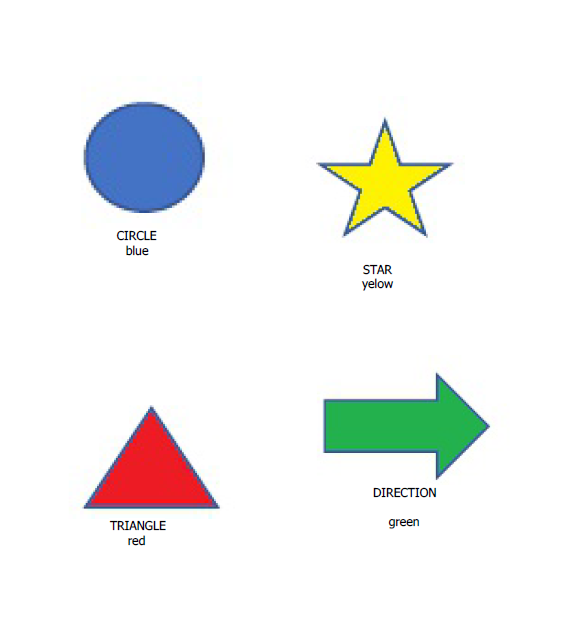
I have a PDF file from which I have to extract the images and text and associate the text with the corresponding image. I try with Tika parser but I don’t know how to link images with text (one column images the second column text under the image). As I can not upload the PDF file I share the image of how PDF looks like. The PDF already has the text layer.
The second approach I have tried is to take a screenshot of the image and the text together and then do the image OCR. This is working but the original PDF has more then 2.000 images with text so I have to do 2.000 screenshots manually.
The key here may be the splitter node depending on your data.
Once you’ve segmented the images, then you can apply OCR and have the rows align with the image. I don’t recommend you do it manually, but hopefully the videos will teach you a more programmatic way to do so.
If not, you may require a neural network to learn (again at 0:45 conincidentally) from your examples and then segment in order to do your matching. Hope that helps.
@andrejz you might want to add more details and offer a real sample of your data. I tried a few things and there are some results but it will very much depend on the real structure of your data / PDF how this will handle the file.
This is the call where the Jupyter Notebook assumes you have the PDF in the same folder:
This is the code that worked on my Mac - to some extent
def extract_images_and_descriptions(pdf_path):
# Set up Tesseract configuration
pytesseract.pytesseract.tesseract_cmd = 'tesseract' # Or your Tesseract executable path
# Create a new Excel workbook and add a worksheet
wb = Workbook()
ws = wb.active
ws.append(['PDF Name', 'Page', 'Image Name', 'Description'])
# Extract the PDF file name without extension
pdf_name = os.path.splitext(os.path.basename(pdf_path))[0]
# Convert the PDF to images (one per page)
images = convert_from_path(pdf_path)
# Iterate over the images and extract the descriptions
for i, img in enumerate(images, start=1):
# Save the image as PNG
img_name = f'{pdf_name}_image_{i}.png'
img.save(img_name, 'PNG')
# Extract text from the image
text = pytesseract.image_to_string(img)
# Extract the description (assuming the text below the image is the description)
description = re.sub(r'\n+', '\n', text.strip()).split('\n')[-1]
# Write the extracted data to the Excel sheet
ws.append([pdf_name, i, img_name, description])
# Save the Excel file with the PDF name
wb.save(f'{pdf_name}_image_descriptions.xlsx')
These are the imports and the things you might have to install
import os
import re
from pdf2image import convert_from_path
import PyPDF2
import pytesseract
from openpyxl import Workbook
And since this is (still) an KNIME forum I have put all this in a KNIME workflow. This can then be used to build a loop or something.
@victor_palacios and @mlauber71 thank you for your advices I will try with your suggestions. In the meantime here is the link to the PDF file on google drive
is not the original but the structure is the same.