working.
Is there a possibility to do this here?
if I understand your request correctly, you want to join information from earlier in the workflow to transformed information later in the workflow, right? Just to make sure: did you know that one can not only perform joins on data in columns, but also on row ids? If your RowIDs have not been altered, you can just use those…
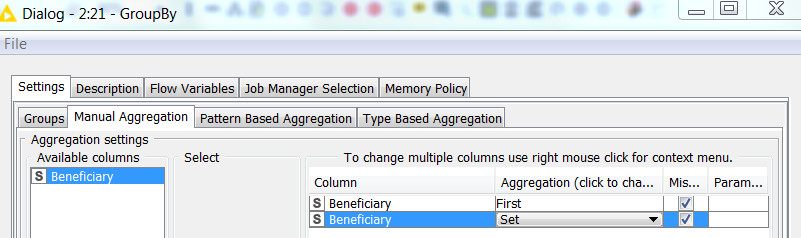
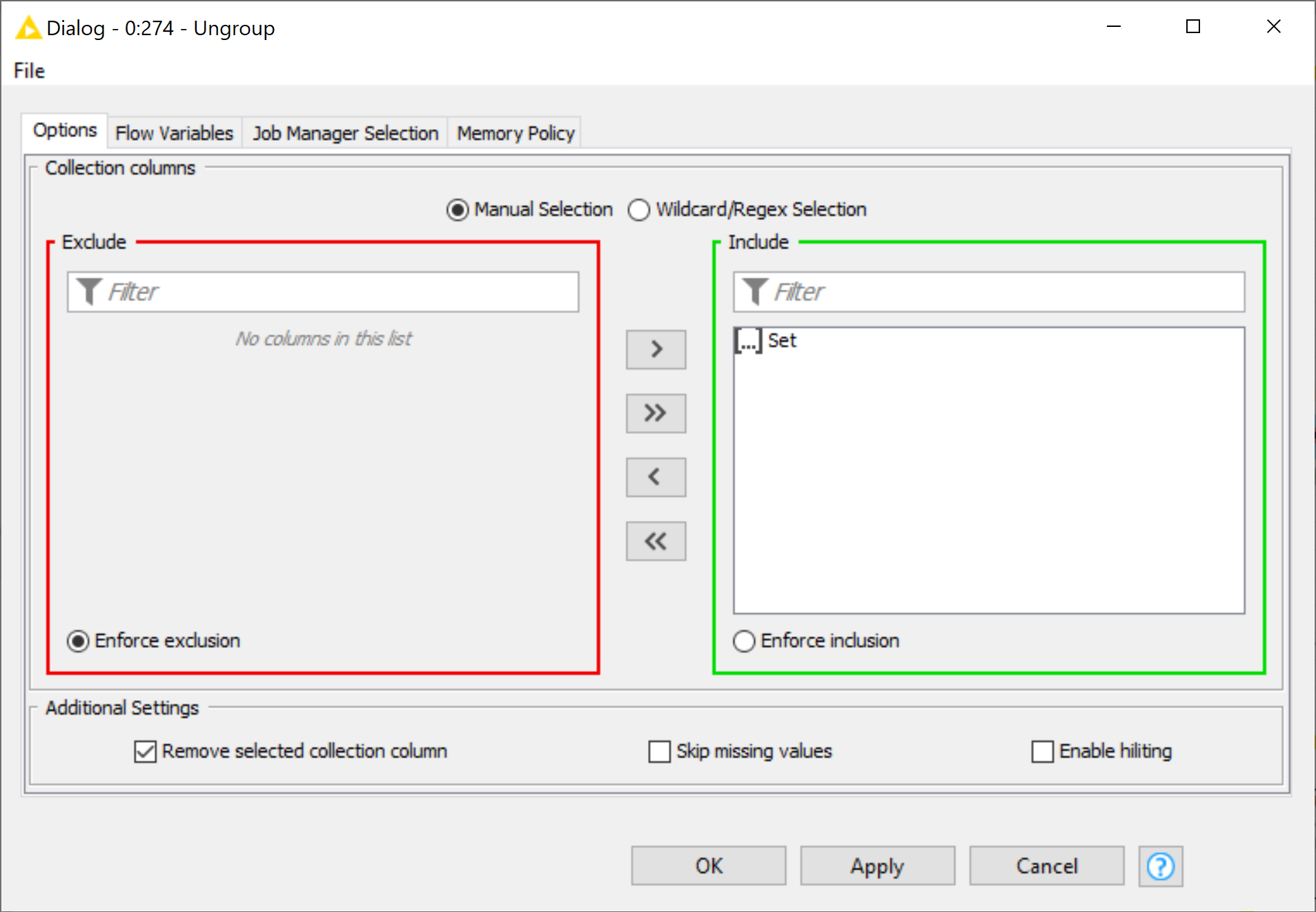
as I understand it, all you need to do is to add in your GroupBy node the Beneficiary as a Set or as Unique Concatenate. Then the information will not be lost and when your loop ends, you can expand your set (Ungroup node if you had the Set, Cell Splitter and Unpivot if you used the Unique Concatenate Method) and join the information back to the data.
Hi @anon33357744, glad to see work is moving forward!
The reason you can’t use the Beneficiary column twice in your group by is because we had set it to use the original column name.
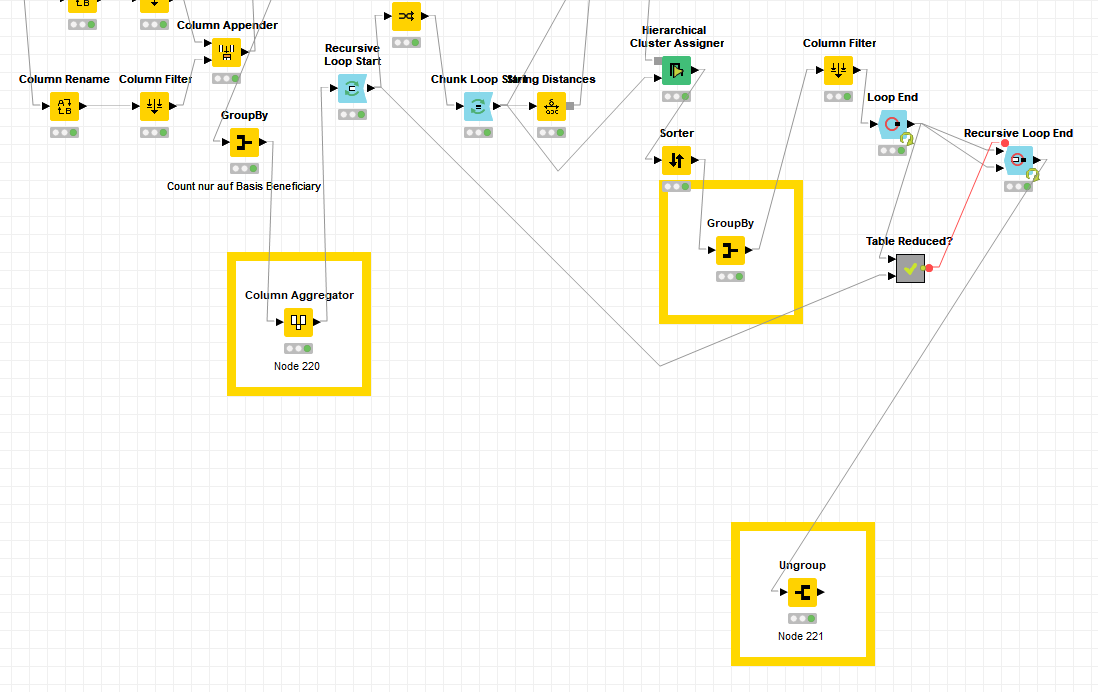
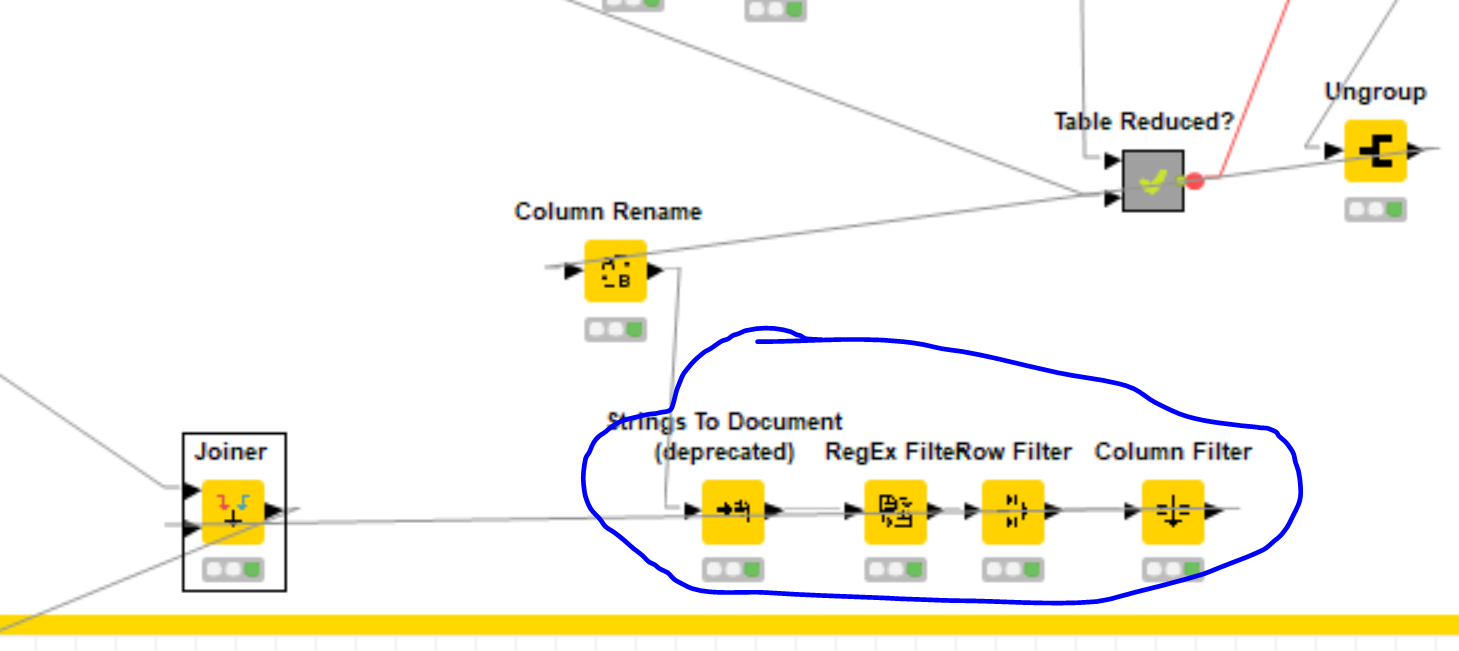
A way around this that stays consistent inside the recursive loop is to add a column aggregator node before the looping begins to create a new column that is the set @Alec mentioned. Then we can modify our group by inside the loop to union those sets when we combine the clusters.
Then after everything you can use the ungroup node to get a table you can join back to your original with to correct the names without losing all your other columns.
I put boxes around the changed nodes in your workflow. Hope this helps!
I hope your trip was nice.
I think that doesnt solve my problem.
the loop process creates new Row IDs, this means i cant use row id as an identifier, because to join data i Need this. After using the hierarchical cluster model I want the correctly written names to be reassigned to the data or columns. I just wanted to use the hierarchical cluster model to assign very similar misspelled names to a particular name, the one that occurs most often. after that I wanted to reassign or reassign the correctly spelled names (Beneficiary) with applicant, port of Destination and transactionid.
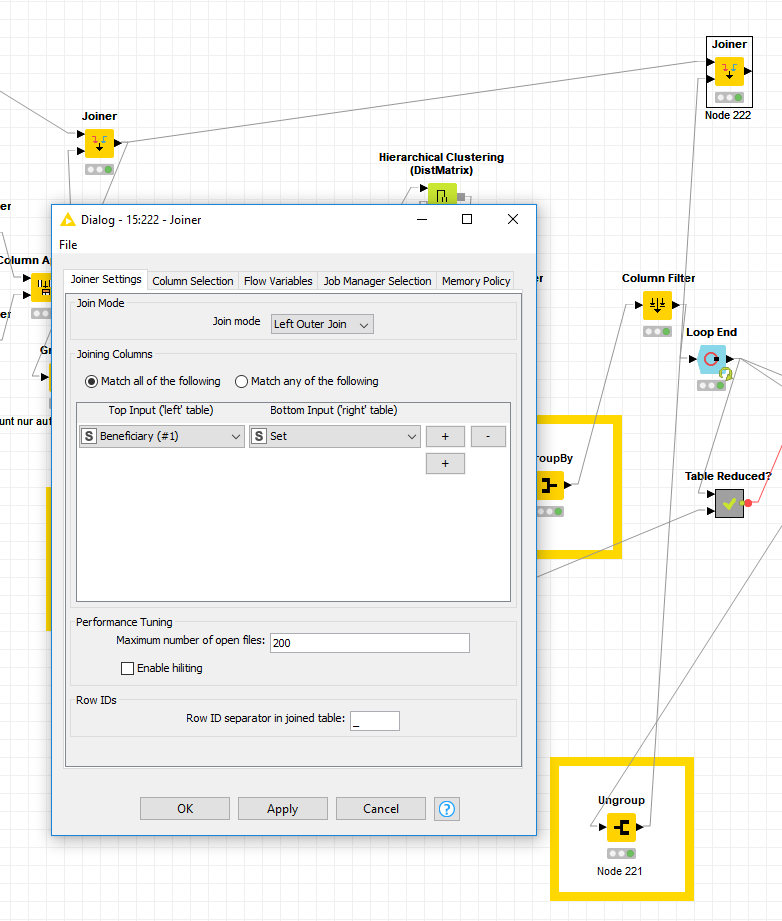
i don’t know how i can link this to the data in the joiner now. This is supposed to make a difference, namely that the names that were misspelled now have the correct name or at least the name that occurred most frequently.
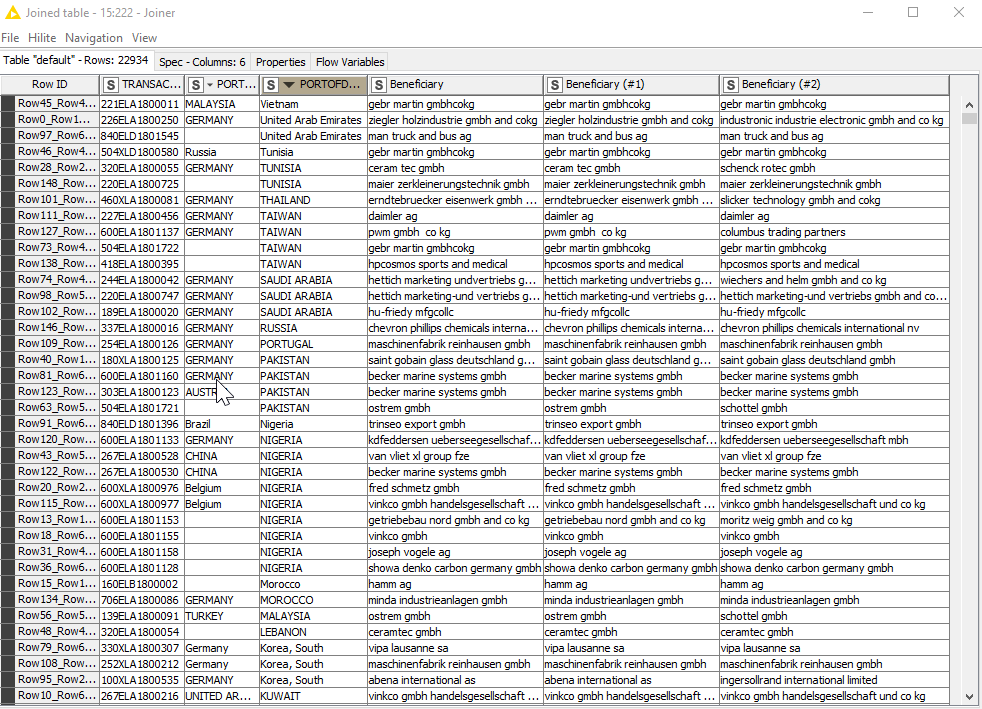
yes this is exactly what i was searching for, thank you so so much, but here i get double rows and the type of set is a question mark, thats the reason why i cant connect it with the joiner.
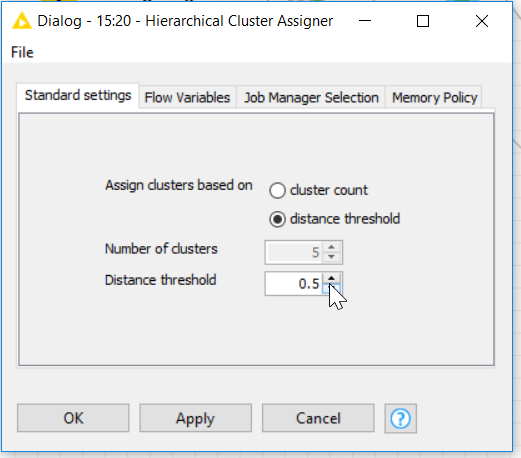
You may want to try playing with the distance threshhold in the hierarchical clustering node. This determines how closely related values need to be to be joined into a cluster.