Hi,
I am a very biginner with Knime (with poor english language !). I search solution for a (perhaps) basic problem. On one hand I have a collection of books, each one described especially by a call unumber, a localization and a library. The call number are unique for a book and are string (e.g. 123.456 ABC). Localization and library are unique and string.
Example :
id title call_number localization library
id_book1 title1 123.456 ABC SL1 SJA
id_book2 title2 789.123 EFG SL2 LASH
On the other hand, i have definitions of ‘categories’ which looks like :
id rule localization library name
id_category1 1|3|5 SL1 category1
id_category2 7|5 LASH category2
with the following meaning for each row (exemple with the first one) : if the call number of a book begin with 1 or 3 or 5 and localization is SL1 then it will be assigned with the category1 (e.g. I want append the data books with a new column containing a set of categories for further analytics). By the way the categories are a herarchical tree… but this is the nexte step.
I tried several things, trying to transform the table of categories into a new table with one definition per row and geneate the rule to be used in rule-based row filter (dictonary) but nether manage to do this.
Have you any useful suggestion to deal with this problem ?
Best regards,
Joël
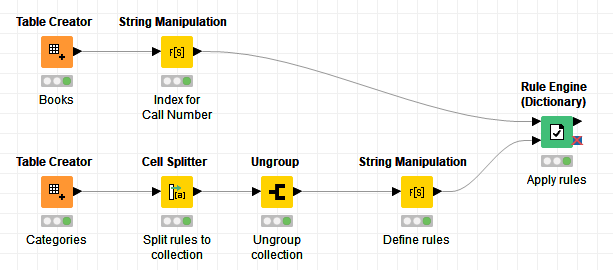
Sorry for the delayed response. This problem is a bit more complicated than it seems at first. I think you were on the right track with your idea about transforming your second table into a set of rules - here’s how I implemented that.
There’s a bit of join syntax to deal with in the String Manipulation node that defines the rules. Take a look inside the configurations of each node to see the approach in more detail.
Hi ScottF !
Thanks for the hint, it will be very usefull. I try to manage collection set but miss the ungroup node : lot to be learned for a beginner.
By the way I have an another question (perhaps it’s better to make an another post ?) : when using Regex split, some rows don’t have the pattern for one capturing group. The result seem to be an ‘empty’ cell but I’m unable to filter these rows. It’s not missing value nor “” nor " ".
Example : regex split ([A-Z]) (\d)(.*) for capturing the first numerical sequence after a space. It works for eg PR 123 abc and produces the three expected columns but the ‘nothing’ appears in the second column for PR abc. ‘Nothing’ ? I don’t think so but what is it ?
Best regard !
You can forget the question ! I use string to number node and the ‘nothing’ becomes missing value so I can filter on it.
Anyway… this is a trick : what is the content of a cell corresponding to a capturing group if the pattern doesn’t match ?